模块的拆分
微服务的目的是有效地拆分应用,实现敏捷开发和部署。但在拆分中会遇到什么问题?我们需要按照什么样的原则进行拆分?本章主要说明在拆分中存在的问题,然后说明针对这些问题,我们采取什么样的原则进行处理。
拆分中的问题
从单体式结构转向微服务框架中会持续遇到服务边界划分的问题:如果服务的粒度划分过粗,会回到单体式结构的老路;如果过细,服务间调用的开销会变得无法忽视,管理难度也会指数级增加。
同时,如果业务间有太多的事务,使用微服务进行开发的难度的会增加。当然,如果迭代周期长,用户有限,则使用微服务框架没有什么意义。
到目前为止,还没有一个公认的服务边界划分的标准,我们只能根据不同的业务系统加以调节,一般来说,有一些原则可以参考。
拆分原则
在拆分原则中,有下面几个比较出名的原则。
AKF扩展立方体
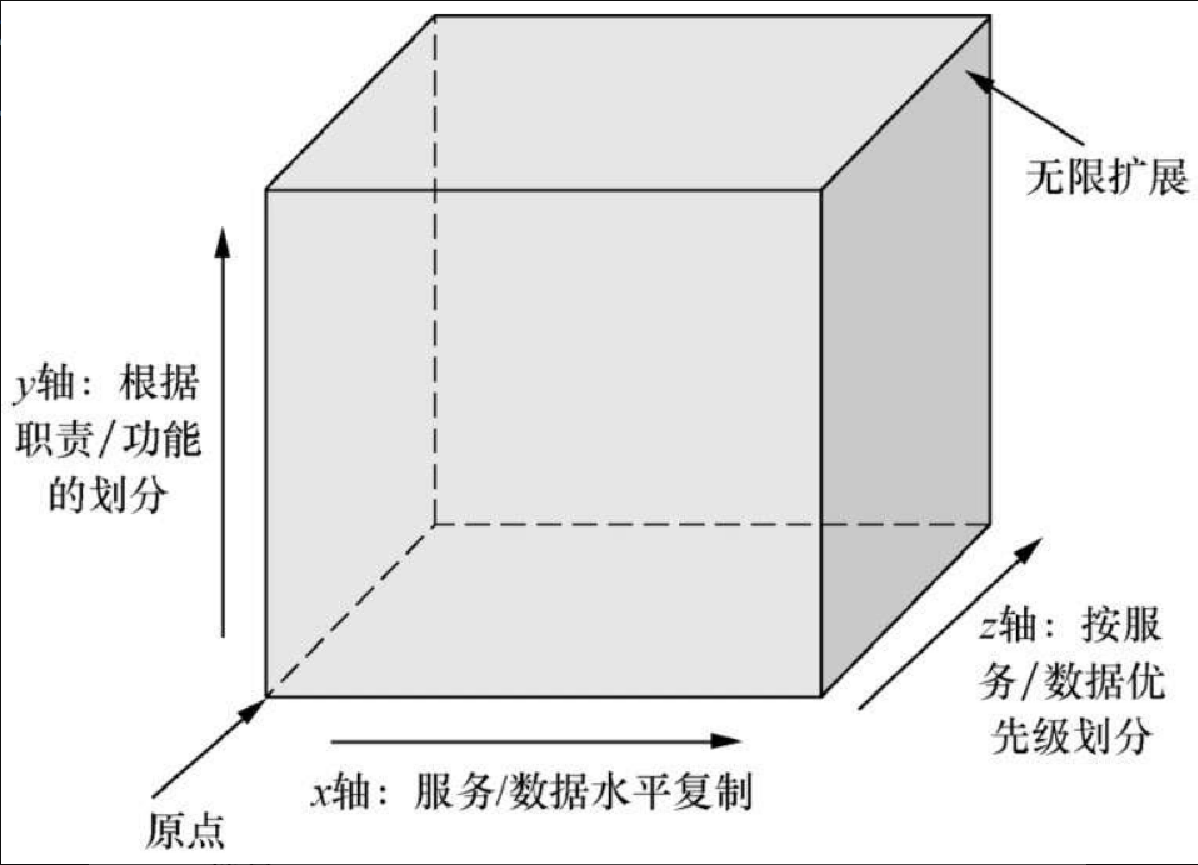
AKF 扩展立方体是《架构即未来:现代企业可扩展的 Web 架构、流程和组织(原书第2版)》一书中提出的可扩展模型,按照这个理论,我们可以将单体系统进行扩展。这个立方体有三条轴线,每条轴线描述扩展性的一个维度,如图 1.7 所示。
-
x 轴——无限复制服务和数据。
-
