解决性能问题
现在我们应当对系统预期拥有的性能是什么有了充分的了解,接下来看一下如果没有得到想要的性能时应当如何操作。我们将通过探讨具体症状来展示不同的问题案例,执行示例爬虫进行复现,探讨根本原因,最终提供解决问题的操作。案例展示的顺序从系统顶层问题逐步到低层次的 Scrapy 技术细节。这就意味着更普遍的案例可能会出现在没那么常见的案例之后。在探索你的性能问题之前,请完整阅读本章全部内容。
案例 #1: CPU饱和
症状:在某些情况下,你增加了并发级别,但没有得到性能提升。当降低并发级别时,一切工作再次回归预期(见图 10.6)。你的下载器可以被充分利用,但是似乎每个请求的平均时间出现了激增。当在 UNIX/Linux 系统中使用 top 命令、在 Power Shell 中使用 ps 命令或在 Windows 中使用任务管理器查看 CPU 负载如何时,会发现 CPU 负载非常高。
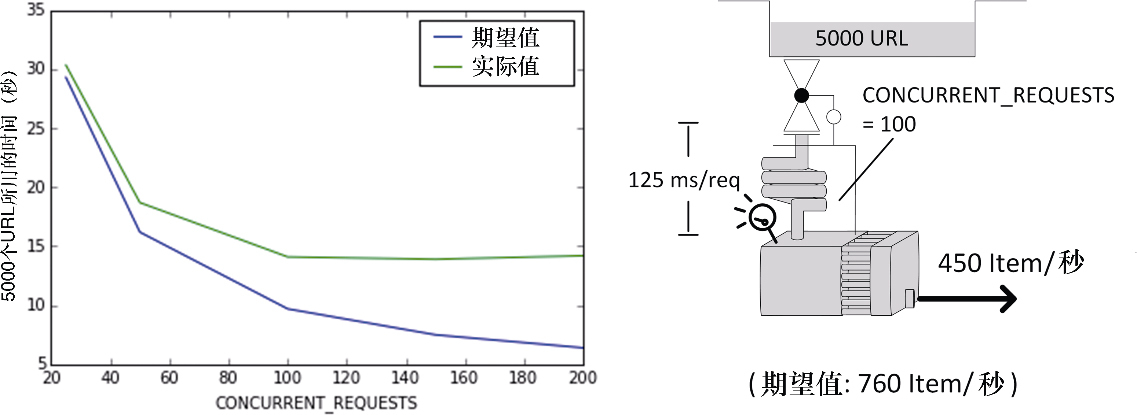
示例:假设运行了如下命令。
$ for concurrent in 25 50 100 150 200; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=5000 \
-s CONCURRENT_REQUESTS=$concurrent
done你得到了其抓取 5000 个 URL 的时间。在表 10.2 中,期望值一列是基于前面得到的公式计算所得,而 CPU 负载是通过 top 命令观察得到的(可以在开发机中使用第二个终端运行该命令)。
| CONCURRENT_REQUESTS | 期望值(秒) | 实际值(秒) | 期望值与实际值的百分比 | CPU负载 |
|---|---|---|---|---|
25 |
29.3 |
30.34 |
97% |
52% |
50 |
16.2 |
18.7 |
87% |
78% |
100 |
9.7 |
14.1 |
69% |
92% |
150 |
7.5 |
13.9 |
54% |
100% |
200 |
6.4 |
14.2 |
45% |
100% |
在我们的实验中,由于几乎不执行任何处理,因此能够得到高并发。而在一个更复杂的系统中,很可能会更早地看到该行为。
讨论:Scrapy 重度使用单一线程,当达到很高级别的并发时,CPU 可能会成为瓶颈。假设不使用任何线程池,那么 Scrapy 应当使用的 CPU 负载建议在 80%~90%。请记住你可能在其他系统资源上遇到相似的问题,比如网络带宽、内存或磁盘吞吐量,不过这些都很少见,并且会落入通用系统的管理范畴,因此就不在这里进一步强调了。
解决方案:通常假设你的代码是有效的。你可以通过在同一台服务器上运行多个 Scrapy 爬虫,以使总计并发超过 CONCURRENT_REQUESTS。这可以帮助你利用更多可用核心,尤其是当管道的其他服务或其他线程不使用它们的时候。如果需要更多的并发,可以使用多台服务器(参见第 11 章),这种情况下可能还需要更多可用的资金、网络带宽以及磁盘吞吐量。始终检查 CPU 利用率是你的首要约束。
案例#2:代码阻塞
症状:你所观察到的行为无法说通。和期望值相比,系统非常慢,并且奇怪的是,即使当你改变 CONCURRENT_REQUESTS 的值时,速度也没有显著变化(见图10.7)。下载器看起来总是空的(少于 CONCURRENT_REQUESTS ),而抓取程序却有不少响应。
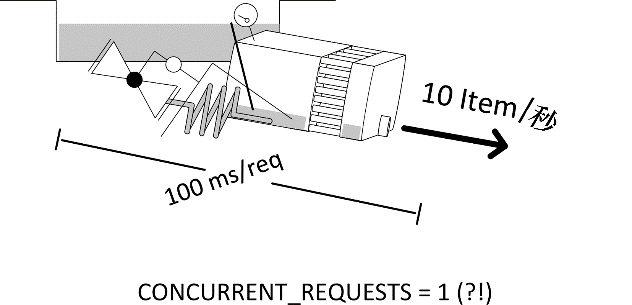
