处理分页网站
分页将大量内容分成多个页面。 通常,这些页面都有上一页/下一页链接供用户单击。 通常可以使用 XPath 或其他方式找到这些链接,然后按照这些链接转到下一页(或上一页)。 我们来看看如何用 Scrapy 来跨页面遍历。 我们将看一个抓取自动互联网搜索结果的假设示例。 这些技术直接适用于许多具有搜索功能的商业网站,并且很容易针对这些情况进行修改。
准备工作
我们将通过一个示例演示如何处理分页,该示例从提供的容器中的网站抓取一组页面。 该网站对五个页面进行了建模,每个页面上都有上一个和下一个链接,以及我们将提取的每个页面中的一些嵌入数据。
该集的第一页可以在 http://localhost:5001/pagination/page1.html 中看到。 下图显示此页面打开,我们正在检查 “下一步” 按钮:
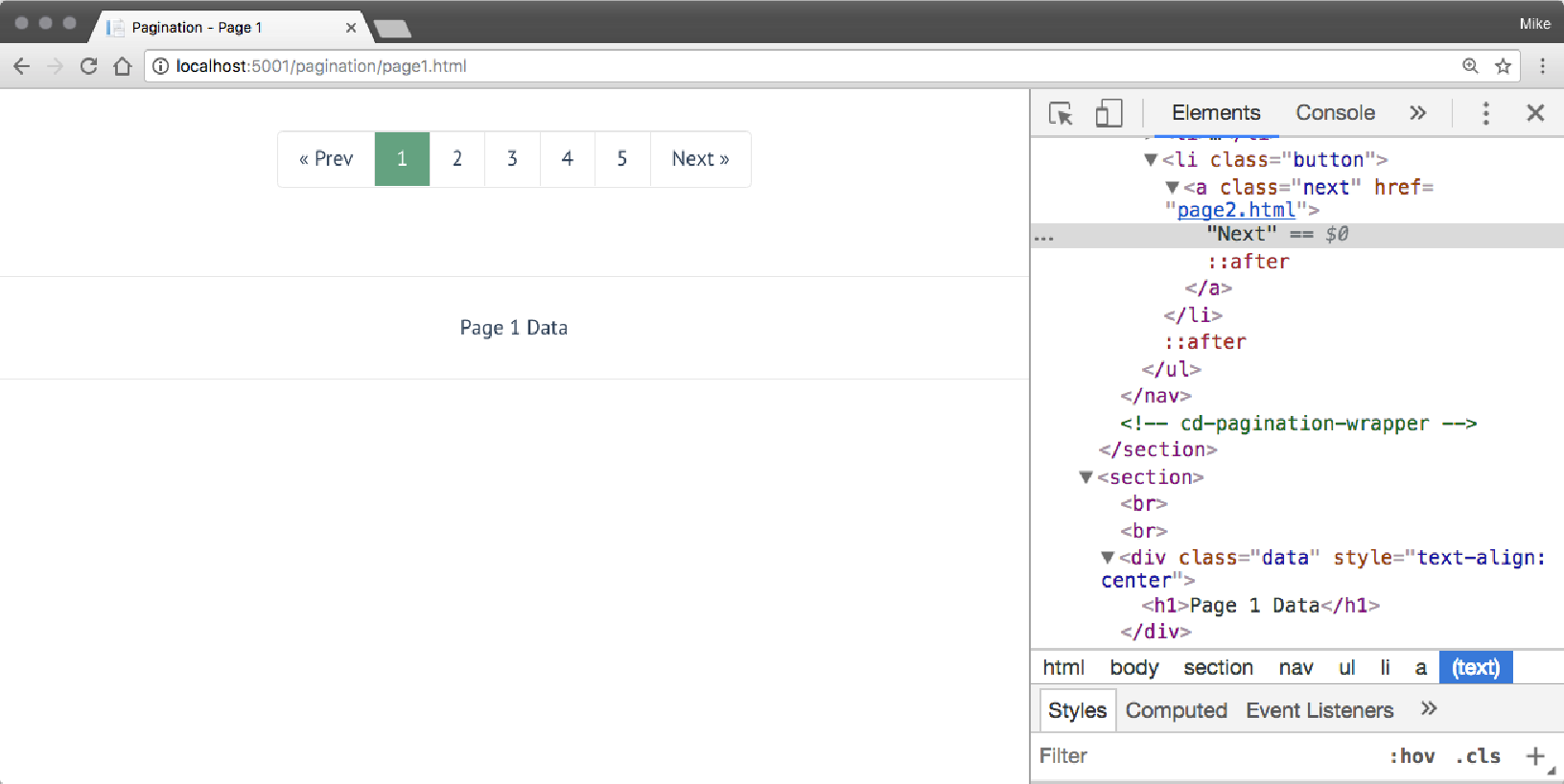
该页面有两个令人感兴趣的部分。 第一个是 “下一步” 按钮的链接。 这是一种相当常见的做法,该链接有一个类,该类将该链接标识为下一页的链接。 我们可以使用该信息来查找此链接。 在这种情况下,我们可以使用以下 XPath 找到它:
//*/a[@class='next']第二个感兴趣的项目实际上是从页面中检索我们想要的数据。 在这些页面上,这是通过带有 class="data" 属性的 <div> 标记来标识的。 这些页面只有一个数据项,但在这个抓取页面进行搜索的示例中,我们将提取多个项目。
现在让我们实际为这些页面运行一个抓取器。
怎么做
有一个名为 06/08_scrapy_pagination.py 的脚本。 使用 Python 运行这个脚本,Scrapy 将会有很多输出,其中大部分将是标准的 Scrapy 调试输出。 但是,在该输出中,您将看到我们提取了所有五个页面上的数据项:
Page 1 Data
Page 2 Data
Page 3 Data
Page 4 Data
Page 5 Data工作原理
代码以 CrawlSpider 的定义和起始 URL 开始:
class PaginatedSearchResultsSpider(CrawlSpider):
name = "paginationscraper"
start_urls = [
"http://localhost:5001/pagination/page1.html"
]然后定义规则字段,它通知 Scrapy 如何解析每个页面以查找链接。此代码使用前面讨论的 XPath 来查找页面中的 Next 链接。 Scrapy 将在每个页面上使用此规则来查找下一个要处理的页面,并将该请求排队在当前页面之后进行处理。 对于找到的每个页面,回调参数通知 Scrapy 调用哪个方法进行处理,在本例中为 parse_result_page:
