Scrapy是一个Twisted应用
Scrapy 是一个内置使用了 Python 的 Twisted 框架的抓取应用。Twisted 确实有些与众不同,因为它是事件驱动的,并且鼓励我们编写异步代码。习惯它需要一些时间,不过我们将通过只学习和 Scrapy 有关的部分,从而让任务变得相对简单一些。我们还可以在错误处理方面轻松一些。GitHub 上的完整代码会有更加彻底的错误处理,不过在本书中将忽略该部分。
让我们从头开始。Twisted 与众不同是因为它的主要口号。
|
在任何情况下,都不要编写阻塞的代码。 |
代码阻塞的影响很严重,而可能造成代码阻塞的原因包括:
-
代码需要访问文件、数据库或网络;
-
代码需要派生新进程并消费其输出,比如运行 shell 命令;
-
代码需要执行系统级操作,比如等待系统队列。
Twisted 提供的方法允许我们执行上述所有操作甚至更多操作时,无需再阻塞代码执行。
为了展示两种方式的不同,我们假设有一个典型的同步抓取应用(见图8.1)。假设该应用包含 4 个线程,并且在一个给定的时刻,其中 3 个线程处于阻塞状态,用于等待响应,而另一个线程被阻塞,用于执行数据库写访问以保存 Item。在任何给定时刻,很有可能无法找到抓取应用的一个执行其他事情的线程,只能等待一些阻塞操作完成。当阻塞操作完成时,一些计算操作可能占用几微秒,然后线程再次被阻塞,执行其他阻塞操作,这很可能持续至少几毫秒的时间。总体来说,服务器不会是空闲的,因为它运行了几十个应用程序,并使用了上千个线程,因此,在一些细致的调优后,CPU 才能够合理利用。
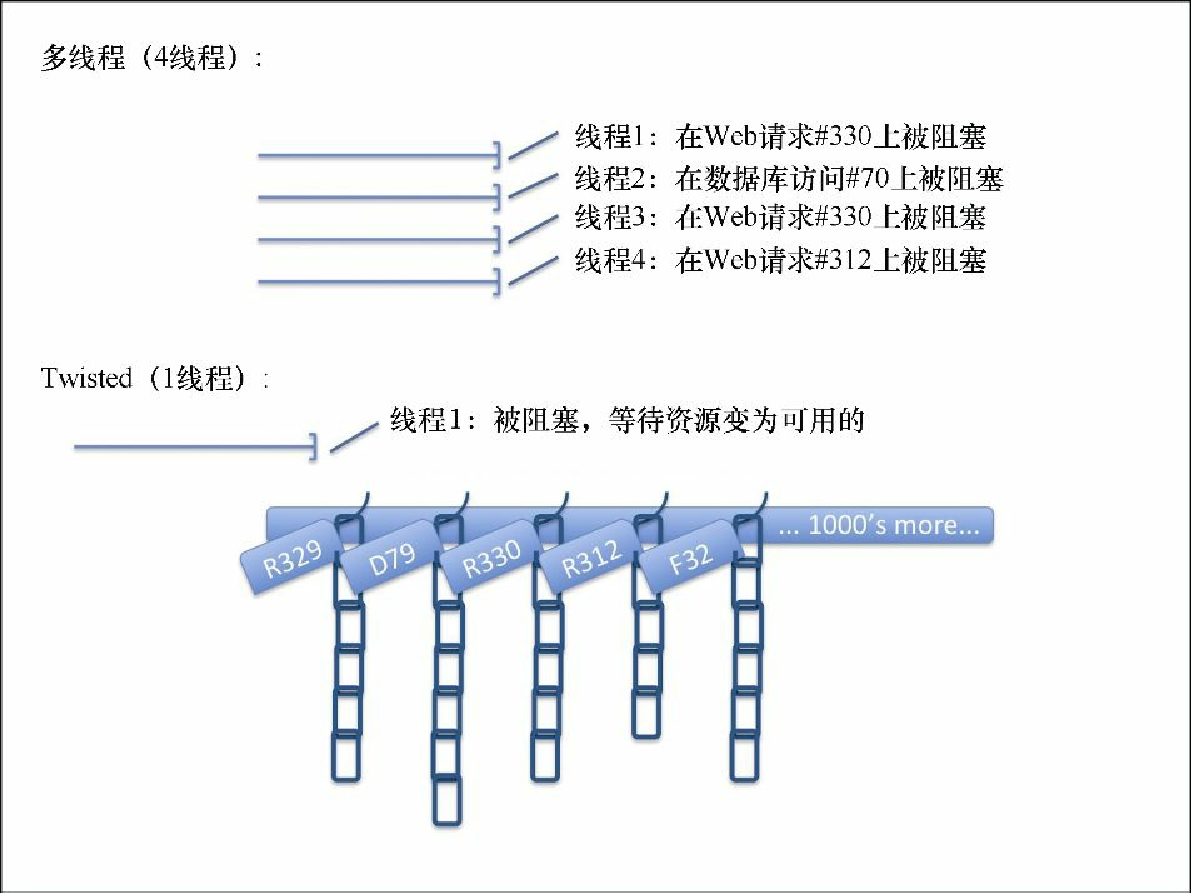
Twisted/Scrapy 的方式更倾向于尽可能使用单线程。它使用现代操作系统的 I/O 复用功能(参见 select()、poll() 和 epoll())作为 “挂起器”。在通常会有阻塞操作的地方,比如 result = i_block(),Twisted 提供了一个可以立即返回的替代实现。不过,它并不是返回真实值,而是返回一个 hook,比如 deferred = i_dont_block(),在这里可以挂起任何想要运行的功能,而不用管什么时候返回值可用(比如,deferred.addCallback(process_result))。一个 Twisted 应用是由一组此类延迟运行的操作组成的。Twisted 唯一的主线程被称为 Twisted 事件反应器线程,用于监控挂起器,等待某个资源变为可用(比如,服务器返回响应到我们的 Request 中)。当该事件发生时,将会触发链中最前面的延迟操作,执行一些计算,然后依次触发下面的操作。部分延迟操作可能会引发进一步的 I/O 操作,这样就会造成延迟操作链回到挂起器中,如果可能的话,还会释放 CPU 以执行其他功能。由于我们使用的是单线程,因此不会存在额外线程所需的上下文切换以及保存资源(如内存)所带来的开销。也就是说,我们使用该非阻塞架构时,只需一个线程,就能达到类似使用数千个线程才能达到的性能。
