HTML、DOM树表示以及XPath
让我们花费一些时间来了解从用户在浏览器中输入 URL(或者更常见的是,在其单击链接或书签时)到屏幕上显示出页面的过程。从本书的视角来看,该过程包含 4 个步骤,如图2.1所示。

-
在浏览器中输入 URL。URL 的第一部分(域名,比如 gumtree.com)用于在网络上找到合适的服务器,而 URL 以及 cookie 等其他数据则构成了一个请求,用于发送到那台服务器当中。
-
服务端回应,向浏览器发送一个 HTML 页面。需要注意的是,服务端也可能返回其他格式,比如 XML 或 JSON,不过目前我们只关注 HTML。
-
将 HTML 转换为浏览器内部的树状表示形式:文档对象模型(Document Object Model,DOM)。
-
基于一些布局规则渲染内部表示,达到你在屏幕上看到的视觉效果。
下面来看看这些步骤,以及它们所需的文档表示。这将有助于定位你想要抓取并编写程序获取的文本。
URL
对于我们而言,URL 分为两个主要部分。第一个部分通过域名系统(Domain Name System,DNS)帮助我们在网络上定位合适的服务器。比如,当在浏览器中发送 https://mail.google.com/mail/u/0/#inbox 时,将会创建一个对 mail.google.com 的 DNS 请求,用于确定合适的服务器 IP 地址,如 173.194.71.83。从本质上来看, https://mail.google.com/mail/u/0/#inbox 被翻译为 https://173.194.71.83/mail/u/0/#inbox 。
URL 的剩余部分对于服务端理解请求是什么非常重要。它可能是一张图片、一个文档,或是需要触发某个动作的东西,比如向服务器发送邮件。
HTML文档
服务端读取 URL,理解我们的请求是什么,然后回应一个 HTML 文档。该文档实质上就是一个文本文件,我们可以使用 TextMate、Notepad、vi 或 Emacs 打开它。和大多数文本文档不同,HTML 文档具有由万维网联盟指定的格式。该规范当然已经超出了本书的范畴,不过还是让我们看一个简单的 HTML 页面。当访问 http://example.com 时,可以在浏览器中选择 View Page Source(查看页面源代码)以看到与其相关的 HTML 文件。在不同的浏览器中,具体的过程是不同的;在许多系统中,可以通过右键单击找到该选项,并且大部分浏览器在你按下 Ctrl + U 快捷键(或 Mac 系统中的 Cmd + U)时可以显示源代码。
|