示例:你可以使用两个基准设置:SPEED_SPIDER_BLOCKING_DELAY 和 SPEED_PIPELINE_BLOCKING_DELAY(它们具有相同的效果),对每个响应启用一个 100ms 的阻塞。在给定并发级别时,我们期望 100 个 URL 应当花费 2~3 秒,但无论 CONCURRENT_REQUESTS 的值是多少,我们总是需要花费大约 13 秒的时间(见表 10.3)。
for concurrent in 16 32 64; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=100 \
-s CONCURRENT_REQUESTS=$concurrent -s SPEED_SPIDER_BLOCKING_DELAY=0.1
done| CONCURRENT_REQUESTS | 总时间(秒) |
|---|---|
16 |
13.9 |
32 |
13.2 |
64 |
12.9 |
讨论:任何阻塞代码都会立即抵消掉 Scrapy 的并发性,本质上相当于设置 CONCURRENT_REQUESTS = 1。根据上面的简单公式,100URL · 100ms(阻塞延迟)= 10秒 + tstart/stop ,充分解释了我们所看到的延迟。
无论阻塞代码是在管道中还是在爬虫中,你都会发现抓取程序可以被充分利用,但其前后的模块都是空的。这看起来违背了前面讲过的管道的物理现象,不过由于我们已经不再拥有一个并发系统了,所以管道规则不再适用。该错误非常容易发生(比如使用阻塞 API),你一定会在某一时刻出现该错误。你会注意到类似的讨论同样适用于复杂代码的计算。你应当为此类代码使用多线程,正如我们在第 9 章中所看到的;或者是在 Scrapy 之外进行批量处理,我们将会在第 11 章中看到一个相关示例。
解决方案:将假设你继承了基代码,并且不清楚阻塞代码位于何处。如果该系统在没有任何管道的情况下仍然可以工作,那么禁用这些管道,并检查是否仍存在奇怪的行为。如果仍存在,那么阻塞代码位于爬虫中。如果不再存在,那么依次启用管道,观察问题是否开始出现。如果该系统在缺少任何运行中的模块的情况下无法正常运转,那么可以在每个管道阶段的功能之间添加一些日志消息(或插入虚拟管道打印时间戳)。通过检查日志,可以轻松检测出系统在什么地方花费了最多的时间。如果希望有一个更加长期/可复用的解决方案,可以使用虚拟管道跟踪你的请求,在 Request 的 meta 字段中为每个阶段添加时间戳。最后,hook 到 item_scraped 信号,并记录时间戳日志。一旦你发现阻塞代码,则应将其转换为 Twisted/异步代码,或使用 Twisted 的线程池。如果想要查看该转换的效果,可以将 SPEED_PIPELINE_BLOCKING_DELAY 替换为 SPEED_ PIPELINE_ASYNC_DELAY,重新运行前面的示例。性能的变化将十分惊人。
案例#3:下载器中的“垃圾”
症状:你得到的吞吐量低于预期。下载器看起来有时会有比 CONCURRENT_REQUESTS 更多的请求。
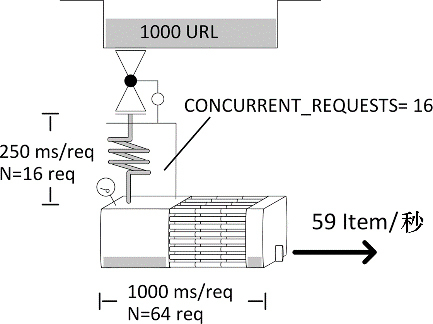
示例:模拟以 0.25 秒响应时间的情况下载 1000 个页面。按照默认的 16 个并发,根据公式需要花费大约 19 秒的时间。我们使用一个管道,用 crawler.engine.download() 制造到伪造 API 的额外 HTTP 请求,其响应时间在 1 秒之内。你可以通过 http://localhost:9312/benchmark/ar:1/api?text=hello 进行尝试(见图 10.8)。让我们运行一个爬取程序。