坦率地说,操作系统开发人员花费了数十年的时间优化线程操作,以使它们速度更快。性能的争论没有以前那么强烈了。有一件大家都认同的事情是,为复杂应用编写正确的线程安全代码非常困难。当你克服考虑延迟/回调所带来的最初冲击后,会发现 Twisted 代码要比多线程代码简单得多。inlineCallbacks 生成器工具使得代码更加简单,我们将会在后续章节进一步讨论它。
|
可以说,到目前为止,最成功的非阻塞 I/O 系统是 Node.js,主要是因为它以高性能和并发性作为出发点,没有人去争论这是好事还是坏事。每个 Node.js 应用都只用非阻塞 API。在 Java 的世界里,Netty 可能是最成功的 NIO 框架驱动应用,比如 Apache Storm 和 Spark。C++ 11 的 std::future 和 std::promise(与延迟操作非常类似)通过使用 libevent 或纯 POSIX 这些库,使得编写异步代码更加简单。 |
延迟和延迟链
延迟机制是 Twisted 提供的最基础的机制,能够帮助我们编写异步代码。Twisted API 使用延迟机制,允许我们定义发生某些事件时所采取的动作序列。下面让我们具体看一下。
|
你可以从 GitHub 上获取本书的全部源代码。如果想要下载本书代码,可以使用 git clone https://github.com/scalingexcellence/scrapybook。 本章的完整代码在 ch08 目录中,其中本示例的代码在 ch08/deferreds.py 文件中,你可以使用 ./deferreds.py 0 运行该代码。 |
可以使用 Python 控制台运行如下的交互式实验。
$ python
>>> from twisted.internet import defer
>>> # Experiment 1
>>> d = defer.Deferred()
>>> d.called
False
>>> d.callback(3)
>>> d.called
True
>>> d.result
3可以看到,Deferred 本质上代表的是一个无法立即获取的值。当触发 d 时(调用其 callback 方法),其 called 状态变为 True,而 result 属性被设置为在回调方法中设定的值。
>>> # Experiment 2
>>> d = defer.Deferred()
>>> def foo(v):
... print "foo called"
... return v+1
...
