使用 Scrapy 选择器
Scrapy 是一个 Python 网络 spider 框架,用于从网站中提取数据。它为浏览整个网站提供了许多强大的功能,例如跟踪链接。它提供的一项功能是使用 DOM 和现在非常熟悉的 XPath 在文档中查找数据。
在本教程中,我们将加载 StackOverflow 上的当前问题列表,然后使用一个 scrapy 选择器对其进行解析。使用该选择器,我们将提取每个问题的文本。
如何做
我们首先从 scrapy 中导入选择器,然后导入请求,以便检索页面:
In [1]: from scrapy.selector import Selector
...: import requests
...:接下来,我们加载页面。在本例中,我们将检索 StackOverflow 上最近的问题并提取其标题。我们可以通过以下方式进行查询:
In [2]: response = requests.get("http://stackoverflow.com/questions")现在创建一个选择器,并将响应对象传给它:
In [3]: selector = Selector(response)
...: selector
...:
Out[3]: <Selector xpath=None data='<html>\r\n\r\n <head>\r\n\r\n<title>N'>检查该页面的内容,我们可以看到问题的结构如下的 HTML 结构:
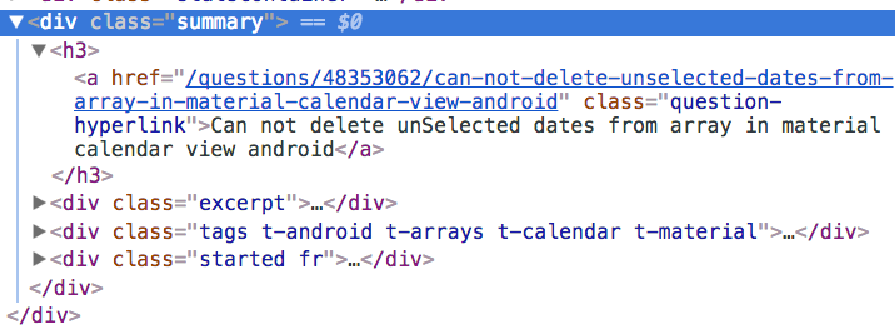
有了选择器,我们就可以使用 XPath 查找这些内容:
In [4]: summaries = selector.xpath('//div[@class="summary"]/h3')
...: summaries[0:5]
...:
Out[4]:
[<Selector xpath='//div[@class="summary"]/h3' data='<h3><a
href="/questions/48353091/how-to-'>,
<Selector xpath='//div[@class="summary"]/h3' data='<h3><a
href="/questions/48353090/move-fi'>,
<Selector xpath='//div[@class="summary"]/h3' data='<h3><a
href="/questions/48353089/java-la'>,
<Selector xpath='//div[@class="summary"]/h3' data='<h3><a
href="/questions/48353086/how-do-'>,
<Selector xpath='//div[@class="summary"]/h3' data='<h3><a
href="/questions/48353085/running'>]现在,我们再深入一点,就能得到问题的标题了。
In [5]: [x.extract() for x in summaries.xpath('a[@class="questionhyperlink"]/text()')][:10]
Out[5]:
['How to convert stdout binary file to a data URL?',
'Move first letter from sentence to the end',
'Java launch program and interact with it programmatically',
'How do I build vala from scratch',
'Running Sql Script',
'Mysql - Auto create, update, delete table 2 from table 1',
'how to map meeting data corresponding calendar time in java',
'Range of L*a* b* in Matlab',
'set maximum and minimum number input box in js,html',
'I created generic array and tried to store the value but it is showing ArrayStoreException']还有更多
要了解有关 Scrapy 选择器的更多信息,请参阅: https://doc.scrapy.org/en/latest/topics/selectors.html。