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=1000 -s SPEED_T_RESPONSE=0.25 -s SPEED_API_T_RESPONSE=1 -s SPEED_PIPELINE_API_VIA_DOWNLOADER=1
...
s/edule d/load scrape p/line done mem
968 32 32 32 0 32768
952 16 0 0 32 0
936 32 32 32 32 32768
...
real 0m55.151s
非常奇怪!我们的任务不但花费了预期的 3 倍时间,还超出了下载器定义的 CONCURRENT_REQUESTS 所设定的 16 个活跃请求数(d/load)。下载器显然是瓶颈,因为它在超负荷工作。我们重新运行爬取程序,并在另一个控制台中打开到 Scrapy 的 telnet 连接。之后,就可以查看下载器中有哪些请求是活跃的了。
$ telnet localhost 6023
>>> engine.downloader.active
set([<POST http://web:9312/ar:1/ti:1000/rr:0.25/benchmark/api>, ... ])看起来它处理的大部分是 API 请求,而不是下载正常页面。
讨论:你可能会认为没有人使用 crawler.engine.download(),因为它看起来会比较复杂,不过它在 Scrapy 的基代码中使用了两次,分别是 robots.txt 中间件和多媒体管道。因此,当人们需要使用 Web API 时,它也会被推荐为一种解决方案。因为使用它要比使用阻塞 API 更好,比如我们在前面章节中看到的流行的 Python 包 requests;而且,使用它还会比理解 Twisted 编程和使用 treq 简单一些。现在既然有了咱们这本书,这些就不再是使用它的借口了。另一方面,该错误非常难调试,所以应当在研究性能时主动检查下载器中的活跃请求。如果发现 API 或多媒体 URL 不是你爬取的直接目标,那么就意味着某些管道使用了 crawler.engine.download() 来执行 HTTP 请求。由于我们的 CONCURRENT_REQUESTS 限制不适用于这些请求,也就意味着我们很可能看到下载器加载的请求数超过 CONCURRENT_REQUESTS,乍看起来有些矛盾。除非虚假请求数降低到 CONCURRENT_REQUESTS 以下,否则调度器不会获取新的正常页面请求。
因此,我们从系统中得到的吞吐量相当于原始请求持续 1 秒(API 延迟),而不是 0.25 秒(页面下载延迟)的吞吐量不是一种巧合。这种情况特别容易令人困惑,因为除非 API 调用比页面请求慢,否则我们不会注意到任何性能下降。
解决方案:我们可以使用 treq 代替 crawler.engine.download() 来解决该问题。你将发现这会使抓取程序的性能突增,这对于 API 架构来说可能是个坏消息。我将从一个低数值的 CONCURRENT_REQUESTS 开始,逐渐增长以确保不会使 API 服务器过载。
下面是和前面相同的运行示例,不过这次使用了 treq。
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=1000 -s SPEED_T_RESPONSE=0.25 -s SPEED_API_T_RESPONSE=1 -s SPEED_PIPELINE_API_VIA_TREQ=1
...
