在 Elasticsearch 中存储数据
Elasticsearch 是基于 Lucene 的搜索引擎。它提供了一个分布式、多用户、全文搜索引擎,具有 HTTP Web 界面和无模式 JSON 文档。它是一种非关系型数据库(通常称为 NoSQL),侧重于存储文档而非记录。这些文档可以是多种格式,其中一种对我们很有用: JSON 格式。这使得使用 Elasticsearch 变得非常简单,因为我们不需要将数据转换成/转换成 JSON。在本书的后面部分,我们将更多地使用 Elasticsearch。
现在,让我们将计划数据存储到 Elasticsearch 中。
准备工作
我们将访问本地安装的 Elasticsearch 服务器。为此,我们将使用 Elasticsearch-py 库。您很可能需要使用 pip 安装该库: pip install elasticsearch。
与 PostgreSQL 和 MySQL 不同,我们不需要提前在 Elasticsearch 中创建表格。表。Elasticsearch 不关心结构化数据模式(虽然它有 索引),所以我们不需要经历这个过程。
如何做
将数据写入 Elasticsearch 其实很简单。下面的 Python 代码可以执行这项任务 使用我们的计划数据 (03/write_to_elasticsearch.py):
from elasticsearch import Elasticsearch
from get_planet_data import get_planet_data
# create an elastic search object
es = Elasticsearch()
# get the data
planet_data = get_planet_data()
for planet in planet_data:
# insert each planet into elasticsearch server
res = es.index(index='planets', doc_type='planets_info', body=planet)
print (res)执行此操作的结果如下:
{'_index': 'planets', '_type': 'planets_info', '_id':
'AV4qIF3_T0Z2t9T850q6', '_version': 1, 'result': 'created', '_shards':
{'total': 2, 'successful': 1, 'failed': 0}, 'created': True}{'_index':
'planets', '_type': 'planets_info', '_id': 'AV4qIF5QT0Z2t9T850q7',
'_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful':
1, 'failed': 0}, 'created': True}
{'_index': 'planets', '_type': 'planets_info', '_id':
'AV4qIF5XT0Z2t9T850q8', '_version': 1, 'result': 'created', '_shards':
{'total': 2, 'successful': 1, 'failed': 0}, 'created': True}
{'_index': 'planets', '_type': 'planets_info', '_id':
'AV4qIF5fT0Z2t9T850q9', '_version': 1, 'result': 'created', '_shards':
{'total': 2, 'successful': 1, 'failed': 0}, 'created': True}
{'_index': 'planets', '_type': 'planets_info', '_id': 'AV4qIF5mT0Z2t9T850q-
', '_version': 1, 'result': 'created', '_shards': {'total': 2,
'successful': 1, 'failed': 0}, 'created': True}
{'_index': 'planets', '_type': 'planets_info', '_id':
