Hystrix的原理
在13.1节中,使用过 Hystrix 之后,读者就差不多理解了 Hystrix,不过可能只是感性的理解。在这一节,将会对 Hystrix 的原理做一个系统的介绍。
Hystrix产生背景
这里用数据说明为什么要使用 Hystrix。在微服务中,一个复杂的业务场景会被拆分成许多个微服务,每个微服务都是一个轻量级的子服务,通过网络进行服务之间的调用。
我们也说过,在微服务框架中可以快速地开发和维护,做到互不影响,实现敏捷开发部署。但是微服务的稳定性是一个挑战。举例,一个服务依赖 30 个微服务,如果每个微服务的可用性都是 99.99%,那么这个微服务的可用性是多少呢?
(99.99%)30 ≈ 99.7%。
这意味着,10 亿个请求中有 0.3%,即 3000000 不可用。
即使所有依赖项都具有良好的正常运行时间,每月也有 2 小时以上的停机时间。在实际场景中,情况肯定会更加糟糕,因为不可能没有任何别的问题。
在依赖的微服务中会有很多不可控制的因素,依赖也有很多不可控问题,如网络连接缓慢、资源繁忙、暂不可用、服务脱机等。
在复杂的分布式框架的应用程序中有很多的依赖,如图13.11所示。在高并发下,都访问依赖I,而依赖I处于不可使用状态,则引用依赖I的服务将会被阻塞。当请求越来越多时,将会占用更多的计算机资源,导致系统出现瓶颈,然后造成其他的应用不可用,最终使得系统崩溃,这就是前面说的雪崩效应。
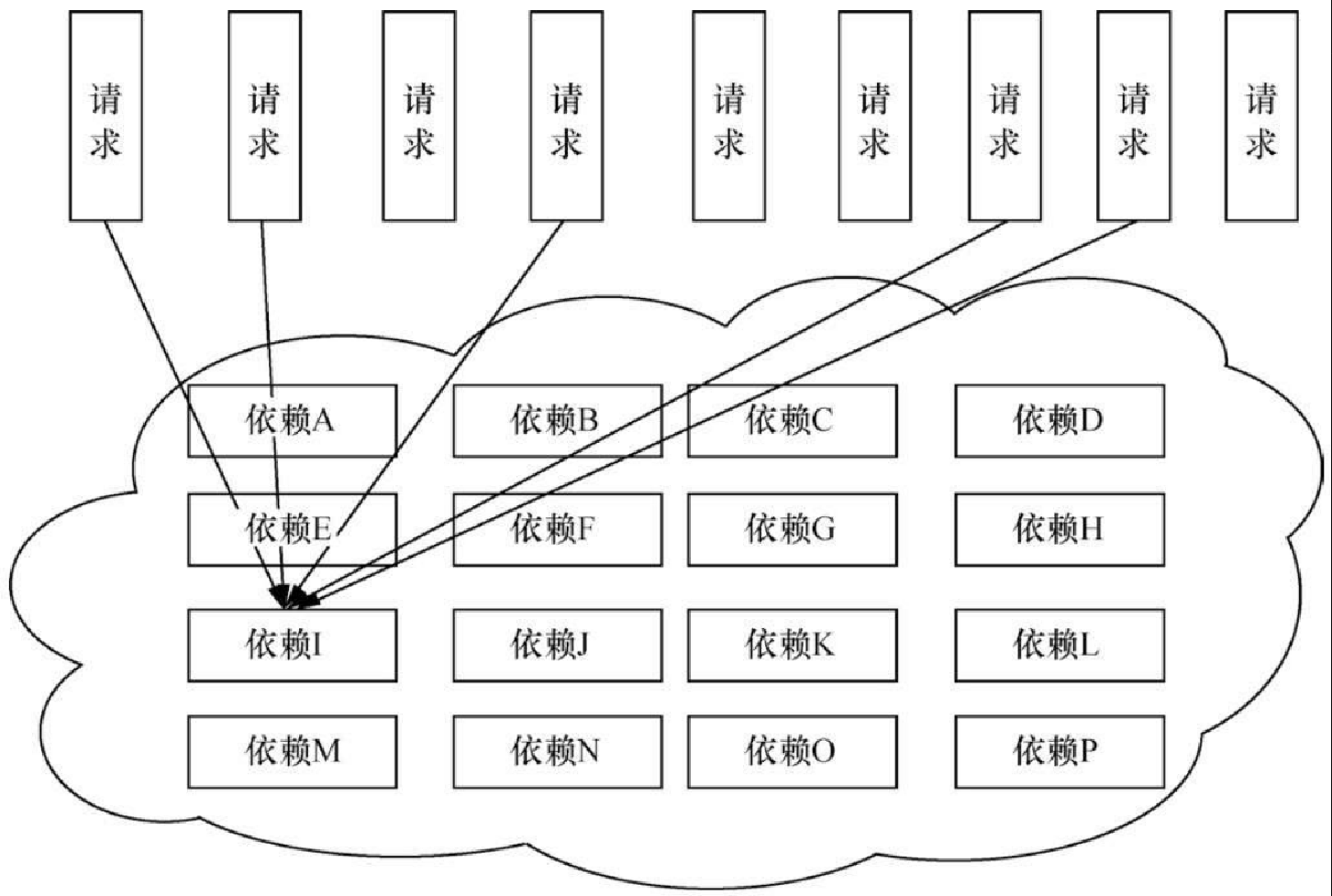
微服务都会不可避免地在某些时候不可用。如果高并发的依赖不可用时没有采取隔离措施,当前应用服务就有被拖垮的风险。
Hystrix实现原理
从上文可知,在微服务中影响稳定性可能是因为存在的雪崩效应,那么我们可以使用如下解决方式。
-
降级:在资源不足,或者超时时,进行降级。
-
熔断:在失败率达到设置的阈值时,进行熔断。
-
隔离:这里的隔离主要有线程隔离与信号量隔离,隔离服务的资源使用,使得服务不会被影响。
-
缓存:有请求缓存与请求合并机制。
-
监控,报警的支持。
下面主要对前三种方式进行介绍。
降级
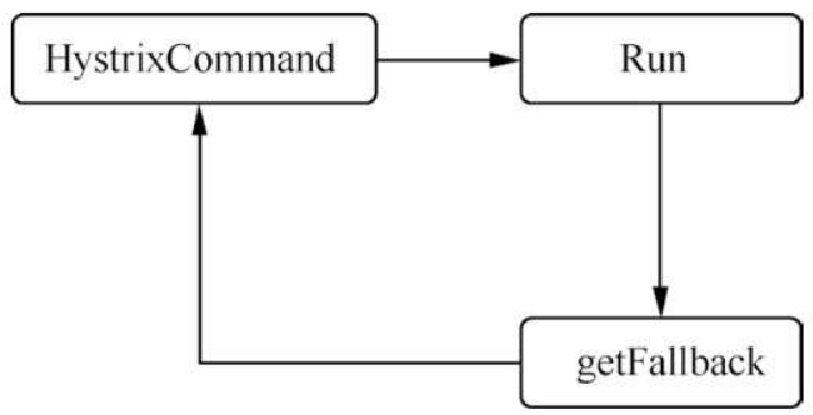
