Ribbon的负载均衡器
在11.3节中,只说到了真正的负载均衡还是要在负载均衡器中进行,但是没有仔细说明。在上一章节中,我们可以了解到,在负载均衡时,使用的是 LoadBalancerClient 接口,具体的实现则需要 RibbonLoadBalancerClient,然后具体实现负载均衡则又需要使用新的接口 ILoadBalancer。而且,在上文也说明这是负载均衡器的一个接口。
因此本节会对负载均衡器做一个比较全面的介绍,帮助读者理解 Ribbon 的源码。
AbstractLoadBalancer类
这个类是 ILoadBalancer 接口的一个实现类。代码如下所示。
public abstract class AbstractLoadBalancer implements ILoadBalancer {
public enum ServerGroup{
ALL,
STATUS_UP,
STATUS_NOT_UP
}
public Server chooseServer() {
return chooseServer(null);
}
public abstract List<Server> getServerList(ServerGroup serverGroup);
public abstract LoadBalancerStats getLoadBalancerStats();
}在这个类中定义了一个关于服务实例的枚举数组,定义如下三种类型。
-
ALL:所有的服务实例。
-
STATUS_UP:正常的服务实例。
-
STATUS_NOT_UP:停止服务的服务实例。
然后,外加三个函数,因为后面11.4.2小节要说明的 BaseLoadBalancer 类将会继承这个 AbstractLoadBalancer 类,类关系如图11.10所示。
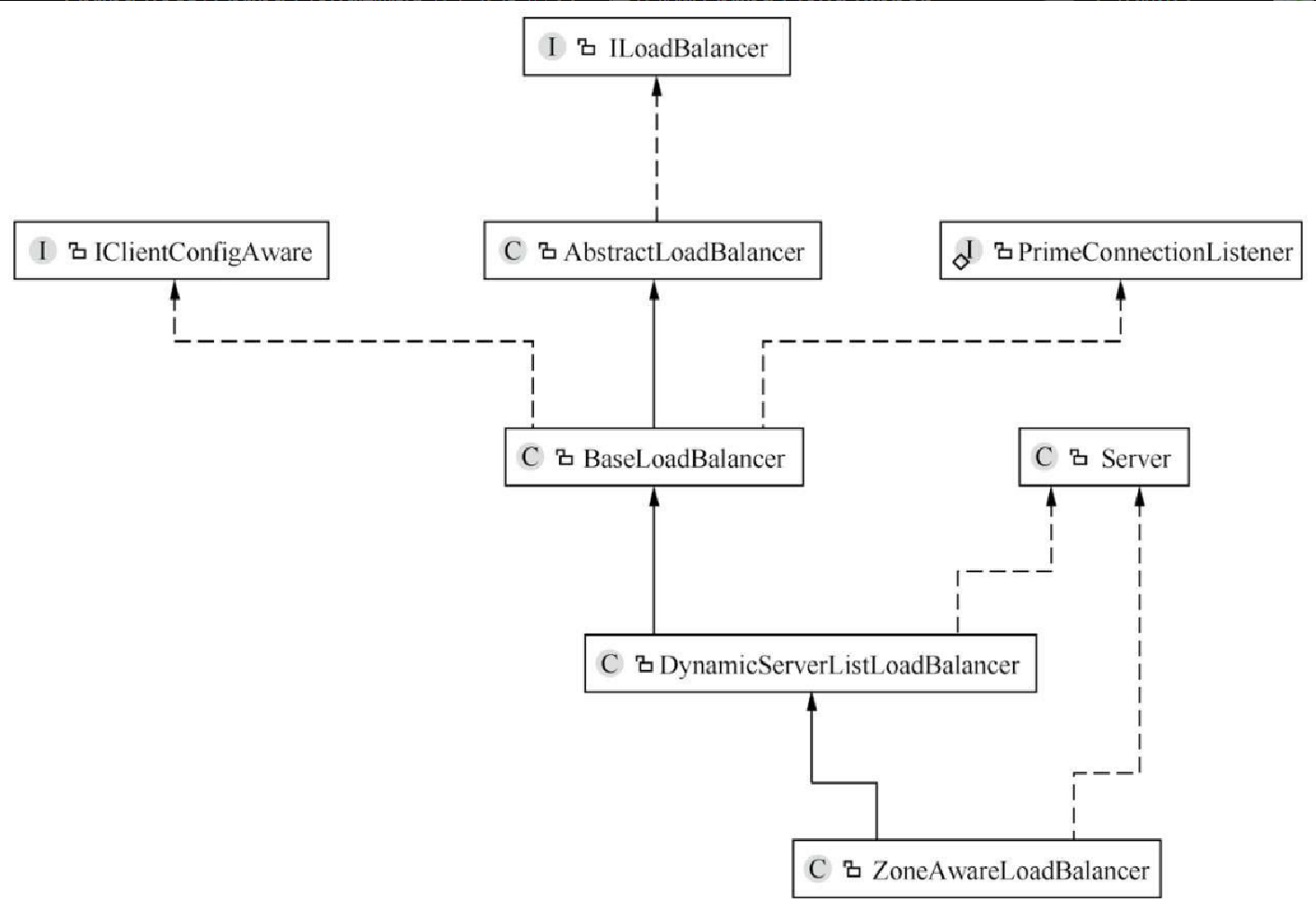
BaseLoadBalancer类
在图11.10中,我们可以看到这个类,是 Ribbon 的基础负载均衡器类,定义了负载均衡器的基本操作。下面针对内部选取一些进行说明。
(1)定义了两个存放服务实例的列表
@Monitor(name = PREFIX + "AllServerList", type =
DataSourceType.INFORMATIONAL)
protected volatile List<Server> allServerList = Collections.synchronizedList(new ArrayList<Server>());
@Monitor(name = PREFIX + "UpServerList", type = DataSourceType. INFORMATIONAL)
protected volatile List<Server> upServerList = Collections.synchronizedList(new ArrayList<Server>());根据上文的代码说明,可以看到两个列表分别是全部的服务实例列表和正常的服务实例列表。
(2)定义 LoadBalancerStats 对象
lbStats = new LoadBalancerStats(DEFAULT_NAME);(3)定义检查服务实例是否正常的 Iping 对象
this.ping = null;在默认情况下是 null。
(4)定义了负载均衡使用的 IRule 规则
代码如下所示。
public void setRule(IRule rule) {
if (rule != null) {
this.rule = rule;
} else {
/* default rule */
this.rule = new RoundRobinRule();
}
if (this.rule.getLoadBalancer() != this) {
this.rule.setLoadBalancer(this);
}
}通过代码可以发现,在 setRule 的时候,默认使用了 RoundRobinRule,意思是线性负载均衡规则。关于具体的实例选择,可以通过 chooseServer 方法进行,这里使用了 rule 的 choose 方法选择服务实例。
(5)启动ping任务
在代码中,会启动一个定时任务,定时检查服务实例代码如下所示。
void setupPingTask() {
if (canSkipPing()) {
return;
}
if (lbTimer != null) {
lbTimer.cancel();
}
lbTimer = new ShutdownEnabledTimer("NFLoadBalancer-PingTimer-"+ name,
true);
lbTimer.schedule(new PingTask(), 0, pingIntervalSeconds * 1000);