s/edule d/load scrape p/line done mem
936 16 48 32 0 49152
887 16 65 64 32 66560
823 16 65 52 96 66560
...
real 0m19.922s你会发现一个非常有趣的事情。管道(p/line)似乎包含比下载器(d/load )更多的条目(见图10.9)。这种情况非常好,并且了解其原因也很有趣。
下载器如预期一样,充分加载了 16 个请求。也就是说,系统吞吐量为 T = N / S = 16 /0.25= 64个请求/秒。我们可以通过观察 done 列的增长进行确认。一个请求会在下载器中花费 0.25 秒,但是由于缓慢的 API 请求,它会在管道中花费 1 秒的时间。这意味着在管道中(p/line),我们期望看到平均 N = T·S = 64·1 = 64 个 Item。非常好。这表示现在管道有瓶颈吗?不,因为我们没有限制同时在管道中处理的响应数量。只要数值不是无限增加,就能够很好地运行。在下一节中,我们将看到更多关于这个问题的讨论。
案例#4:大量响应或超长响应造成的溢出
症状:下载器几乎满负荷运转,并且一段时间后关闭。该模式不断重复。抓取程序的内存使用率很高。
示例:此处我们使用了和前面一样的设置(使用了 treq ),不过响应会比较大,大约是 120KB 的 HTML。如你所见,此时花费了 31 秒的时间完成,而不是 20 秒左右(见图 10.10)。
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=1000 -s SPEED_T_RESPONSE=0.25 -s SPEED_API_T_RESPONSE=1 -s SPEED_PIPELINE_API_VIA_TREQ=1 -s SPEED_DETAIL_EXTRA_SIZE=120000
s/edule d/load scrape p/line done mem
952 16 32 32 0 3842818
917 16 35 35 32 4203080
876 16 41 41 67 4923608
840 4 48 43 108 5764224
805 3 46 27 149 5524048
...
real 0m30.611s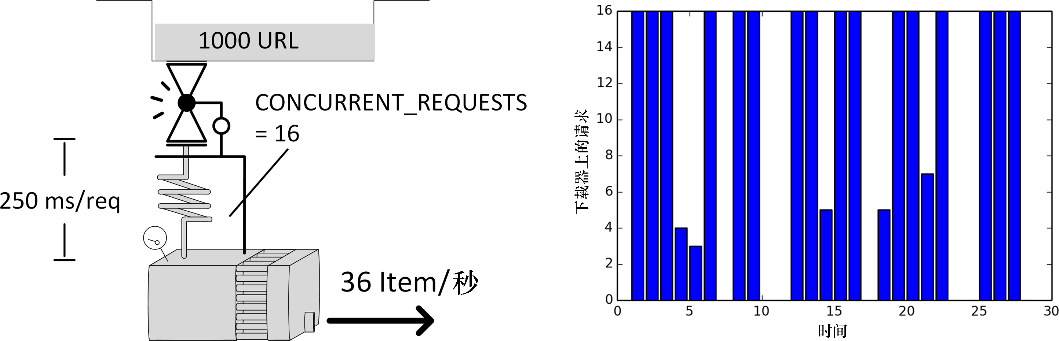
讨论:我们可能会天真地尝试将这种延迟解释为 “创建、传输、处理页面需要花费更多时间”,不过这并不是此处发生的情况。此处有一个硬编码(编写代码时写入)的对请求总大小的限制:max_active_size = 5000000。假设每个请求的大小等于其请求体的大小,并且至少是 1KB。
一个重要的细节是,该限制可能是 Scrapy 最巧妙且本质的机制,用于防止过慢的爬虫或管道。如果你的任何一个管道的吞吐量比下载器的吞吐量更慢,最终就会发生这种情况。当管道处理时间过长时,即使很小的请求,也很容易触发该限制。下面是一个管道超长的极端案例,80 秒之后就会开始产生问题。
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=10000 -s SPEED_T_RESPONSE=0.25 -s SPEED_PIPELINE_ASYNC_DELAY=85解决方案:对于已存在的基础架构,针对该问题几乎无计可施。当你不再需要时(比如爬虫之后),清空响应体是个不错的选择,不过在写操作时执行该操作不会重置 Scraper 的计数器。所有你能做的就是降低管道的处理时间,从而有效减少 Scraper 中处理的响应数量。可以使用传统的优化手段实现它:检查可能与之交互的 API 或数据库是否能够支持抓取程序的吞吐量;分析抓取程序;将功能管道移动到批处理/后处理系统;使用更强大的服务器或分布式爬取。
案例#5:有限/过度item并发造成的溢出
症状:你的爬虫为每个响应创建了多个 Item。你得到的吞吐量低于预期,并且可能和前面案例中的开/关模式相同。
示例:这里,我们有一个稍微不太一样的设置,我们有 1000 个请求,并且它们的每个返回页面都有 100 个 Item。响应时间是 0.25 秒,Item 管道处理时间为 3 秒。我们设置 CONCURRENT_ITEMS 的值从 10 到 150,执行多次。
for concurrent_items in 10 20 50 100 150; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=100000 -s \
SPEED_T_RESPONSE=0.25 -s SPEED_ITEMS_PER_DETAIL=100 -s \
SPEED_PIPELINE_ASYNC_DELAY=3 -s \
CONCURRENT_ITEMS=$concurrent_items
done
...
s/edule d/load scrape p/line done mem
952 16 32 180 0 243714
920 16 64 640 0 487426
888 16 96 960 0 731138
...讨论:值得再次注意,该情况只适用于爬虫为每个响应生成多个 Item 时。除这种情况外,你应该设置 CONCURRENT_ITEMS = 1,然后忘了它。另外还需注意的是,这是一个虚拟的示例,因为其吞吐量相当大,达到了每秒大约 1300 个 Item。之所以达到如此高的吞吐量,是因为延迟低且稳定、几乎没有真实处理,以及响应的大小很小。这种情况并不常见。
我们首先要注意的事情是,在此之前 scrape 和 p/line 列通常都是相同的数值,而现在 p/line 则是 CONCURRENT_ITEMS · scrape。这是符合预期的,因为 scrape 显示的是响应数,而 p/line 则是 Item 数。
第二个有意思的事情是图 10.11 所示的浴缸形状的性能函数。由于纵轴是缩放的,因此该图表看起来会比实际情况更显著。在左侧,延迟非常高,因为触及了前一节所提到的内存限制。而在右侧,并发过多,造成使用了过多的 CPU。获得最佳效果并不那么重要,因为向左右移动非常容易。
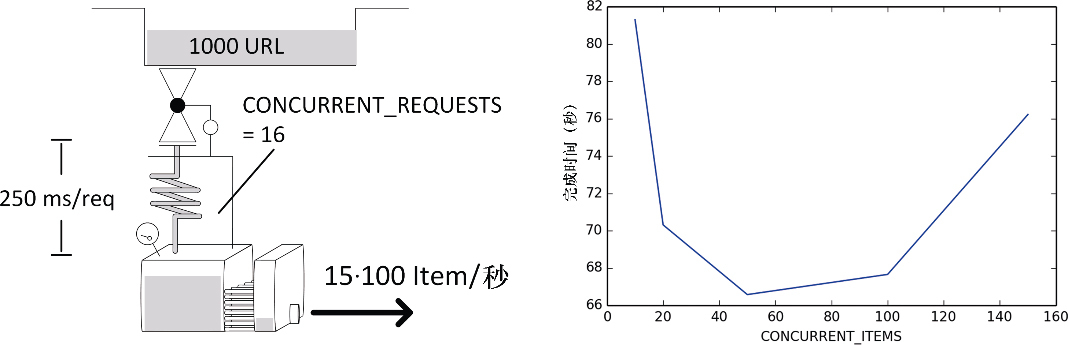
解决方案:检测本案例的两种问题症状非常容易。如果 CPU 使用率过高,那么最好减少 CONCURRENT_ITEMS 的值。如果触及响应的 5MB 限制,那么你的管道无法跟上下载器的吞吐量,增加 CONCURRENT_ITEMS 的值可能能够快速解决该问题。如果修改后没有什么区别,那么应当遵照前面一节给出的建议,再三询问自己系统的其余部分是否能够支持你的抓取程序的吞吐量。
案例#6:下载器未充分利用
症状:你增加了 CONCURRENT_REQUESTS 的值,但是下载器并未跟上,没能充分利用。调度器是空的。