使用降级的目的是保证上游服务的稳定性。为了更好描述降级的原理,通过图13.12进行理解。
降级时,需要对下层依赖进行业务分级,把产生故障的丢掉,换一个轻量级的方法,这是退而求其次的方式。图中,如果在 Run 方法中出现了故障,则让请求跳转到 getFallback,然后将返回值返回到 HystrixCommand。注意的是,这里返回的是静态值。
还有一种就是级联模式,这种模式也可以参考一下,如图13.13所示。
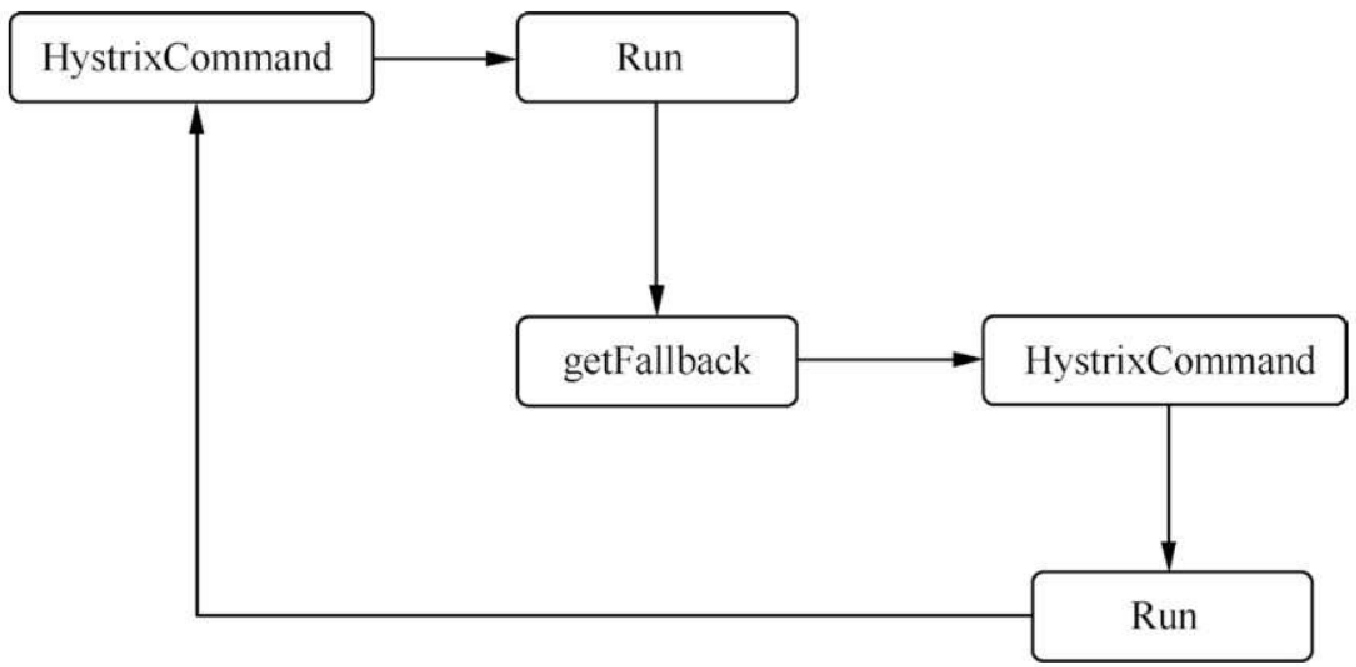
在图13.13中,如果第一个服务失败,则开始调用降级的服务,但是这次的降级服务不是静态的,我们可以重试或者访问数据库,尽量保证数据是希望返回的那个数据。但是这种方式,如果考虑得不充分还是达不到效果。
熔断
对于 Hystrix 的熔断,主要分为三个状态。关闭状态(Closed)、熔断状态(Open)、半熔断状态(Half-Open),如图13.14所示。
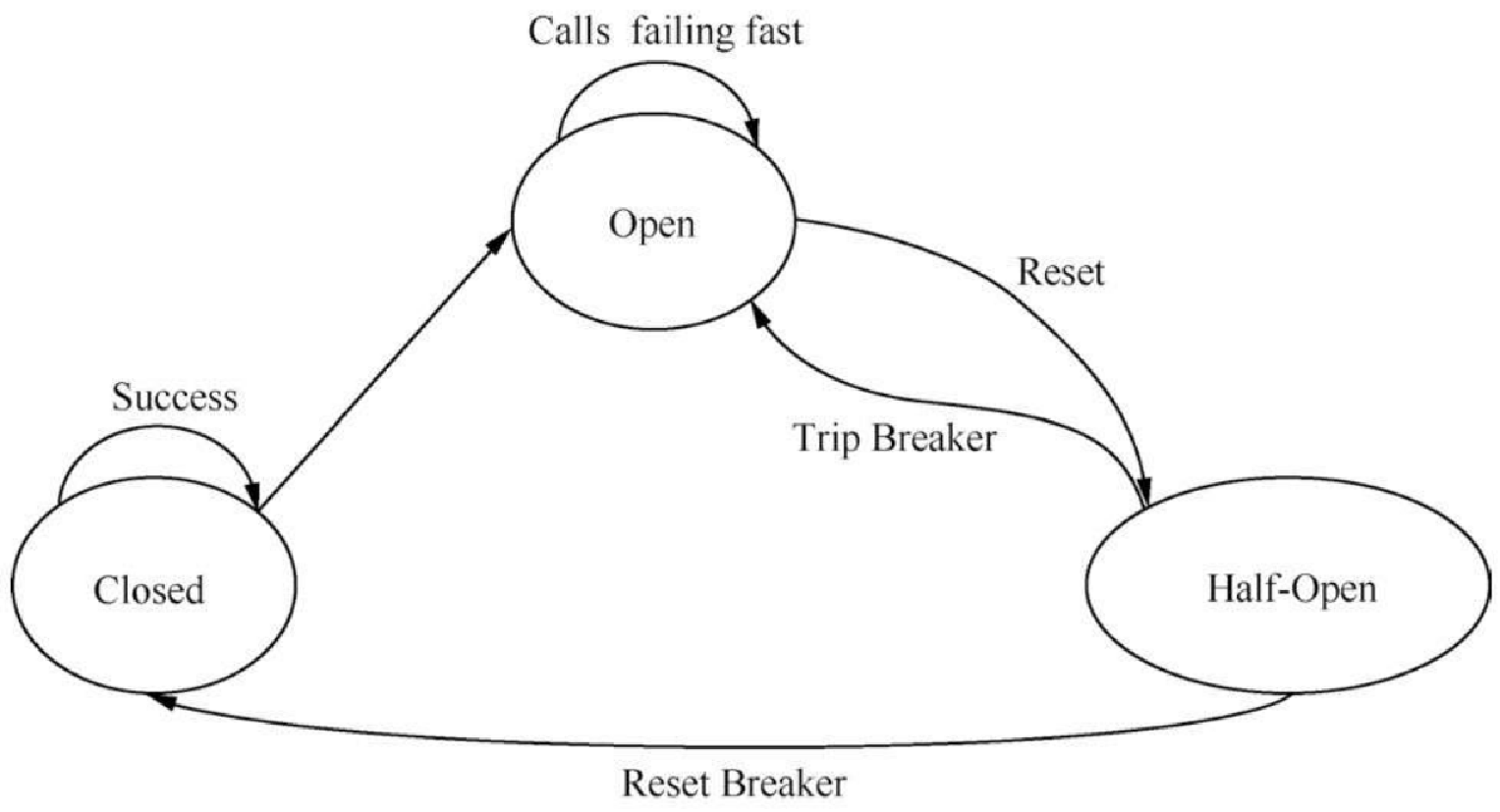
在最开始时,程序处于关闭状态,如果程序出现异常,或者在调用依赖时超时,则程序进入到熔断状态。这时,如果外部有请求出现,都是拒绝状态。一段时间后,这个时间可以设置,然后会进入半熔断状态。这种状态下可以让请求进来尝试,失败则进入熔断状态,如果成功,则进入闭合状态,程序进入正常运行状态。
隔离
在 Hystrix 中有两种隔离,即线程池隔离与信号量隔离。
线程池隔离:通过一个线程池存储请求,然后线程池对请求做一些处理,设置任务的返回处理超时时间,将请求堆积到线程池队列。这种隔离的好处是,每个请求都有自己的线程池,对于突发的流量,不会影响其他的请求。虽然申请线程池,将会消耗一定的资源,但相比较而言我们还是可以接受。
信号量隔离:这里说的信号量就是一个计数器,记录当前多少线程在运行。当请求进来时,先会判断当前的计数器值,如果请求进来时,超过了设置的最大线程数量,则将该请求丢弃;如果不超过,则可以执行,此时计数器值加一。这种方式,虽然可以防止出现雪崩效应,但是对于突发流量,如果超过计数器值,则请求不会请求依赖的服务。