>>> d.addCallback(foo)
<Deferred at 0x7f...>
>>> d.called
False
>>> d.callback(3)
foo called
>>> d.called
True
>>> d.result
4延迟机制最强大的功能就是可以在设定值时串联其他要被调用的操作。在上面的例子中,添加了一个 foo() 函数作为 d 的回调函数。当通过调用 callback(3) 触发 d 时,会调用函数 foo(),打印消息,并将其返回值设为 d 最终的 result 值。
>>> # Experiment 3
>>> def status(*ds):
... return [(getattr(d, 'result', "N/A"), len(d.callbacks)) for d in
ds]
>>> def b_callback(arg):
... print "b_callback called with arg =", arg
... return b
>>> def on_done(arg):
... print "on_done called with arg =", arg
... return arg
>>> # Experiment 3.a
>>> a = defer.Deferred()
>>> b = defer.Deferred()
>>> a.addCallback(b_callback).addCallback(on_done)
>>> status(a, b)
[('N/A', 2), ('N/A', 0)]
>>> a.callback(3)
b_callback called with arg = 3
>>> status(a, b)
[(<Deferred at 0x10e7209e0>, 1), ('N/A', 1)]
>>> b.callback(4)
on_done called with arg = 4
>>> status(a, b)
[(4, 0), (None, 0)]该示例展示了更加复杂的延迟行为。我们看到该示例中有一个普通的延迟 a,和之前例子中创建的一样,不过这次它有两个回调方法。第一个是 b_callback(),返回值是另一个延迟 b,而不是一个值。第二个是 on_done() 打印函数。我们还有一个 status() 函数,用于打印延迟状态。在两个延迟完成初始化之后,得到了相同的状态:[('N/A', 2), ('N/A', 0)],这意味着两个延迟都还没有被触发,并且第一个延迟有两个回调,而第二个没有回调。然后,当触发第一个延迟时,我们得到了一个奇怪的 [(<Deferred at 0x10e7209e0>, 1), ('N/A', 1)] 状态,可以看出现在 a 的值是一个延迟(实际上就是 b 延迟),并且目前它还有一个回调,这种情况是合理的,因为 b_callback() 已经被调用,只剩下了 on_done()。意外的情况是现在 b 也包含了一个回调。实际上是在后台注册了一个回调,一旦触发 b,就会更新它的值。当其发生时,on_done() 依然会被调用,并且最终状态会是 [(4, 0),(None, 0)],和我们预期的一样。
>>> # Experiment 3.b
>>> a = defer.Deferred()
>>> b = defer.Deferred()
>>> a.addCallback(b_callback).addCallback(on_done)
>>> status(a, b)
[('N/A', 2), ('N/A', 0)]
>>> b.callback(4)
>>> status(a, b)
[('N/A', 2), (4, 0)]
>>> a.callback(3)
b_callback called with arg = 3
on_done called with arg = 4
>>> status(a, b)
[(4, 0), (None, 0)]而另一方面,如果像 Experiment3.b 所示,b 先于 a 被触发,状态将会变为 [('N/A', 2), (4, 0)],然后当 a 被触发时,两个回调都会被调用,最终状态与之前一样。有意思的是,不管顺序如何,最终结果都是相同的。两个例子唯一的不同是,在第一个例子中,b 值保持延迟的时间更长一些,因为它是第二个被触发的,而在第二个例子中,b 首先被触发,并且从该时刻起,它的值就会在需要时被立即使用。
此时,你应该已经对什么是延迟、它们是如何串联起来表示尚不可用的值,有了不错的理解。我们将通过第 4 个例子结束这一部分的研究,在该示例中,将展示如何触发依赖于多个其他延迟的方法。在 Twisted 的实现中,将会使用 defer.DeferredList 类。
>>> # Experiment 4
>>> deferreds = [defer.Deferred() for i in xrange(5)]
>>> join = defer.DeferredList(deferreds)
>>> join.addCallback(on_done)
>>> for i in xrange(4):
... deferreds[i].callback(i)
>>> deferreds[4].callback(4)
on_done called with arg = [(True, 0), (True, 1), (True, 2),
