分布式系统概述
对我来说,设计该系统是一个非常棒的经历(见图 11.2)。起初,我增加了功能和复杂性,以至于不得不要求读者拥有高端硬件才能运行这些示例。这就造成之后的一个紧迫需求成为简化——无论是为了保持硬件需求更加实际,还是确保本章能够保持专注在 Scrapy 上。
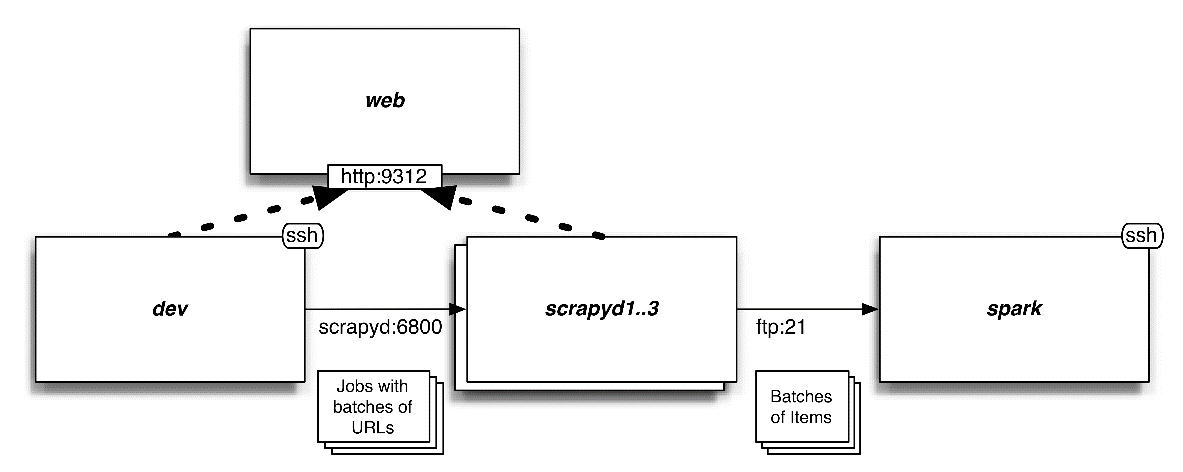
最后,本章将要使用的系统包含我们的开发机以及几个其他服务器。我们将使用开发机执行索引页面的垂直抓取,并从中批量抽取 URL。之后,将以轮询的方式将这些 URL 分发到 Scrapyd 节点当中执行爬取。最后,包含 Item 的 .jl 文件将会通过 FTP 传输到运行 Apache Spark 的服务器中。什么?FTP?是的,我选择 FTP 和本地文件系统,而不是 HDFS 或 Apache Kafka 的原因是因为其内存需求很低,并且 Scrapy 后端的 FEED_URI 能够直接支持。请注意,通过简单修改 Scrapyd 和 Spark 的配置,我们可以使用 Amazon S3 来存储这些文件,享受其带来的冗余性、扩展性等诸多特性。不过,这里不会有更多有意思的相关话题来学习任何奇技淫巧。
|
使用 FTP 的一个风险是 Spark 可能会在其上传过程中看到不完整的文件。为了避免发生该问题,我们将使用 Pure-FTPd 以及一个回调脚本,在上传完成后立即将上传的文件移动到 /root/items 目录中。 |
每隔几秒,Spark 将会检测该目录(/root/items),读取任何新文件,形成小批次,并执行分析。我们使用 Apache Spark 是因为它支持 Python 作为其编程语言,并且还支持流。到目前为止,我们可能已经使用了一些生命周期相对较短的爬取工作,不过现实世界中许多爬取工作永远都不会结束。爬取工作 24/7 不间断运行,并提供用于分析的数据流,数据越多其结果就越精确。正因如此,我们将使用 Apache Spark 进行展示。
|
使用 Apache Spark 和 Scrapy 并没有什么特殊之处。你也可以选择使用 Map-Reduce、Apache Storm 或任何其他适合你需求的框架。 |
在本章中,我们并不会将 Item 插入到诸如 ElasticSearch 或 MySQL 等数据库当中。第 9 章中介绍的技术在这里同样适用,不过其性能会很糟糕。当你每秒钟执行数千次写入操作时,只有极少数的数据库系统能够运行良好,但这正是我们的管道将会做的事情。如果我们想要向数据库中插入数据,则需要遵循与使用 Spark 相似的流程,即批量导入生成的 Item 文件。你可以修改我们的 Spark 示例流程,批量导入到任意数据库当中。
最后需要注意的是,该系统并没有良好的弹性。我们假设各节点都是健康的,并且任何失败都不会产生严重的业务影响。Spark 拥有弹性配置,能够提供高可用性。而除了 Scrapyd 的持久化队列外,Scrapy 并没有提供任何相关的内建功能,这就意味着失败的任务需要在节点恢复后才能重新启动。这种方式对于你的需求来说,也许适合,也许不适合。如果对你而言弹性十分重要,那么你需要搭建监控和分布式队列方案(如基于 Kafka 或 RabbitMQ),来重启失败的爬取工作。