抽取更多的URL
到目前为止,我们使用的只是设置在爬虫的 start_urls 属性中的单一 URL。而该属性实际为一个元组,我们可以硬编码写入更多的 URL,如下所示。
start_urls = (
'http://web:9312/properties/property_000000.html',
'http://web:9312/properties/property_000001.html',
'http://web:9312/properties/property_000002.html',
)这种写法可能不会让你太激动。不过,我们还可以使用文件作为 URL 的源,写法如下所示。
start_urls = [i.strip() for i in open('todo.urls.txt').readlines()]这种写法其实也不那么令人激动,但它确实管用。更经常发生的情况是感兴趣的网站中包含一些索引页及房源页。比如,Gumtree 就包含了如图 3.7 所示的索引页,其地址为 http://www.gumtree.com/flats-houses/london 。
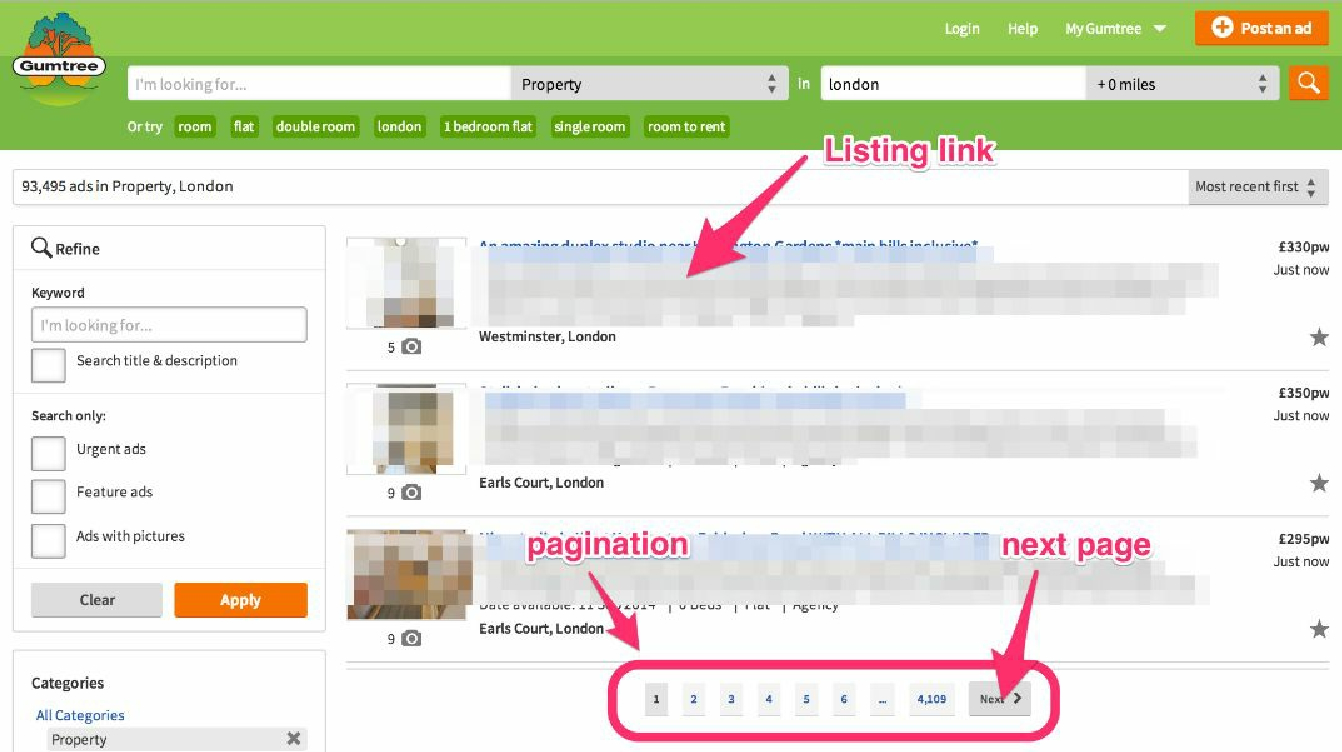
一个典型的索引页会包含许多到房源页面的链接,以及一个能够让你从一个索引页前往另一个索引页的分页系统。
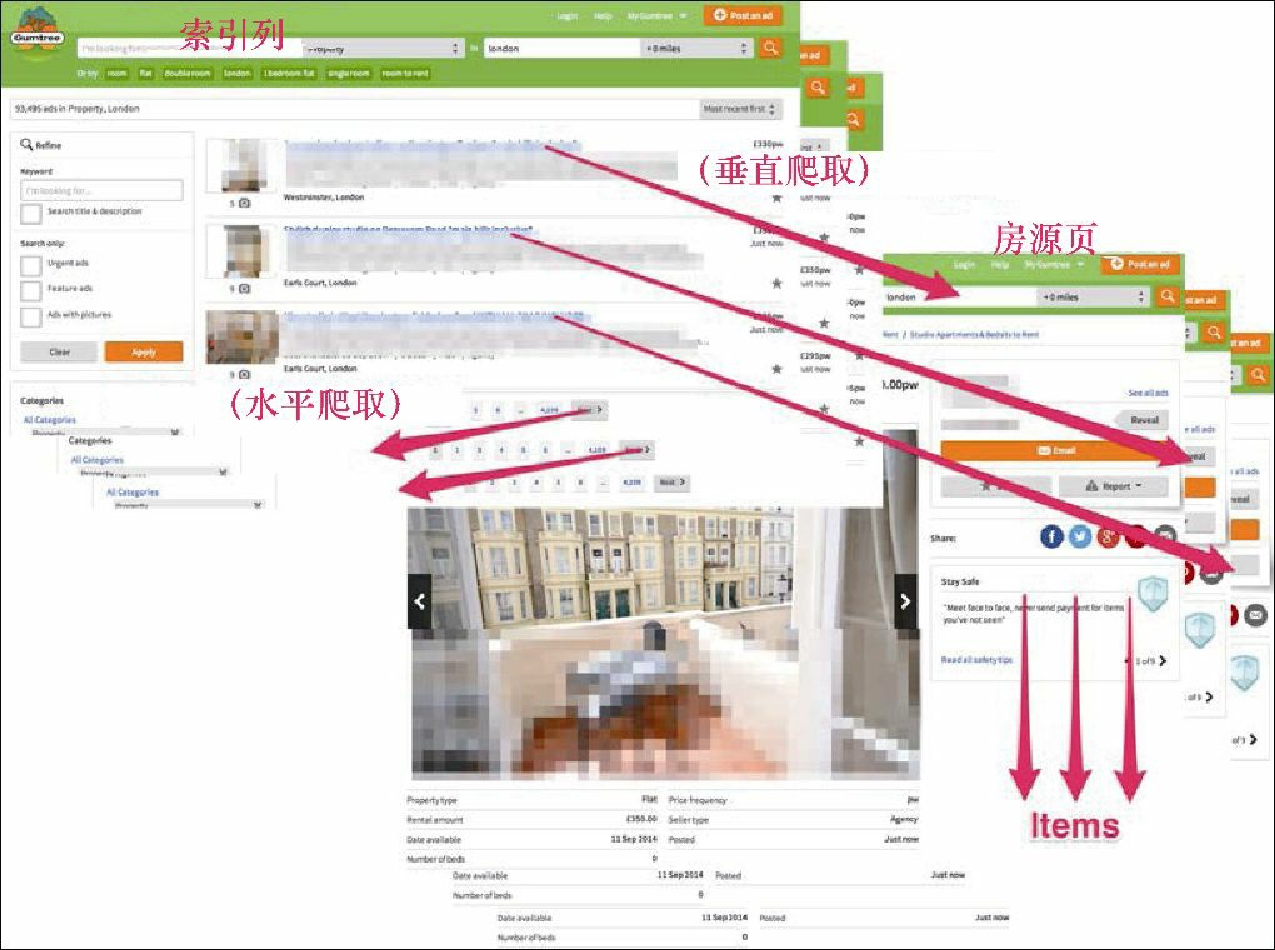
因此,一个典型的爬虫会向两个方向移动(见图3.8) :
-
横向——从一个索引页到另一个索引页;
-
纵向——从一个索引页到房源页并抽取 Item。
在本书中,我们将前者称为水平爬取,因为这种情况下是在同一层级下爬取页面(比如索引页);而将后者称为垂直爬取,因为该方式是从一个更高的层级(比如索引页)到一个更低的层级(比如房源页)。
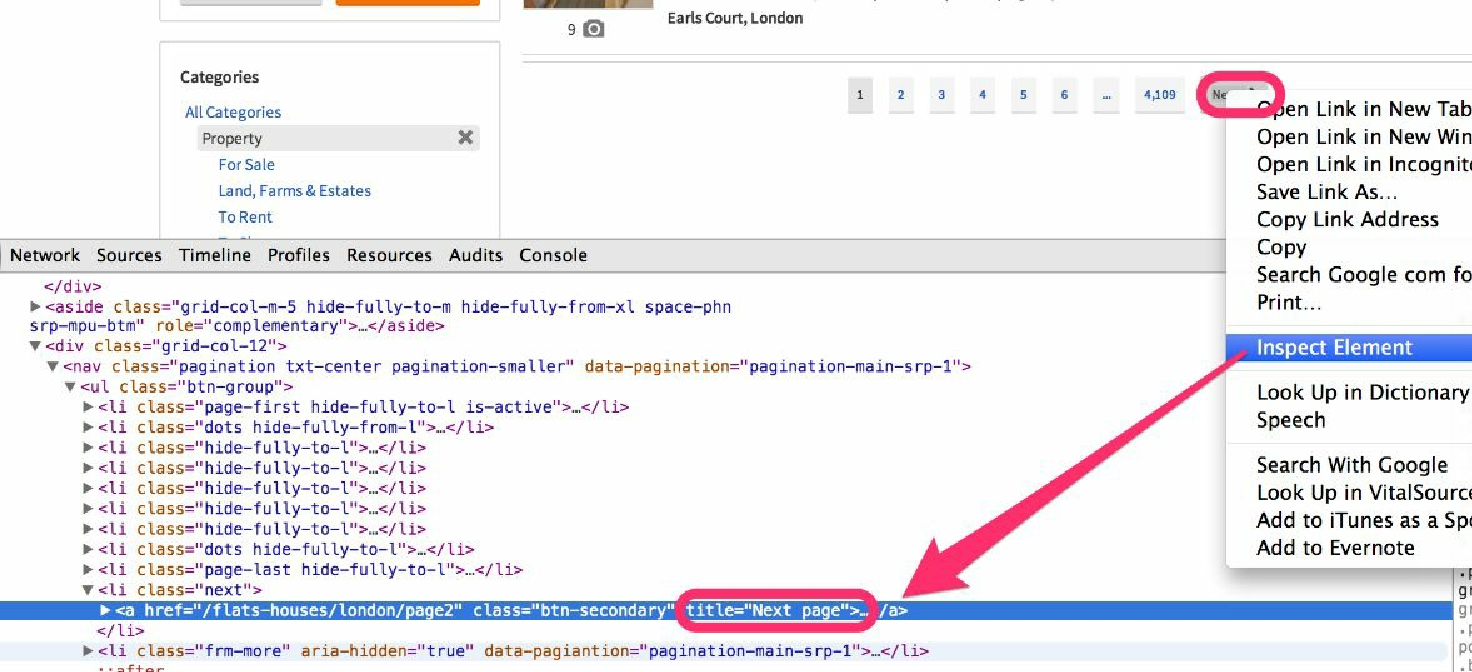
实际上,它比听起来更加容易。我们所有需要做的事情就是再增加两个 XPath 表达式。对于第一个表达式,右键单击 Next Page 按钮,可以注意到 URL 包含在一个链接中,而该链接又是在一个拥有类名 next 的 li 标签内,如图3.9所示。因此,我们只需使用一个实用的 XPath 表达式 //*[contains(@class,"next")]//@href,就可以完美运行了。
对于第二个表达式,右键单击页面中的列表标题,并选择 Inspect Element,如图3.10所示。
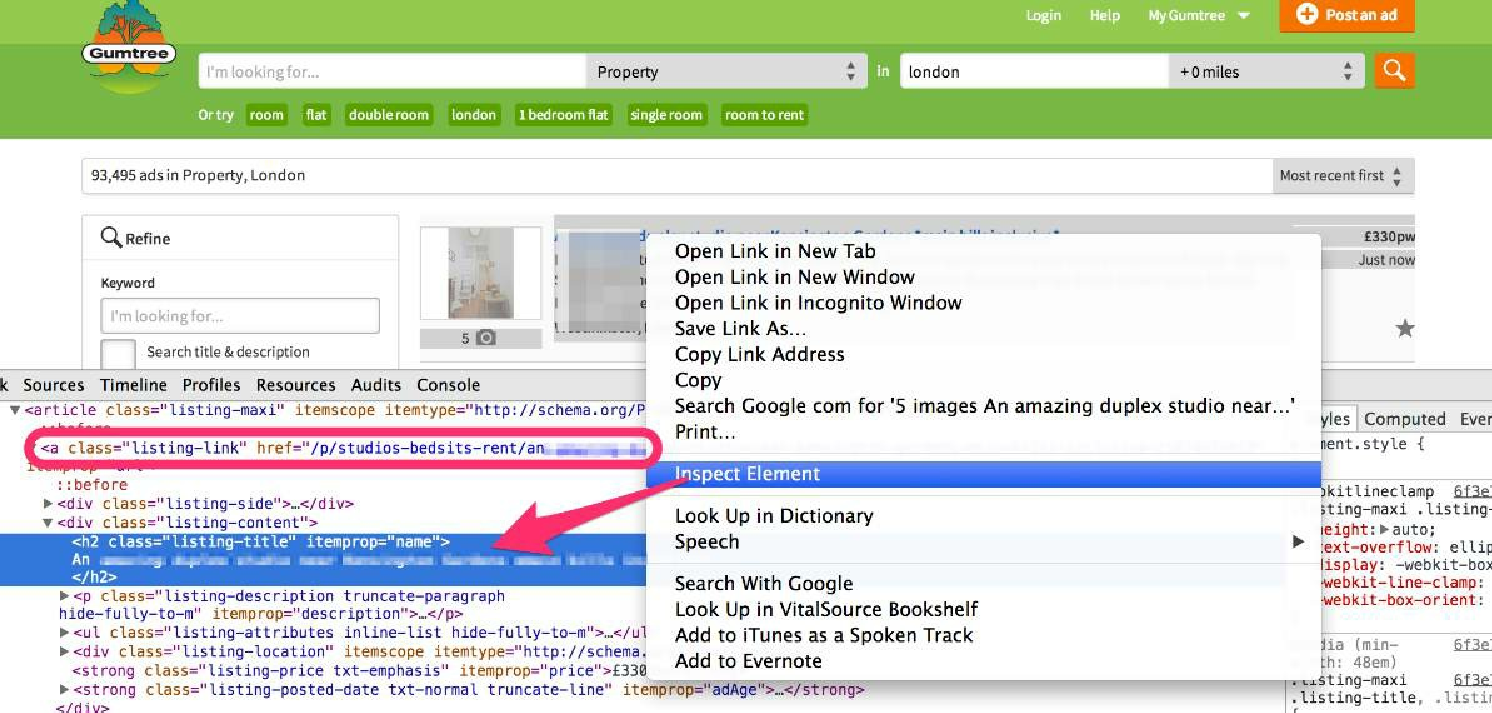
请注意,URL 中包含我们感兴趣的 itemprop="url" 属性。因此,表达式 //*[@itemprop="url"]/@href 就可以正常运行。现在,打开一个 scrapy shell 来确认这两个表达式是否有效:
$ scrapy shell http://web:9312/properties/index_00000.html
>>> urls = response.xpath('//*[contains(@class,"next")]//@href').extract()
>>> urls
[u'index_00001.html']
>>> import urlparse
>>> [urlparse.urljoin(response.url, i) for i in urls]
[u'http://web:9312/scrapybook/properties/index_00001.html']
>>> urls = response.xpath('//*[@itemprop="url"]/@href').extract()
>>> urls
[u'property_000000.html', ... u'property_000029.html']
>>> len(urls)
30
>>> [urlparse.urljoin(response.url, i) for i in urls]
[u'http://..._000000.html', ... /property_000029.html']非常好!可以看到,通过使用之前已经学习的内容及这两个 XPath 表达式,我们已经能够按照自身需求使用水平抓取和垂直抓取的方式抽取 URL 了。
使用爬虫实现双向爬取
我们将之前的爬虫拷贝到一个新文件中,并命名为 manual.py。
$ ls
properties scrapy.cfg
$ cp properties/spiders/basic.py properties/spiders/manual.py在 properties/spiders/manual.py 文件中,通过添加 from scrapy.http import Request 语句引入 Request 模块,将爬虫的 name 参数改为 'manual',修改 start_urls 以使用第一个索引页,并将 parse() 方法重命名为 parse_item()。好了!现在开始编写一个新的 parse() 方法,来实现水平和垂直两种抓取方式。
def parse(self, response):
# Get the next index URLs and yield Requests
next_selector = response.xpath('//*[contains(@class,"next")]//@href')
for url in next_selector.extract():
yield Request(urlparse.urljoin(response.url, url))
# Get item URLs and yield Requests
item_selector = response.xpath('//*[@itemprop="url"]/@href')
for url in item_selector.extract():
yield Request(urlparse.urljoin(response.url, url), callback=self.parse_item)|
你可能已经注意到了前面例子中的 yield 语句。yield 与 return 在某种意义上来说有些相似,都是将返回值提供给调用者。不过,和 return 不同的是,yield 不会退出函数,而是继续执行 for 循环。从功能上来说,前面的例子与下面的代码大体相 当: yield 是 Python “魔法” 的一部分,它可以使日常的高效编程工作更加轻松。 |
我们现在已经准备好运行该爬虫了。不过如果让该爬虫以当前的方式运行的话,则会抓取网站完整的 5 万个页面。为了避免运行时间过长,可以通过命令行参数:-s CLOSESPIDER_ITEMCOUNT=90,告知爬虫在爬取指定数量(如 90 个)的 Item 后停止运行(更多细节参见第 7 章)。现在,我们可以运行了。
$ scrapy crawl manual -s CLOSESPIDER_ITEMCOUNT=90
INFO: Scrapy 1.0.3 started (bot: properties)
...
DEBUG: Crawled (200) <...index_00000.html> (referer: None)
DEBUG: Crawled (200) <...property_000029.html> (referer: ...index_00000.html)
DEBUG: Scraped from <200 ...property_000029.html>
{'address': [u'Clapham, London'],
'date': [datetime.datetime(2015, 10, 4, 21, 25, 22, 801098)],
'description': [u'situated camden facilities corner'],
'image_urls': [u'http://web:9312/images/i10.jpg'],
'price': [223.88],
'project': ['properties'],
'server': ['scrapyserver1'],
'spider': ['manual'],
'title': [u'Portered Mile'],
'url': ['http://.../property_000029.html']}
DEBUG: Crawled (200) <...property_000028.html> (referer: ...index_00000.html)
...
DEBUG: Crawled (200) <...index_00001.html> (referer: ...)
DEBUG: Crawled (200) <...property_000059.html> (referer: ...)
...
INFO: Dumping Scrapy stats: ...
'downloader/request_count': 94, ...