(True, 3), (True, 4)]可以注意到,尽管 for 循环语句只触发了 5 个延迟中的 4 个,on_done() 仍然需要等到列表中所有延迟都被触发后才会调用,也就是说,要在最后的 deferreds[4].callback() 之后调用。on_done() 的参数是一个元组组成的列表,每个元组对应一个延迟,其中包含两个元素,分别是表示成功的 True 或表示失败的 False,以及延迟的值。
理解Twisted和非阻塞I/O——一个Python故事
既然我们已经掌握了原语,接下来让我告诉你一个 Python 的小故事。该故事中所有人物均为虚构,如有雷同纯属巧合。
# ~*~ Twisted - A Python tale ~*~
from time import sleep
# Hello, I'm a developer and I mainly setup Wordpress.
def install_wordpress(customer):
# Our hosting company Threads Ltd. is bad. I start installation and...
print "Start installation for", customer
# ...then wait till the installation finishes successfully. It is
# boring and I'm spending most of my time waiting while consuming
# resources (memory and some CPU cycles). It's because the process
# is *blocking*.
sleep(3)
print "All done for", customer
# I do this all day long for our customers
def developer_day(customers):
for customer in customers:
install_wordpress(customer)
developer_day(["Bill", "Elon", "Steve", "Mark"])运行该代码。
$ ./deferreds.py 1
------ Running example 1 ------
Start installation for Bill
All done for Bill
Start installation
...
* Elapsed time: 12.03 seconds我们得到的是顺序的执行。4 位客户,每人执行 3 秒,意味着总共需要 12 秒的时间。这种方式的扩展性不是很好,因此我们将在第二个例子中添加多线程。
import threading
# The company grew. We now have many customers and I can't handle the
# workload. We are now 5 developers doing exactly the same thing.
def developers_day(customers):
# But we now have to synchronize... a.k.a. bureaucracy
lock = threading.Lock()
#
def dev_day(id):
print "Goodmorning from developer", id
# Yuck - I hate locks...
lock.acquire()
while customers:
customer = customers.pop(0)
lock.release()
# My Python is less readable
install_wordpress(customer)
lock.acquire()
lock.release()
print "Bye from developer", id
# We go to work in the morning
devs = [threading.Thread(target=dev_day, args=(i,)) for i in range(5)]
[dev.start() for dev in devs]
# We leave for the evening
[dev.join() for dev in devs]
# We now get more done in the same time but our dev process got more
# complex. As we grew we spend more time managing queues than doing dev
# work. We even had occasional deadlocks when processes got extremely
# complex. The fact is that we are still mostly pressing buttons and
# waiting but now we also spend some time in meetings.
developers_day(["Customer %d" % i for i in xrange(15)])按照下述方式运行这段代码。
$ ./deferreds.py 2
------ Running example 2 ------
Goodmorning from developer 0Goodmorning from developer
1Start installation forGoodmorning from developer 2
Goodmorning from developer 3Customer 0
...