'AV4qIF5rT0Z2t9T850q_', '_version': 1, 'result': 'created', '_shards':
{'total': 2, 'successful': 1, 'failed': 0}, 'created': True}
{'_index': 'planets', '_type': 'planets_info', '_id':
'AV4qIF50T0Z2t9T850rA', '_version': 1, 'result': 'created', '_shards':
{'total': 2, 'successful': 1, 'failed': 0}, 'created': True}
{'_index': 'planets', '_type': 'planets_info', '_id':
'AV4qIF56T0Z2t9T850rB', '_version': 1, 'result': 'created', '_shards':
{'total': 2, 'successful': 1, 'failed': 0}, 'created': True}
{'_index': 'planets', '_type': 'planets_info', '_id':
'AV4qIF6AT0Z2t9T850rC', '_version': 1, 'result': 'created', '_shards':
{'total': 2, 'successful': 1, 'failed': 0}, 'created': True}输出结果显示了每次插入的结果,为我们提供了诸如 elasticsearch 分配给文档的 _id 等信息。
如果你也安装了 logstash 和 Kibana,就可以在 Kibana 中看到数据:
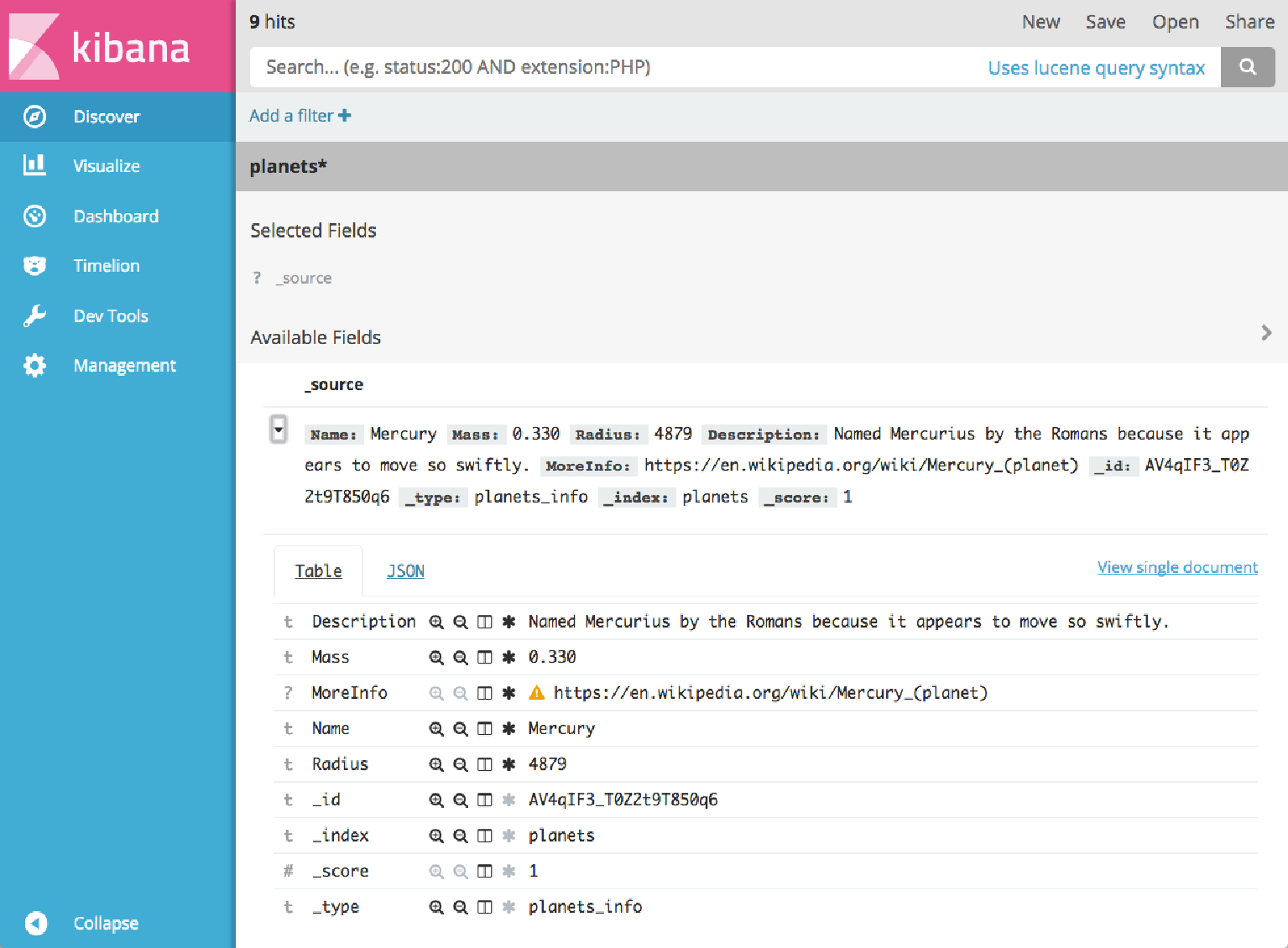
我们可以用下面的 Python 代码来查询数据。这段代码会检索 "planets" 索引中的所有文档,并打印出每颗行星的名称、质量和半径 (03/read_from_elasticsearch.py):
from elasticsearch import Elasticsearch
# create an elastic search object
es = Elasticsearch()
res = es.search(index="planets", body={"query": {"match_all": {}}})
print("Got %d Hits:" % res['hits']['total'])
for hit in res['hits']['hits']:
print("%(Name)s %(Mass)s: %(Radius)s" % hit["_source"])结果输出如下:
Mercury 0.330: 4879
Mars 0.642: 6792
Venus 4.87: 12104
Saturn 568: 120536
Pluto 0.0146: 2370
Earth 5.97: 12756
Uranus 86.8: 51118
Jupiter 1898: 142984
Neptune 102: 49528工作原理
Elasticsearch 既是一个 NoSQL 数据库,又是一个搜索引擎。 您将文档提供给 Elasticsearch,它会解析文档中的数据并自动为该数据创建搜索索引。
在插入过程中,我们使用了elasticsearch库的.index()方法并指定了一个索引,名为 “planets”,一个文档类型,planets_info,最后是文档的主体,这是我们的planet Python对象。 反对 JSON 并将其发送到 Elasticsearch 进行存储和索引的 elasticsearch 库。
index 参数用于告知 Elasticsearch 如何创建索引,它将用于索引,并且我们可以使用该索引来指定查询时要搜索的一组文档。 当我们执行查询时,我们指定了相同的索引 “planets” 并执行查询来匹配所有文档。
还有更多
您可以在以下位置找到有关 elasticsearch 的更多信息: https://www.elastic.co/products/elasticsearch 。 有关 python API 的信息可以在以下位置找到: http://pyelasticsearch.readthedocs.io/en/latest/api/
我们还将在本书的后面章节中回到 Elasticsearch。