处理无限滚动页面
许多网站已经用无限滚动机制取代了 “上一页/下一页” 分页按钮。 这些网站使用此技术在用户到达页面底部时加载更多数据。 因此,通过 “下一页” 链接进行爬行的策略会失效。
虽然这似乎是使用浏览器自动化来模拟滚动的情况,但实际上很容易找出网页的 Ajax 请求并使用这些请求而不是实际页面进行爬行。 让我们以 spidyquotes.herokuapp.com/scroll 为例。
准备工作
在浏览器中打开 http://spidyquotes.herokuapp.com/ 滚动。当您滚动到页面底部时,此页面将加载附加内容:
页面打开后,进入开发人员工具并选择网络面板。 然后,滚动到页面底部。 您将在网络面板中看到新内容:
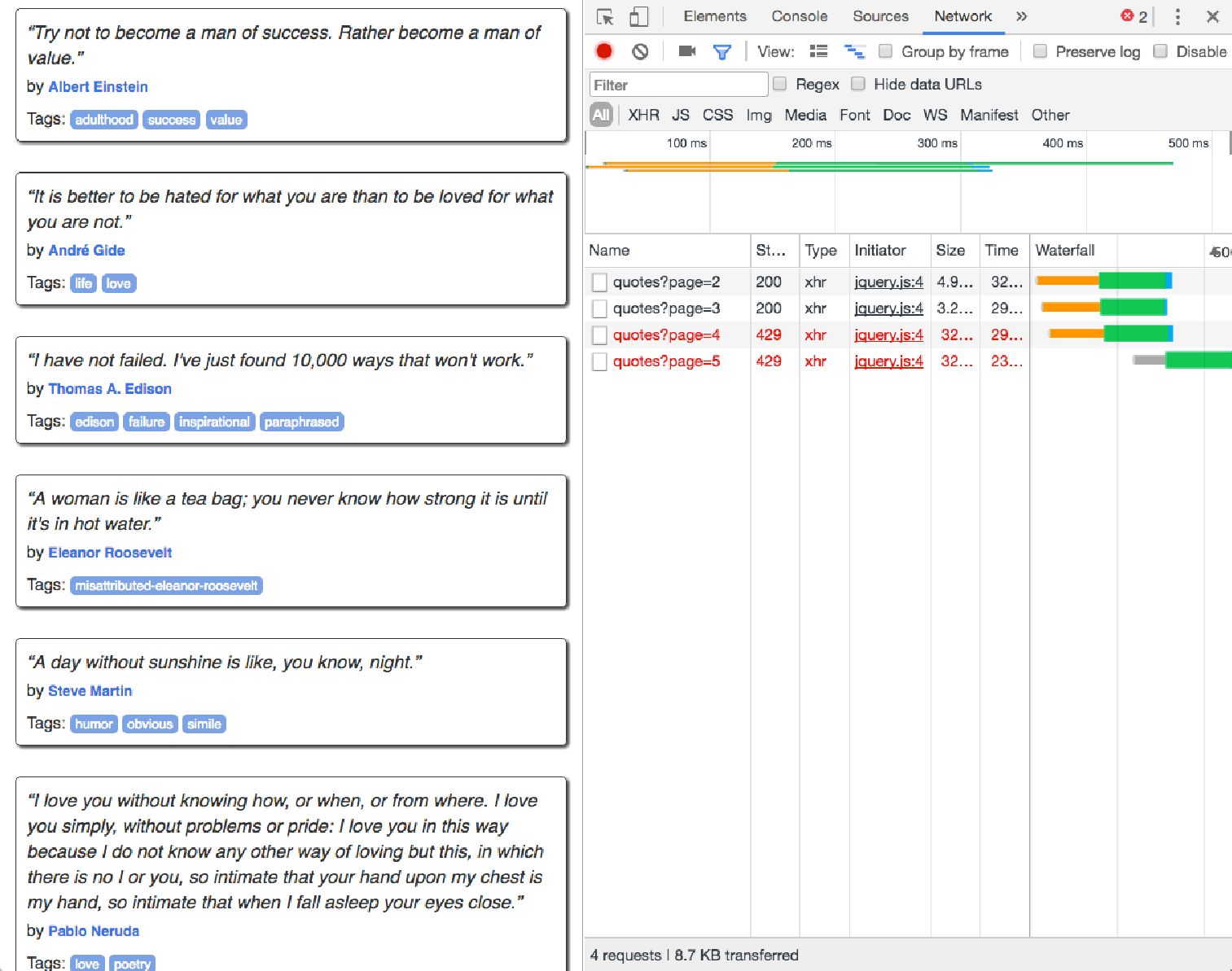
当我们点击其中一个链接时,我们可以看到以下 JSON:
{
"has_next": true,
"page": 2,
"quotes": [{
"author": {
"goodreads_link": "/author/show/82952.Marilyn_Monroe",
"name": "Marilyn Monroe",
"slug": "Marilyn-Monroe"
},
"tags": ["friends", "heartbreak", "inspirational", "life", "love",
"sisters"],
"text": "\u201cThis life is what you make it...."