forceQuickPing();
}setupPingTask 会写在构造函数中,所以这里直接启动。其中 pingIntervalSeconds 是 10,意味着这里的时间间隔是 10s。
(6)定义负载均衡器的基本操作
内容比较多,建议读者直接看源码。
-
addServers(List newServers):向负载均衡器中增加服务实例列表。
-
chooseServer(Object key):挑选一个具体的服务实例。
-
getReachableServers():获取可用的服务实例列表。
-
getAllServers():获取所有的服务实例列表。
DynamicServerListLoadBalancer类
这个类在图11.10也可以看到,继承了基础类 BaseLoadBalancer,属于扩展类。这个类比较重要,它实现了服务实例清单动态更新,是服务发现中的核心。在这个类中,还有一个重要的功能,就是过滤,它可以选择性地获取服务实例。
ServerList
这里介绍服务实例列表。在类中有下面的一段代码。
public ServerList<T> getServerListImpl() {
return serverListImpl;
}
volatile ServerList<T> serverListImpl;上文的代码中,有一个获取服务实例列表的函数,返回的是一个 ServerList 的对象,然后我们看看这个对象,会发现是一个接口,代码如下所示。
public interface ServerList<T extends Server> {
public List<T> getInitialListOfServers();
public List<T> getUpdatedListOfServers();
}在上文的代码中,可以发现接口中定义了两个抽象方法,第一个方法是获取初始化的服务实例列表;第二个方法是获取更新后的服务实例列表。
然后,我们将会发现,这个接口中有五个子类,在 Spring Cloud 中使用的是 DomainExtractingServerList。至于为什么是这个类,可以从 EurekaRibbonClientConfiguration 类的方法的 RibbonServerList 中找到结果。现在看看 DomainExtractingServerList 中的具体实现方式,代码如下所示。
@Override
public List<DiscoveryEnabledServer> getInitialListOfServers() {
List<DiscoveryEnabledServer> servers = setZones(this.list
.getInitialListOfServers());
return servers;
}
@Override
public List<DiscoveryEnabledServer> getUpdatedListOfServers() {
List<DiscoveryEnabledServer> servers = setZones(this.list
.getUpdatedListOfServers());
return servers;
}
public DomainExtractingServerList(ServerList<DiscoveryEnabledServer> list,
IClientConfig clientConfig, boolean approximateZoneFromHostname) {
this.list = list;
this.ribbon = RibbonProperties.from(clientConfig);
this.approximateZoneFromHostname = approximateZoneFromHostname;
}对于上文的代码,最开始我们都能发现有两个实现方法,返回两种列表。然后在最下面,看到构造函数时,使用的是 ServerList,就是说在进行构造时,需要把返回的列表信息写入。
在构造函数的时候加入了 DiscoveryEnabledServer。其中,DiscoveryEnabledServer 包含了 InstanceInfo,这个类在前面说过,它包含了服务实例需要的基本信息。
在上面的两个实现方法中都存在 setZones,代码如下所示。
private List<DiscoveryEnabledServer> setZones(List<DiscoveryEnabled Server> servers) {
List<DiscoveryEnabledServer> result = new ArrayList<>();
boolean isSecure = this.ribbon.isSecure(true);