y 轴——关注应用中职责的划分,比如数据类型、交易执行类型的划分。
-
z 轴——关注服务和数据的优先级划分。
前后端分离
这种原则有很多公司在使用,优势是,在分离模式下,前后端交互使框架更加清晰,前后端得到高效开发;后端的服务简洁明了,方便维护。
前端可以采用多种技术,可以连接多种渠道,而后端服务无须变更,继续采用统一的数据和模型,就可以支撑 PC、App 等访问。
无状态服务
在讲这个原则之前,首先介绍什么是无状态服务。如果一个数据需要被多个服务共享,才能完成一次业务,那么这个数据被称为状态数据。而依赖这个状态数据的服务被称为有状态服务,反之称为无状态服务。
无状态服务原则是要把有状态的业务服务改为无状态的服务,使状态数据也就相应地迁移到对应的有状态数据服务中。我们先看一个图,然后通过图进行说明,如图 1.8 所示。
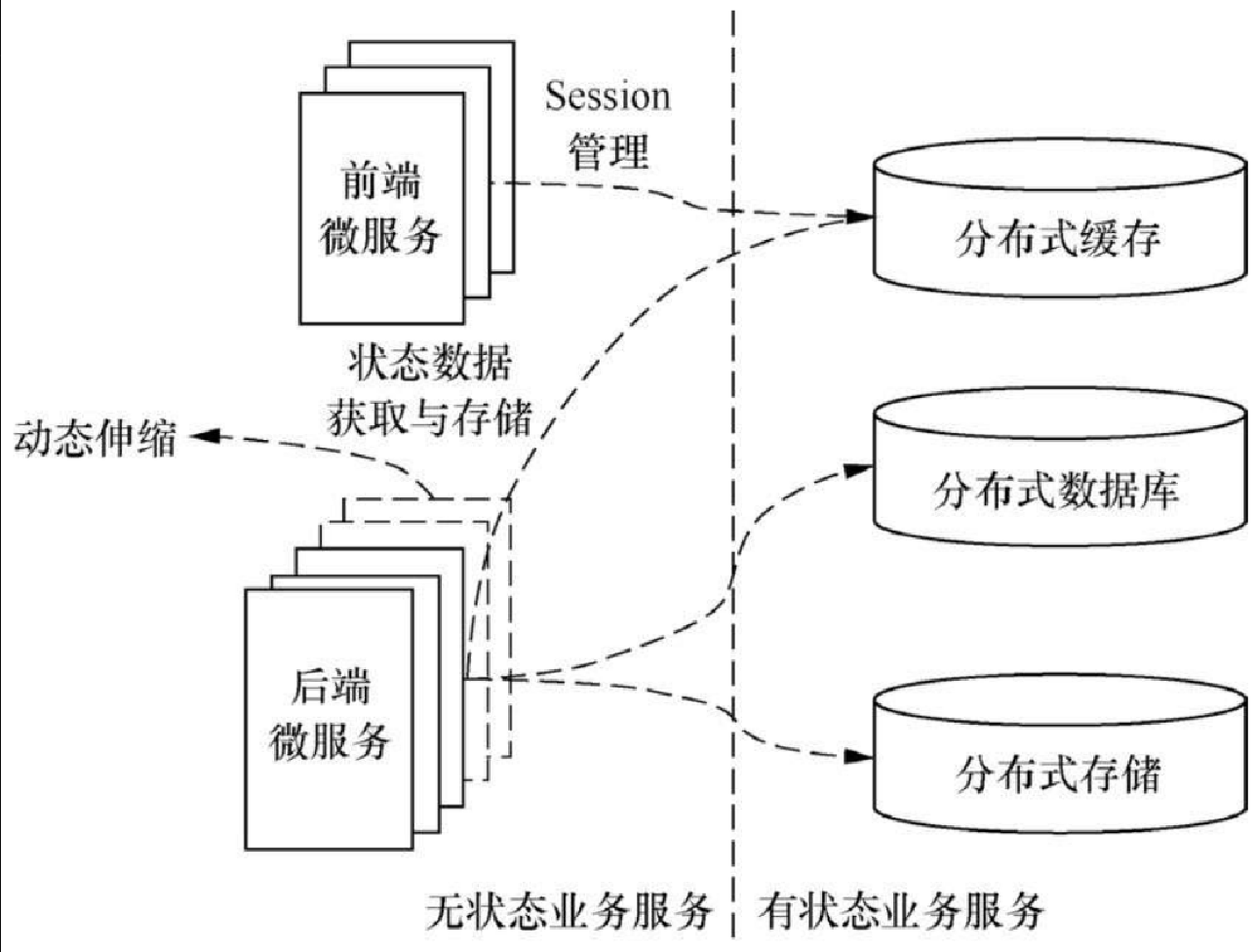
在图 1.8 中,可以看到服务已经前后端分离。这个原则即是把在本地内存中建立的数据缓存、Session 缓存数据迁移到分布式缓存中,使服务端变成无状态的节点。采用这个原则的好处是可以做到动态伸缩节点,而微服务应用动态增删节点,可避免考虑缓存数据如何同步的问题。