使用AWS S3存储数据
在很多情况下,我们只想将我们抓取的内容保存到本地副本中,以用于存档、备份或以后的批量分析。 我们可能还想保存这些网站的媒体以供以后使用。 我为广告合规公司构建了抓取工具,我们将在网站上跟踪和下载基于广告的媒体,以确保正确使用,并存储以供以后分析、合规性和转码。
这些类型的系统所需的存储可能是巨大的,但随着 AWS S3(简单存储服务)等云存储服务的出现,这比管理您的大型 SAN(存储区域网络)变得更加容易且更具成本效益。 自己的 IT 部门。 此外,S3 还可以自动将数据从热存储转移到冷存储,然后转移到长期存储(例如冰川),这可以为您节省更多资金。
我们不会讨论所有这些细节,而只是看看将 Planets.html 文件存储到 S3 存储桶中。 一旦你能做到这一点,你就可以保存你想要的任何内容。
准备工作
要执行以下示例,您将需要一个 AWS 账户并有权访问在 Python 代码中使用的密钥。 它们对于您的帐户来说是唯一的。 我们将使用 boto3 库进行 S3 访问。 您可以使用 pip install boto3 安装它。 此外,您还需要设置环境变量来进行身份验证。 这些将如下所示:
AWS_ACCESS_KEY_ID=AKIAIDCQ5PH3UMWKZEWA
AWS_SECRET_ACCESS_KEY=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这些可以在 AWS 门户的 IAM(身份访问管理)部分下找到。
|
将这些键放入环境变量中是一个很好的做法。 将它们写入代码可能会导致被盗。 在写这本书的过程中,我对此进行了硬编码,并无意中将它们签入了 GitHub。 第二天早上,我醒来时收到来自 AWS 的重要消息,我有数千台服务器正在运行! GitHub 抓取工具正在寻找这些密钥,它们会被发现并用于邪恶目的。 当我把它们全部关闭时,我的账单已高达 6000 美元,全部是一夜之间累积的。 值得庆幸的是,AWS 免除了这些费用! |
怎么做
我们不会解析 Planets.html 文件中的数据,而只是使用请求从本地 Web 服务器检索它:
-
以下代码(位于 03/S3.py 中)读取行星网页并将其存储在 S3 中:
import requests import botocore import boto3 data = requests.get("http://localhost:8080/pages/planets.html").text # create S3 client, use environment variables for keys s3 = boto3.client('s3') # the bucket bucket_name = "planets-content" # create bucket, set s3.create_bucket(Bucket=bucket_name, ACL='public-read') s3.put_object(Bucket=bucket_name, Key='planet.html', Body=data, ACL="public-read") -
该应用程序将为您提供类似于以下内容的输出,这是 S3 信息,告诉您有关新项目的各种事实。
{'ETag': '"3ada9dcd8933470221936534abbf7f3e"', 'ResponseMetadata': {'HTTPHeaders': {'content-length': '0', 'date': 'Sun, 27 Aug 2017 19:25:54 GMT', 'etag': '"3ada9dcd8933470221936534abbf7f3e"', 'server': 'AmazonS3', 'x-amz-id-2': '57BkfScql637op1dIXqJ7TeTmMyjVPk07cAMNVqE7C8jKsb7nRO+0GSbkkLWUBWh81 k+q2nMQnE=', 'x-amz-request-id': 'D8446EDC6CBA4416'}, 'HTTPStatusCode': 200, 'HostId': '57BkfScql637op1dIXqJ7TeTmMyjVPk07cAMNVqE7C8jKsb7nRO+0GSbkkLWUBWh81 k+q2nMQnE=', 'RequestId': 'D8446EDC6CBA4416', 'RetryAttempts': 0}} -
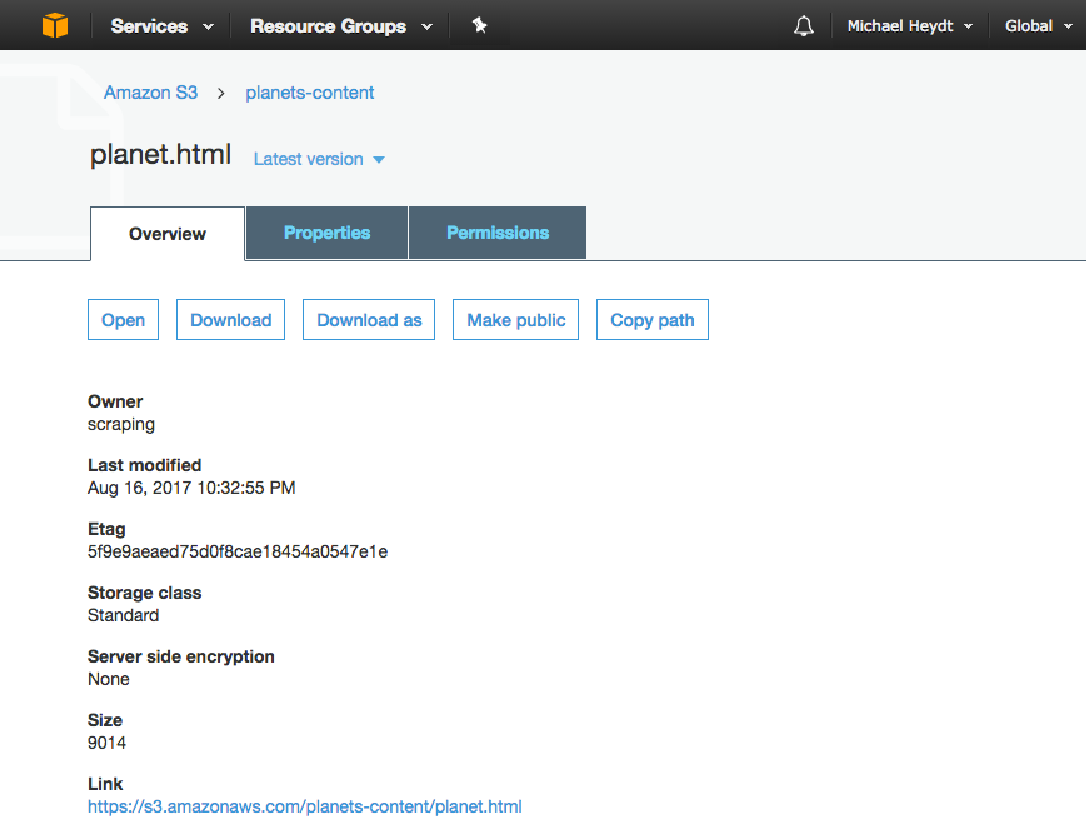
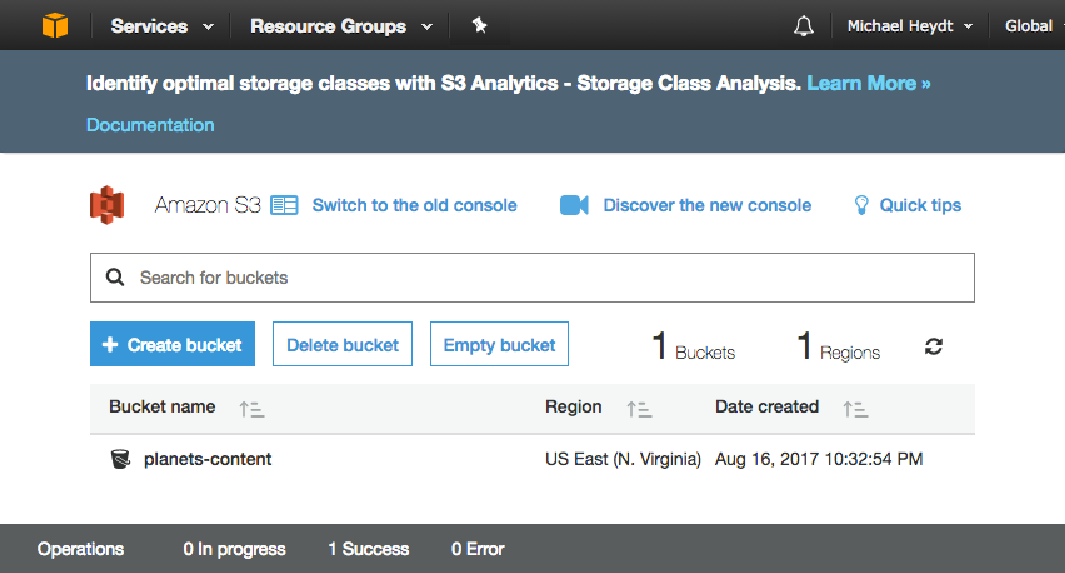
此输出向我们表明该对象已在存储桶中成功创建。 此时,您可以导航到 S3 控制台并查看您的存储桶:
-
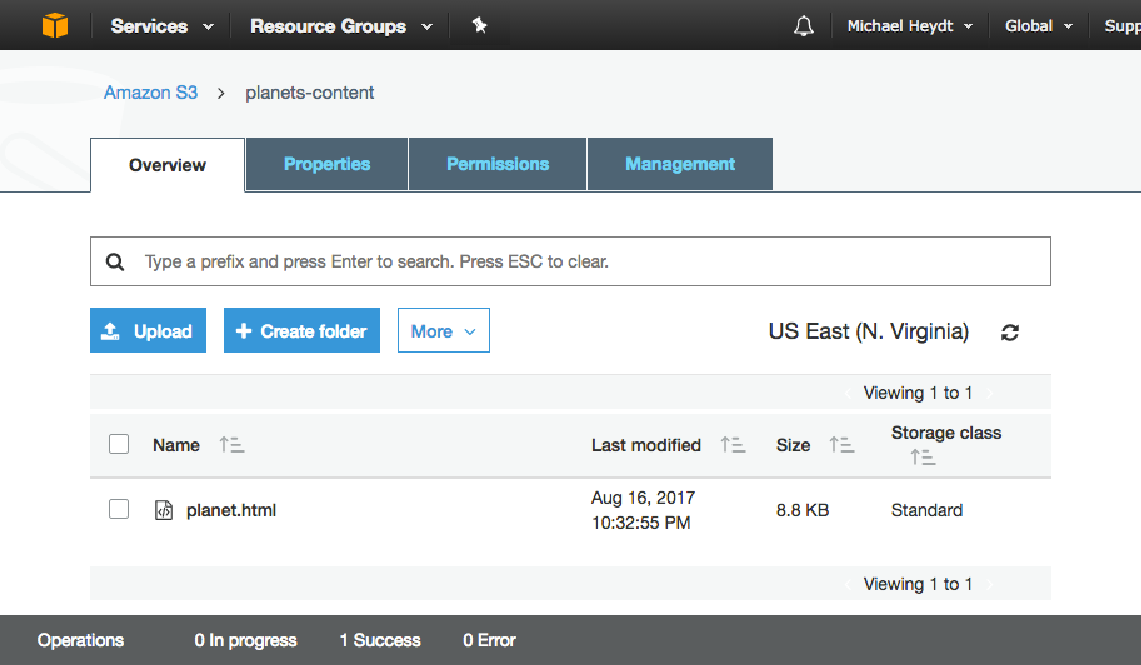
在存储桶内,您将看到planet.html 文件:
-
通过单击该文件,您可以看到 S3 中该文件的属性和 URL: