使用JSON API和AJAX页面的爬虫
有时,你会发现自己在页面寻找的数据无法从 HTML 页面中找到。比如,当访问 http://localhost:9312/static/ 时(见图5.3),在页面任意位置右键单击 inspect element(1, 2),可以看到其中包含所有常见 HTML 元素的 DOM 树。但是,当你使用 scrapy shell 请求,或是在 Chrome 浏览器中右键单击 View Page Source(3, 4)时,则会发现该页面的 HTML 代码中并不包含关于房产的任何信息。那么,这些数据是从哪里来的呢?
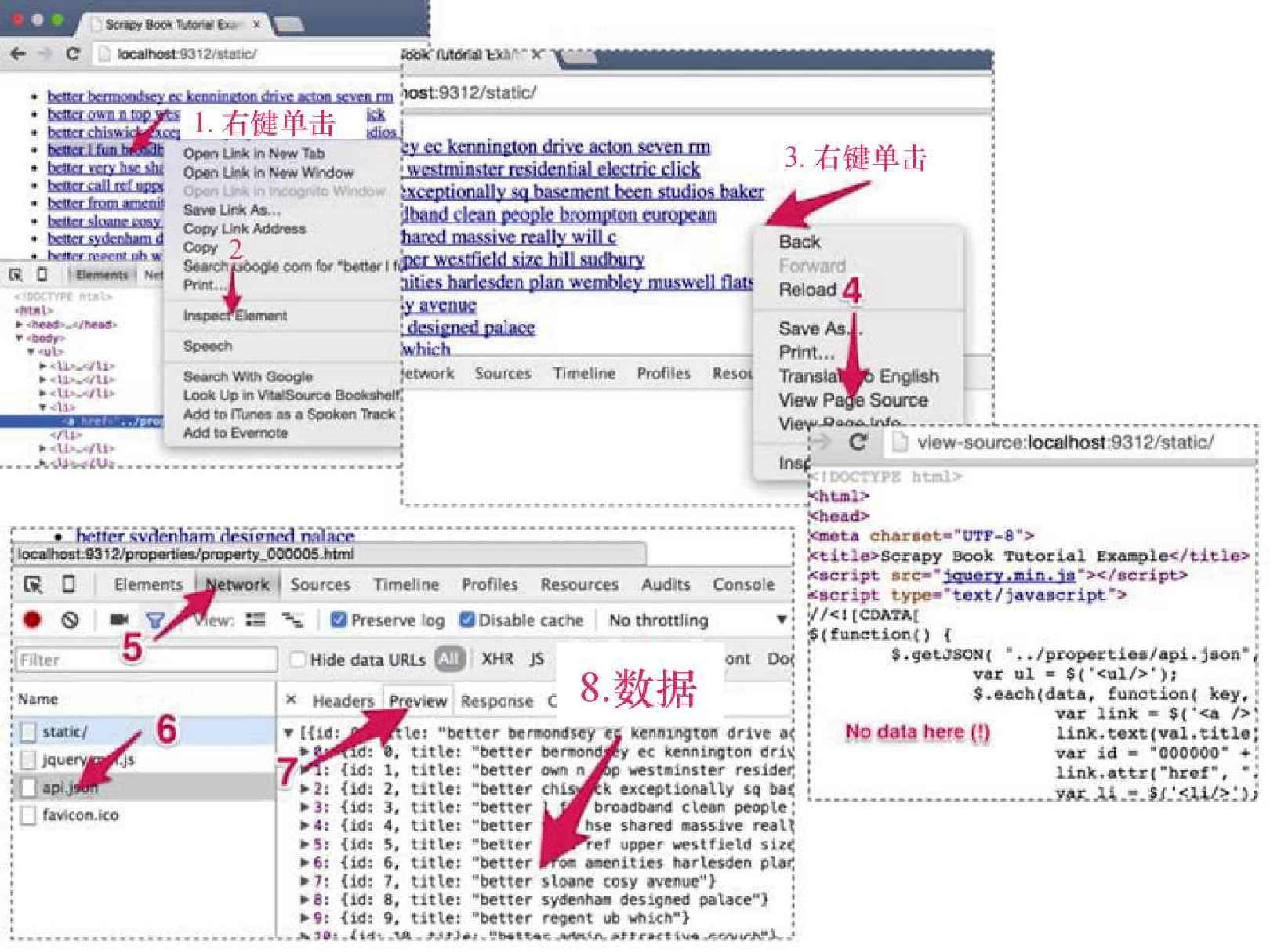
与平常一样,遇到这类例子时,下一步操作应当是打开 Chrome 浏览器开发者工具的 Network 选项卡,来看看发生了什么。在左侧的列表中,可以看到加载本页面时 Chrome 执行的请求。在这个简单的页面中,只有 3 个请求:static/ 是刚才已经检查过的请求;jquery.min.js 用于获取一个流行的 Javascript 框架的代码;而 api.json 看起来会让我们产生兴趣。当单击该请求(6),并单击右侧的 Preview 选项卡(7)时,就会发现这里面包含了我们正在寻找的数据。实际上, http://localhost:9312/properties/api.json 包含了房产的ID和名称(8),如下所示。
[{
"id": 0,
"title": "better set unique family well"
},
... {
"id": 29,
"title": "better portered mile"
}]这是一个非常简单的 JSON API 的示例。更复杂的 API 可能需要你登录,使用 POST 请求,或返回更有趣的数据结构。无论在哪种情况下,JSON 都是最简单的解析格式之一,因为你不需要编写任何 XPath 表达式就可以从中抽取出数据。
Python 提供了一个非常好的 JSON 解析库。当我们执行 import json 时,就可以使用 json.loads(response.body) 解析 JSON,将其转换为由 Python 原语、列表和字典组成的等效 Python 对象。
我们将第 3 章的 manual.py 拷贝过来,用于实现该功能。在本例中,这是最佳的起始选项,因为我们需要通过在 JSON 对象中找到的 ID,手动创建房产 URL 以及 Request 对象。我们将该文件重命名为 api.py,并将爬虫类重命名为 ApiSpider,name 属性修改为 api。新的 start_urls 将会是 JSON API 的 URL,如下所示。
start_urls = (
'http://web:9312/properties/api.json',
)如果你想执行 POST 请求,或是更复杂的操作,可以使用前一节中介绍的 start_requests() 方法。此时,Scrapy 将会打开该 URL,并调用包含以 Response 为参数的 parse() 方法。可以通过 import json,使用如下代码解析 JSON 对象。
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_%06d.html" % id