在一些页面中,该功能可能无法使用。此时,需要通过单击 Chrome 菜单,然后选择 Tools | View Source 才可以。 |
下面是 http://example.com 目前的 HTML 源代码。
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width,
initial-scale=1" />
<style type="text/css">body { background-color: ... } }</style>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is established to be used for illustrative examples examples in documents. You may use this domain in examples without prior coordination or asking for permission.</p>
<p>
<a href="http://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>我将这个 HTML 文档进行了格式化,使其更具可读性,而你看到的情况可能是所有文本在同一行中。在 HTML 中,空格和换行在大多数情况下是无关紧要的。
尖括号中间的文本(比如 <html> 或 <head>)被称为标签。<html> 是起始标签,而 </html> 是结束标签。这两种标签的唯一区别是/字符。这说明,标签是成对出现的。虽然一些网页对于结束标签的使用比较粗心(比如,为独立的段落使用单一的 <p> 标签),但是浏览器有很好的容忍度,并且会尝试推测结束的 </p> 标签应该在哪里。
<p> 和 </p> 标签中的所有东西被称为 HTML 元素。请注意,元素中可能还包括其他元素,比如示例中的 <div> 元素,或是包含 <a> 元素的第二个 <p> 元素。
有些标签会更加复杂,比如 <a href="http://www.iana.org/domains/example">。含有 URL 的 href 部分被称为属性。
最后,许多元素还包含文本,比如 <h1> 元素中的 "Example Domain"。
对于我们来说,好消息是这些标签并不都是重要的。唯一可见的东西是 body 元素中的元素, 即 <body> 和 </body> 标签之间的元素。<head> 部分对于指明诸如字符编码的元信息来说非常重要,不过 Scrapy 能够处理大部分此类问题,所以很多情况下不需要关注 HTML 页面的这个部分。
树表示法