from developerCustomer 13 3Bye from developer 2
* Elapsed time: 9.02 seconds在这段代码中,使用了 5 个线程并行执行。15 个客户,每人 3 秒,总共需要执行45秒, 而当使用 5 个并行的线程时,最终只花费了 9 秒钟。不过代码有些难看。现在代码的一部分只用于管理并发性,而不是专注于算法或业务逻辑。另外,输出也变得混乱并且可读性很差。即使是让很简单的多线程代码正确运行,也有很大难度,因此我们将转为使用 Twisted。
# For years we thought this was all there was... We kept hiring more
# developers, more managers and buying servers. We were trying harder
# optimising processes and fire-fighting while getting mediocre
# performance in return. Till luckily one day our hosting
# company decided to increase their fees and we decided to
# switch to Twisted Ltd.!
from twisted.internet import reactor
from twisted.internet import defer
from twisted.internet import task
# Twisted has a slightly different approach
def schedule_install(customer):
# They are calling us back when a Wordpress installation completes.
# They connected the caller recognition system with our CRM and
# we know exactly what a call is about and what has to be done
# next.
## We now design processes of what has to happen on certain events.
def schedule_install_wordpress():
def on_done():
print "Callback: Finished installation for", customer
print "Scheduling: Installation for", customer
return task.deferLater(reactor, 3, on_done)
#
def all_done(_):
print "All done for", customer
#
# For each customer, we schedule these processes on the CRM
# and that
# is all our chief-Twisted developer has to do
d = schedule_install_wordpress()
d.addCallback(all_done)
#
return d
# Yes, we don't need many developers anymore or any synchronization.
# ~~ Super-powered Twisted developer ~~
def twisted_developer_day(customers):
print "Goodmorning from Twisted developer"
#
# Here's what has to be done today
work = [schedule_install(customer) for customer in customers]
# Turn off the lights when done
join = defer.DeferredList(work)
join.addCallback(lambda _: reactor.stop())
#
print "Bye from Twisted developer!"
# Even his day is particularly short!
twisted_developer_day(["Customer %d" % i for i in xrange(15)])
# Reactor, our secretary uses the CRM and follows-up on events!
reactor.run()现在运行该代码。
$ ./deferreds.py 3
------ Running example 3 ------
Goodmorning from Twisted developer
Scheduling: Installation for Customer 0
....
Scheduling: Installation for Customer 14
Bye from Twisted developer!
Callback: Finished installation for Customer 0
All done for Customer 0
Callback: Finished installation for Customer 1
All done for Customer 1
...
All done for Customer 14
* Elapsed time: 3.18 seconds此时,我们在没有使用多线程的情况下,就获得了良好运行的代码,以及漂亮的输出结果。我们并行处理了所有的 15 位客户,也就是说,应当执行 45 秒的计算只花费了 3 秒钟!技巧就是将所有阻塞调用的 sleep() 替换为 Twisted 对应的 task.deferLater() 以及回调函数。由于处理现在发生在其他地方,因此可以毫不费力地同时为 15 位客户服务。
|
刚才提到前面的处理此时是在其他地方执行的。这是在作弊吗? 答案当然不是。算法计算仍然在 CPU 中处理,不过与磁盘和网络操作相比,CPU 操作速度很快。因此,将数据传给 CPU、从一个 CPU 发送或存储数据到另一个 CPU 中,占据了大部分时间。我们使用非阻塞的 I/O 操作,为 CPU 节省了这些时间。这些操作,尤其是像 task.deferLater() 这样的操作,会在数据传输完成后触发回调函数。 |
另一个需要非常注意的地方是 Goodmorning from Twisted developer 以及 Bye from Twisted developer! 消息。在代码启动时,它们就都被立即打印了出来。 如果代码过早地到达该点,那么应用实际是什么时候运行的呢? 答案是 Twisted 应用(包括 Scrapy) 完全运行在 reactor.run() 上!当调用该方法时,必须拥有应用程序预期使用的所有可能的延迟链(相当于前面故事中建立 CRM 系统的步骤和流程)。你的 reactor.run()(故事中的秘书)执行事件监控以及触发回调。