}, {
"author": {
"goodreads_link": "/author/show/1077326.J_K_Rowling",
"name": "J.K. Rowling",
"slug": "J-K-Rowling"
},
"tags": ["courage", "friends"],
"text": "\u201cIt takes a great deal of bravery to stand up to our enemies,
but just as much to stand up to our friends.\u201d"
},这很棒,因为我们需要做的就是不断生成对 /api/quotes?page=x 的请求,增加 x 直到回复文档中存在 has_next 标记。 如果没有更多页面,则该标签将不会出现在文档中。
如何做
06/05_scrapy_continuous.py 文件包含一个 Scrapy 代理,它抓取这组页面。 使用 Python 解释器运行它,您将看到类似于以下内容的输出(以下是输出的多个摘录):
<200 http://spidyquotes.herokuapp.com/api/quotes?page=2>
2017-10-29 16:17:37 [scrapy.core.scraper] DEBUG: Scraped from <200
http://spidyquotes.herokuapp.com/api/quotes?page=2>
{'text': "“This life is what you make it. No matter what, you're going to
mess up sometimes, it's a universal truth. But the good part is you get to
decide how you're going to mess it up. Girls will be your friends - they'll
act like it anyway. But just remember, some come, some go. The ones that
stay with you through everything - they're your true best friends. Don't
let go of them. Also remember, sisters make the best friends in the world.
As for lovers, well, they'll come and go too. And baby, I hate to say it,
most of them - actually pretty much all of them are going to break your
heart, but you can't give up because if you give up, you'll never find your
soulmate. You'll never find that half who makes you whole and that goes for
everything. Just because you fail once, doesn't mean you're gonna fail at
everything. Keep trying, hold on, and always, always, always believe in
yourself, because if you don't, then who will, sweetie? So keep your head
high, keep your chin up, and most importantly, keep smiling, because life's
a beautiful thing and there's so much to smile about.”", 'author': 'Marilyn
Monroe', 'tags': ['friends', 'heartbreak', 'inspirational', 'life', 'love',
'sisters']}
2017-10-29 16:17:37 [scrapy.core.scraper] DEBUG: Scraped from <200
http://spidyquotes.herokuapp.com/api/quotes?page=2>
{'text': '“It takes a great deal of bravery to stand up to our enemies, but
just as much to stand up to our friends.”', 'author': 'J.K. Rowling',
'tags': ['courage', 'friends']}
2017-10-29 16:17:37 [scrapy.core.scraper] DEBUG: Scraped from <200
http://spidyquotes.herokuapp.com/api/quotes?page=2>
{'text': "“If you can't explain it to a six year old, you don't understand
it yourself.”", 'author': 'Albert Einstein', 'tags': ['simplicity',
'understand']}当到达第 10 页时,它将停止,因为它将看到内容中没有设置下一页标志。
工作原理
让我们通过 spider 来看看它是如何工作的。 spider 程序以以下起始 URL 定义开始:
class Spider(scrapy.Spider):
name = 'spidyquotes'
quotes_base_url = 'http://spidyquotes.herokuapp.com/api/quotes'
start_urls = [quotes_base_url]
download_delay = 1.5然后 parse 方法打印响应并将 JSON 解析为数据变量:
def parse(self, response):
print(response)
data = json.loads(response.body)然后它循环遍历 JSON 对象的quotes 元素中的所有项目。 对于每个项目,它都会生成一个新的 Scrapy 项目返回给 Scrapy 引擎:
for item in data.get('quotes', []):
yield {
'text': item.get('text'),
'author': item.get('author', {}).get('name'),
'tags': item.get('tags'),
}然后,它检查数据 JSON 变量是否具有 “has_next” 属性,如果有,则获取下一页并向 Scrapy 生成一个新请求以解析下一页:
if data['has_next']:
next_page = data['page'] + 1
yield scrapy.Request(self.quotes_base_url + "?page=%s" % next_page)还有更多
还可以使用 Selenium 处理无限的滚动页面。 以下代码位于 06/06_scrape_continuous_twitter.py 中:
from selenium import webdriver
import time
driver = webdriver.PhantomJS()
print("Starting")
driver.get("https://twitter.com")
scroll_pause_time = 1.5
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
print(last_height)
# Scroll down to bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(scroll_pause_time)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
print(new_height, last_height)
if new_height == last_height:
break
last_height = new_height输出将类似于以下内容:
Starting
4882
8139 4882
8139
11630 8139
11630
15055 11630
15055
15055 15055
Process finished with exit code 0此代码首先从 Twitter 加载页面。 当页面完全加载时,对 .get() 的调用将返回。 然后检索 scrollHeight,程序滚动到该高度并等待片刻以加载新内容。 再次检索浏览器的 scrollHeight,如果与 last_height 不同,则循环继续处理。 如果与 last_height 相同,则表示没有加载新内容,您可以继续并检索已完成页面的 HTML。