rules = (
# Extract links for next pages
Rule(LinkExtractor(allow=(),
restrict_xpaths=("//*/a[@class='next']")),
callback='parse_result_page', follow=True),
)声明一个名为 all_items 的列表变量来保存我们找到的所有项目:
all_items = []然后定义了 parse_start_url 方法。 Scrapy 将调用它来解析爬网中的初始 URL。 该函数只是将该处理推迟到 parse_result_page:
def parse_start_url(self, response):
return self.parse_result_page(response)然后,parse_result_page 方法使用 XPath 查找 <div class="data"> 标记内的 <h1> 标记内的文本。 然后将该文本附加到 all_items 列表中:
def parse_result_page(self, response):
data_items = response.xpath("//*/div[@class='data']/h1/text()")
for data_item in data_items:
self.all_items.append(data_item.root)抓取完成后,将调用 close() 方法并写出 all_items 字段的内容:
def closed(self, reason):
for i in self.all_items:
print(i)爬虫使用 Python 作为脚本运行,使用以下命令:
if __name__ == "__main__":
process = CrawlerProcess({
'LOG_LEVEL': 'DEBUG',
'CLOSESPIDER_PAGECOUNT': 10
})
process.crawl(ImdbSearchResultsSpider)
process.start()请注意,CLOSESPIDER_PAGECOUNT 属性的使用被设置为 10。这超出了此站点上的页面数,但在许多(或大多数)情况下,搜索结果中可能有数千页。 阅读适当页数后停止是一个好习惯。 对于爬虫来说,这是一种良好的行为,因为在几页之后,项目与搜索的相关性会急剧下降,因此爬行超出前几页的回报会大大减少,通常最好在几页后停止。