每个浏览器都有其自身复杂的内部数据结构,凭借它来渲染网页。DOM 表示法具有跨平台、语言无关性等特点,并且被大多数浏览器所支持。
想要在 Chrome 中查看网页的树表示法,可以右键单击你感兴趣的元素,然后选择 Inspect Element。如果该功能被禁用,你仍然可以通过单击 Chrome 菜单并选择 Tools | Developer Tools 来访问它,如图2.2所示。
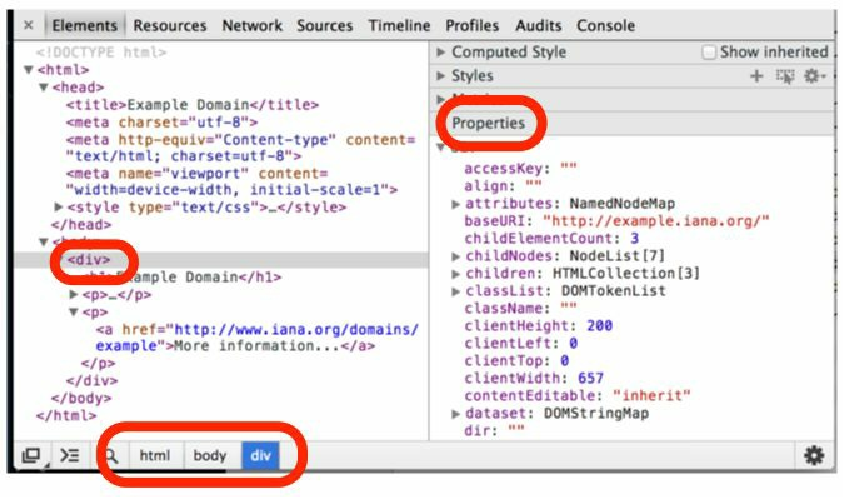
此时,你可以看到一些看起来和 HTML 表示非常相似但又不完全相同的东西。它就是 HTML 代码的树表示法。如果不管原始 HTML 文档是如何使用空格和换行符的话,它看起来几乎就是一样的。你可以单击每个元素,检查或调整属性等,同时可以在屏幕上观察这些变动有何影响。比如,当你双击某个文本,修改它,并按下回车键时,屏幕上的文本将会更新为这个新值。在右侧的 Properties 标签下,可以看到这个树表示法的属性,并且在底部可以看到一个类似面包屑的结构,它显示出了当前选择的元素在 HTML 元素层次结构中的确切位置,如图2.3所示。
需要注意的一个重要事情是,HTML 只是文本,而树表示法是浏览器内存里的对象,你可以通过编程的方式查看并操纵它,比如在 Chrome 中使用 Developer Tools。
你会在屏幕上看到什么
HTML 文本表示和树表示并不包含任何像我们通常在屏幕上看到的那种漂亮视图。这实际上是 HTML 成功的原因之一。它应该是一个由人类阅读的文档,并且可以指定页面中的内容,而不是用于在屏幕中渲染的方式。这意味着选择 HTML 文档并使其更加好看是浏览器的责任,不管它是诸如 Chrome 的全功能浏览器、移动设备浏览器,甚至是诸如 Lynx 的纯文本浏览器。
也就是说,网络的发展促使 Web 开发者和用户对网页渲染的控制产生了巨大需求。CSS 的创建就是为了对 HTML 元素如何渲染给予提示。不过,对于抓取而言,我们并不需要任何和 CSS 相关的东西。
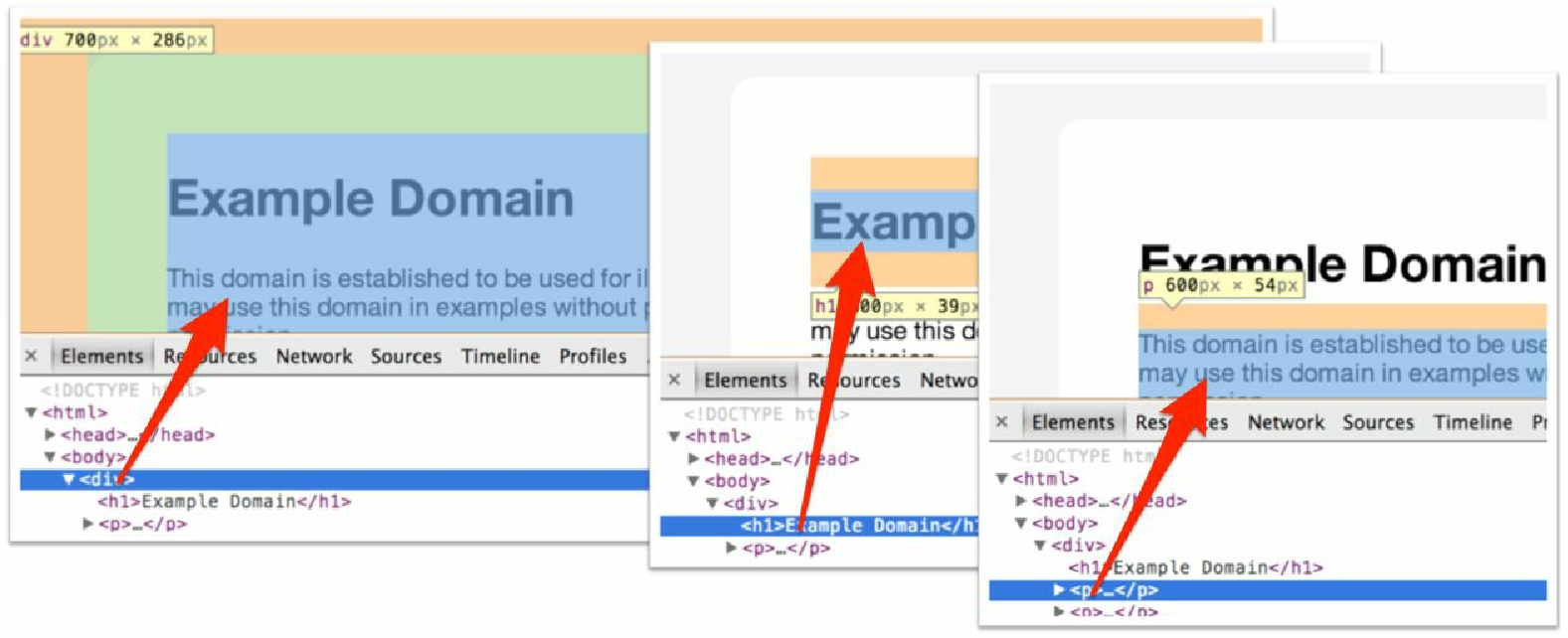
那么,树表示法是如何映射到我们在屏幕上所看到的东西呢?答案就是框模型。正如 DOM 树元素可以包含其他元素或文本一样,默认情况下,当在屏幕上渲染时,每个元素的框表示同样也都包含其嵌入元素的框表示。从这种意义上说,我们在屏幕上所看到的是原始 HTML 文档的二维表示——树结构也以一种隐藏的方式作为该表示的一部分。比如,在图2.4中,我们可以看到 3 个 DOM 元素(一个 <div> 和两个嵌入元素 <h1> 和 <p>)是如何在浏览器和 DOM 中呈现的。