boolean shouldUseIpAddr = this.ribbon.isUseIPAddrForServer();
for (DiscoveryEnabledServer server : servers) {
result.add(new DomainExtractingServer(server, isSecure, shouldUseIpAddr,
this.approximateZoneFromHostname));
}
return result;
}ServerListUpdater
这里介绍服务更新器,我们需要了解 DynamicServerListLoadBalancer 类,在这里面我们可以看到有这部分代码,主要用于对列表的更新,代码如下所示。
protected final ServerListUpdater.UpdateAction updateAction = new ServerListUpdater.UpdateAction() {
@Override
public void doUpdate() {
updateListOfServers();
}
};这里先不看 updateListOfServers 具体的实现方法,因为这里面涉及过滤器,在后面再介绍。这里主要介绍 ServerListUpdater 接口,因为其在上面是覆盖了 doUpdate 方法。来看这个接口的主要抽象方法,代码如下所示。
public interface ServerListUpdater {
public interface UpdateAction {
void doUpdate();
}
void start(UpdateAction updateAction);
void stop();
String getLastUpdate();
long getDurationSinceLastUpdateMs();
int getNumberMissedCycles();
int getCoreThreads();
}上面是接口的抽象方法,先说明如下几个方法。
-
start:启动服务更新器,具体的实现是 UpdateAction。
-
stop:停止服务更新器。
-
getLastUpdate:获取最近一次更新的时间。
-
getDurationSinceLastUpdateMs:获取上次更新到目前的时间间隔。
-
getNumberMissedCycles:获取错过的周期数。
-
getCoreThreads:获取线程数。
最后介绍接口的实现类。通过 IDEA,发现它只有两个实现类,分别是 EurekaNotificationServerListUpdater 和 PollingServerListUpdater。
-
EurekaNotificationServerListUpdater:这种触发需要通过 Eureka 的事件监听来驱动服务列表进行更新。
-
PollingServerListUpdater:这是默认的策略。
下面看看这个接口是怎么定时更新服务实例列表的。代码如下所示。
public synchronized void start(final UpdateAction updateAction) {
if (isActive.compareAndSet(false, true)) {
final Runnable wrapperRunnable = new Runnable() {
@Override
public void run() {
if (!isActive.get()) {
if (scheduledFuture != null) {
scheduledFuture.cancel(true);
}
return;
}
try {
updateAction.doUpdate();
lastUpdated = System.currentTimeMillis();
} catch (Exception e) {
logger.warn("Failed one update cycle", e);
}
}
};
scheduledFuture = getRefreshExecutor().scheduleWithFixedDelay(
wrapperRunnable,
initialDelayMs,
refreshIntervalMs,
TimeUnit.MILLISECONDS
);
} else {
logger.info("Already active, no-op");
}
}上面就是定时更新服务实例列表的线程实现,里面使用 updateAction.daoUpdate 进行实现。
ServerListFilter
刚才在讲解更新服务实例列表时,没有讲解具体的实现方式,因为里面存在过滤器,其实使用的过滤器就是这个 ServerListFilter 接口。首先,我们看看这个方法,代码如下所示。
public void updateListOfServers() {
List<T> servers = new ArrayList<T>();
if (serverListImpl != null) {
servers = serverListImpl.getUpdatedListOfServers();
LOGGER.debug("List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
if (filter != null) {
servers = filter.getFilteredListOfServers(servers);
LOGGER.debug("Filtered List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
}
}
updateAllServerList(servers);
}在上文的代码中,引入了 Filter。在上文介绍过 ServerList,用于获取服务实例列表。在这里将会使用过滤器对服务实例列表进行过滤。
服务注册
在介绍完服务发现后,再说明如何进行服务注册。根据 DiscoveryClient 的说明,我们同样需要进入这个类查找源码。这个类是构造类,进入构造类中,过滤判断条件代码后,留下如下代码。
DiscoveryClient(ApplicationInfoManager applicationInfoManager, EurekaClientConfig config, AbstractDiscoveryClientOptionalArgs args,
Provider<BackupRegistry> backupRegistryProvider) {
//省略一部分代码
// finally, init the schedule tasks (e.g. cluster resolvers, heartbeat, instanceInfo replicator, fetch
initScheduledTasks();
//省略一部分代码
}上面的方法是初始化任务。我们进入这个方法,代码如下所示。
/**
* Initializes all scheduled tasks.
*/
private void initScheduledTasks() {
//省略一部分代码
if (clientConfig.shouldRegisterWithEureka()) {
//省略一部分代码
// InstanceInfo replicator
instanceInfoReplicator = new InstanceInfoReplicator(
this,
instanceInfo,
clientConfig.getInstanceInfoReplicationIntervalSeconds(),
2); // burstSize
//省略一部分代码instanceInfoReplicator.start(clientConfig.getInitialInstanceInfoReplicat ionIntervalSeconds());
} else {
logger.info("Not registering with Eureka server per configuration");
}
}在上面的代码中,将会创建一个 InstanceInfoReplicator 类的实例,并且会执行一个定时任务,在这里会真正触发服务注册。关于定时任务,可以进入 InstanceInfoReplicator 类中查看,主要的 run 函数代码如下所示。
public void run() {
try {
discoveryClient.refreshInstanceInfo();
Long dirtyTimestamp = instanceInfo.isDirtyWithTime();
if (dirtyTimestamp != null) {
discoveryClient.register();
instanceInfo.unsetIsDirty(dirtyTimestamp);
}
} catch (Throwable t) {
logger.warn("There was a problem with the instance info replicator", t);
} finally {
Future next = scheduler.schedule(this, replicationIntervalSeconds, TimeUnit.SECONDS);
scheduledPeriodicRef.set(next);
}
}加粗的部分就是注册。如果进入这个方法,将会发现使用了 Rest 请求方式,同时传入元数据 instanceInfo。