|
reactor 的主要规则是:只要是快速的非阻塞操作就可以做任何事。 |
非常好!不过虽然代码没有了多线程时的混乱输出,但是这里的回调函数还是有一些难看!因此,我们将引入下一个例子。
# Twisted gave us utilities that make our code way more readable!
@defer.inlineCallbacks
def inline_install(customer):
print "Scheduling: Installation for", customer
yield task.deferLater(reactor, 3, lambda: None)
print "Callback: Finished installation for", customer
print "All done for", customer
def twisted_developer_day(customers):
... same as previously but using inline_install()
instead of schedule_install()
twisted_developer_day(["Customer %d" % i for i in xrange(15)])
reactor.run()以如下方式运行该代码。
$ ./deferreds.py 4
... exactly the same as before上述代码和之前那个版本的代码看起来基本一样,不过更加优雅。inlineCallbacks 生成器使用了一些 Python 机制让 inline_install() 的代码能够暂停和恢复。inline_install() 变为延迟函数,并且为每位客户并行执行。每当执行 yield 时,执行会在当前的 inline_install() 实例上暂停,当 yield 的延迟函数触发时再恢复。
现在唯一的问题是,如果不是只有 15 个客户,而是 10000 个,该代码会无耻地同时启动 10000 个处理序列(调用 HTTP 请求、数据库写操作等)。这样可能会正常运行, 也可能造成各种各样的失败。在大规模并发应用中,比如 Scrapy,一般需要将并发量限制到可接受的水平。在本例中,可以使用 task.Cooperator() 实现该限制。Scrapy 使用了同样的机制在 item 处理管道中限制并发量(CONCURRENT_ITEMS 设置)。
@defer.inlineCallbacks
def inline_install(customer):
... same as above
# The new "problem" is that we have to manage all this concurrency to
# avoid causing problems to others, but this is a nice problem to have.
def twisted_developer_day(customers):
print "Goodmorning from Twisted developer"
work = (inline_install(customer) for customer in customers)
#
# We use the Cooperator mechanism to make the secretary not
# service more than 5 customers simultaneously.
coop = task.Cooperator()
join = defer.DeferredList([coop.coiterate(work) for i in xrange(5)])
#
join.addCallback(lambda _: reactor.stop())
print "Bye from Twisted developer!"
twisted_developer_day(["Customer %d" % i for i in xrange(15)])
reactor.run()
# We are now more lean than ever, our customers happy, our hosting
# bills ridiculously low and our performance stellar.
# ~*~ THE END ~*~运行该代码。
$ ./deferreds.py 5
------ Running example 5 ------
Goodmorning from Twisted developer
Bye from Twisted developer!
Scheduling: Installation for Customer 0
...
Callback: Finished installation for Customer 4
All done for Customer 4
Scheduling: Installation for Customer 5
...
Callback: Finished installation for Customer 14
All done for Customer 14
* Elapsed time: 9.19 seconds可以看到,现在有类似于 5 个客户的处理槽。如果想要处理一个新的客户,只有在存在空槽时才可以开始,实际上,在这个例子中客户处理的时间总是相同的(3秒),因此会造成 5 位客户会在同一时间被批量处理的情况。最后,我们得到了和多线程示例中相同的性能,不过现在只使用了一个线程,代码更加简单并且更容易正确编写。
祝贺你,坦白地说,现在你得到了对于 Twisted 和非阻塞 I/O 编程的一份非常严谨的介绍。