以 unicode / UTF-8 加载数据
文档的编码告诉应用程序文档中的字符在文件中如何表示为字节。从本质上讲,编码指定了每个字符的位数。在标准 ASCII 文档中,所有字符都是 8 位。HTML 文件通常按每个字符 8 位编码,但随着互联网的全球化,情况并非总是如此。许多 HTML 文档都是以 16 位字符编码,或使用 8 位和 16 位字符的组合。
一种特别常见的 HTML 文档编码形式被称为 UTF-8。这就是编码形式。
准备工作
我们将从本地网络服务器读取名为 unicode.html 的文件,该服务器位于 http://localhost:8080/unicode.html 。该文件采用 UTF-8 编码,包含编码空间不同部分的几组字符。例如,页面在浏览器中的显示如下:

使用支持 UTF-8 的编辑器,我们可以看到西里尔字符是如何在编辑器中是如何呈现的:
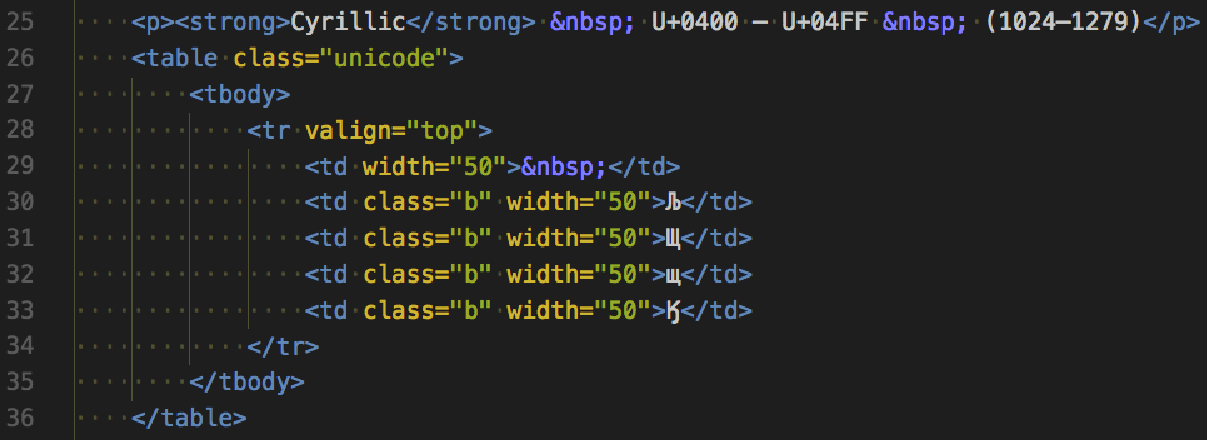
示例代码在 02/06_unicode.py 中。
如何做
我们将了解如何使用 urlopen 和请求来处理 UTF-8 版本的 HTML。这两个 库的处理方式不同,让我们来研究一下。让我们开始导入 urllib、加载 页面,并检查部分内容。
In [8]: from urllib.request import urlopen
...: page = urlopen("http://localhost:8080/unicode.html")
...: content = page.read()
...: content[840:1280]
...:
Out[8]: b'><strong>Cyrillic</strong> U+0400 \xe2\x80\x93
U+04FF (1024\xe2\x80\x931279)</p>\n <table
class="unicode">\n <tbody>\n <tr valign="top">\n <td
width="50"> </td>\n <td class="b" width="50">\xd0\x89</td>\n
<td class="b" width="50">\xd0\xa9</td>\n <td class="b"
width="50">\xd1\x89</td>\n <td class="b" width="50">\xd3\x83</td>\n</tr>\n </tbody>\n </table>\n\n '|
请注意西里尔字母是如何以多字节代码的形式读入的符号,如 \xd0\x89。 |
为了解决这个问题,我们可以使用 Python str 语句将内容转换为 UTF-8 格式:
In [9]: str(content, "utf-8")[837:1270]
Out[9]: '<strong>Cyrillic</strong> U+0400 – U+04FF
(1024–1279)</p>\n <table class="unicode">\n <tbody>\n <tr
valign="top">\n <td width="50"> </td>\n <td class="b"
width="50">Љ</td>\n <td class="b" width="50">Щ</td>\n <td
class="b" width="50">щ</td>\n <td class="b" width="50">Ӄ</td>\n</tr>\n </tbody>\n </table>\n\n '|
请注意,现在输出的字符已正确编码。 |
我们可以通过使用请求来排除这一额外步骤。
In [9]: import requests
...: response =
requests.get("http://localhost:8080/unicode.html").text
...: response.text[837:1270]
...:
'<strong>Cyrillic</strong> U+0400 – U+04FF
(1024–1279)</p>\n <table class="unicode">\n <tbody>\n <tr
valign="top">\n <td width="50"> </td>\n <td class="b"
width="50">Љ</td>\n <td class="b" width="50">Щ</td>\n <td
class="b" width="50">щ</td>\n <td class="b" width="50">Ӄ</td>\n</tr>\n </tbody>\n </table>\n\n '