'item_scraped_count': 90,如果仔细查看前面的输出,就会发现我们同时获得了水平抓取和垂直抓取的结果。第一个 index_00000.html 读取后,派生出了许多请求。当它们执行时,调试信息通过 referer URL 指出是谁发起的请求。比如,可以看到,property_000029.html、 property_000028.html……及 index_00001.html 都有相同的 referer(index_00000.html)。而 property_000059.html 及其他请求则是以 index_00001.html 为 referer 的,并且该过程还在持续。
从该示例中还可以观察到,Scrapy 在处理请求时使用的是后入先出(LIFO)策略(即深度优先爬取)。用户提交的最后一个请求会被首先处理。 在大多数情况下,这种默认的方式非常方便。比如,我们想要在移动到下一个索引页之前处理每一个房源页时。否则,我们将会填充一个包含待爬取房源页 URL 的巨大队列,无谓地消耗内存。另外,在许多情况中,你可能需要辅助的请求来完成单个请求,我们将会在后面的章节中遇到这种情况。你需要这些辅助的请求能够尽快完成,以腾出资源,并且让被抓取的 Item 能够稳定流动。
我们可以通过设置 Request() 的 priority 参数修改默认顺序,大于 0 表示高于默认的优先级,小于 0 表示低于默认的优先级。通常来说,Scrapy 的调度器会首先执行高优先级的请求,不过不要花费太多时间来考虑具体的哪个请求应该被首先执行。很可能在你的应用中,不会使用超过 1 个或 2 个请求优先级。此外还需要注意的是,URL 还会被执行去重操作,这在大部分时候也是我们想要的功能。不过如果我们需要多次执行同一个 URL 的请求,可以设置 Request() 方法 dont_filter 参数为 true。
使用CrawlSpider实现双向爬取
如果感觉上面的双向爬取有些冗长,则说明你确实发现了关键问题。Scrapy 尝试简化所有此类通用情况,以使其编码更加简单。最简单的实现同样结果的方式是使用 CrawlSpider,这是一个能够更容易地实现这种爬取的类。为了实现它,我们需要使用 genspider 命令,并设置 -t crawl 参数,以使用 crawl 爬虫模板创建一个爬虫。
$ scrapy genspider -t crawl easy web
Created spider 'crawl' using template 'crawl' in module:
properties.spiders.easy现在,文件 properties/spiders/easy.py 包含如下内容。
...
class EasySpider(CrawlSpider):
name = 'easy'
allowed_domains = ['web']
start_urls = ['http://www.web/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
...当你阅读这段自动生成的代码时,会发现它和之前的爬虫有些相似,不过在此处的类声明中,会发现爬虫是继承自 CrawlSpider,而不再是 Spider。CrawlSpider 提供了一个使用 rules 变量实现的 parse() 方法,这与我们之前例子中手工实现的功能一致。
现在,我们要把 start_urls 设置成第一个索引页,并且用我们之前的实现替换预定义的 parse_item() 方法。这次我们将不再需要实现任何 parse() 方法。我们将预定义的 rules 变量替换为两条规则,即水平抓取和垂直抓取。
rules = (
Rule(LinkExtractor(restrict_xpaths='//*[contains(@class,"next")]')),
Rule(LinkExtractor(restrict_xpaths='//*[@itemprop="url"]'),
callback='parse_item')
)这两条规则使用的是和我们之前手工实现的示例中相同的 XPath 表达式,不过这里没有了 a 或 href 的限制。顾名思义,LinkExtractor 正是专门用于抽取链接的,因此在默认情况下,它们会去查找 a(及 area)href 属性。你可以通过设置 LinkExtractor() 的 tags 和 attrs 参数来进行自定义。需要注意的是,回调参数目前是包含回调方法名称的字符串(比如 'parse_item'),而不是方法引用,如 Request(self.parse_item)。最后,除非设置了 callback 参数,否则 Rule 将跟踪已经抽取的 URL,也就是说它将会扫描目标页面以获取额外的链接并跟踪它们。 如果设置了 callback,Rule 将不会跟踪目标页面的链接。如果你希望它跟踪链接,应当在 callback 方法中使用 return 或 yield 返回它们,或者将 Rule() 的 follow 参数设置为 true。当你的房源页既包含 Item 又包含其他有用的导航链接时,该功能可能会非常有用。
运行该爬虫,可以得到和手工实现的爬虫相同的结果,不过现在使用的是一个更加简单的源代码。
$ scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=90本章小结
本章可能是大家开始学习 Scrapy 时最重要的一章。你刚刚学习了开发爬虫最基本的方法:UR2IM。你学会了如何自定义适合需求的 Item,使用 ItemLoader、XPath 表达式和处理器加载 Item,以及如何对 Request 使用 yield 操作。我们使用 Request 横向到达不同的索引页,纵向到达房源页并抽取 Item。最后,我们看到了如何使用 CrawlSpider 和 Rule,以很少的代码行创建非常强大的爬虫。如果你想要更深入地理解这些概念,请尽可能多地阅读本章,当然,也可以在你开发自己的爬虫时使用本章作为参考。
我们刚刚从网站中得到了一些信息。为什么它这么重要呢?我想答案会在下一章中变得明朗起来,在下一章中,通过简单的几页内容,我们将会开发一个简单的手机应用,并使用 Scrapy 填充其中的数据。我想,结果会令大家印象深刻。