yield Request(url, callback=self.parse_item)前面的代码使用了 json.loads(response.body),将 Response 这个 JSON 对象解析为 Python 列表,然后迭代该列表。对于列表中的每一项,我们将 URL 的 3 个部分(base_url、property_%06d 以及 .html)组合到一起。base_url 是在前面定义的 URL 前缀。%06d 是 Python 语法中非常有用的一部分,它可以让我们结合 Python 变量创建新的字符串。在本例中,%06d 将会被变量 id 的值替换(本行结尾处 % 后面的变量)。id 将会被视为数字(%d 表示视为数字),并且如果不满 6 位,则会在前面加上 0,扩展成 6 位字符。比如,id 值为 5,%06d 将会被替换为 000005,而如果 id 为 34322,%06d 则会被替换为 034322。最终结果正是我们房产页面的有效 URL。我们使用该 URL 形成一个新的 Request 对象,并像第 3 章一样使用 yield。然后可以像平时那样使用 scrapy crawl 运行该示例。
$ scrapy crawl api
INFO: Scrapy 1.0.3 started (bot: properties)
...
DEBUG: Crawled (200) <GET ...properties/api.json>
DEBUG: Crawled (200) <GET .../property_000029.html>
...
INFO: Closing spider (finished)
INFO: Dumping Scrapy stats:
...
'downloader/request_count': 31, ...
'item_scraped_count': 30,你可能会注意到结尾处的状态是 31 个请求——每个 Item 一个请求,以及最初的 api.json 的请求。
在响应间传参
很多情况下,在 JSON API 中会有感兴趣的信息,你可能想要将它们存储到 Item 中。在我们的示例中,为了演示这种情况,JSON API 会在给定房产信息的标题前面加上 "better"。比如,房产标题是 "Covent Garden",API 就会将标题写为 "Better Covent Garden"。假设我们想要将这些 "better" 开头的标题存储到 Items 中,要如何将信息从 parse() 方法传递到 parse_item() 方法呢?
不要感到惊讶,通过在 parse() 生成的 Request 中设置一些东西,就能实现该功能。之后,可以从 parse_item() 接收到的 Response 中取得这些信息。Request 有一个名为 meta 的字典,能够直接访问 Response。比如在我们的例子中,可以在该字典中设置标题值,以存储来自 JSON 对象的标题。
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item)在 parse_item() 内部,可以使用该值替代之前使用过的 XPath 表达式。
l.add_value('title', response.meta['title'], MapCompose(unicode.strip, unicode.title))你会发现我们不再调用 add_xpath(),而是转为调用 add_value(),这是因为我们在该字段中将不会再使用到任何 XPath 表达式。现在,可以使用 scrapy crawl 运行这个新的爬虫,并且可以在 PropertyItems 中看到来自 api.json 的标题。