示例:首先,我们运行一个没有问题的示例。我们将切换到 1 秒的响应时间,因为它能够简化计算量,使下载器的吞吐量 T = N / S = N / 1 = CONCURRENT_REQUESTS。假设按照如下命令运行。
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500 \
-s SPEED_T_RESPONSE=1 -s CONCURRENT_REQUESTS=64
s/edule d/load scrape p/line done mem
436 64 0 0 0 0
...
real 0m10.99s我们得到了一个充分利用的下载器(64 个请求),总时间为 11 秒,与我们以每秒 64 个请求的条件处理 500 个 URL 的模型相匹配(S = N / T + tstart/stop = 500 / 64 + 3.1 = 10.91秒)。
现在,执行相同的爬取,不过不再像前面那些示例那样默认从列表中提供 URL,而是使用索引页通过 SPEED_START_REQUESTS_STYLE=UseIndex 抽取 URL。这和我们本书中其他章使用的模式相同。每个索引页默认包含 20 个 URL。
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500 \
-s SPEED_T_RESPONSE=1 -s CONCURRENT_REQUESTS=64 \
-s SPEED_START_REQUESTS_STYLE=UseIndex
s/edule d/load scrape p/line done mem
0 1 0 0 0 0
0 21 0 0 0 0
0 21 0 0 20 0
...
real 0m32.24s很明显,这和前面的案例不太一样。不知为何,下载器的运行低于其最大能力,并且吞吐量为 T = N / S−tstart/stop = 500 / (32.2 - 3.1) = 17 个请求/秒。
讨论:快速浏览 d/load 列,可以确信下载器没能充分利用。这是因为我们没有足够的 URL 提供给它。我们的抓取处理生成 URL 的速度比最大消费能力要慢。在本例中,每个索引页会生成 20 个 URL 加上 1 个前往下一索引页的 URL。吞吐量无论如何都无法超过每秒 20 个请求,因为我们无法足够快地得到源 URL。该问题非常隐蔽,容易被忽视。
解决方案:如果每个索引页包含一个以上的下一页的链接,那么可以利用它们加速 URL 的生成。如果可以找到显示更多结果的索引页面(比如 50 个)就更好了。我们可以通过运行几个模拟来观察其行为。
$ for details in 10 20 30 40; do for nxtlinks in 1 2 3 4; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500 -s SPEED_T_RESPONSE=1 \
-s CONCURRENT_REQUESTS=64 -s SPEED_START_REQUESTS_STYLE=UseIndex \
-s SPEED_DETAILS_PER_INDEX_PAGE=$details \
-s SPEED_INDEX_POINTAHEAD=$nxtlinks
done; done在图 10.12 中,可以看到吞吐量是如何根据这两个参数变化的。我们观察到了线性行为,无论是下一页链接,还是详情页,直到达到系统上限。可以通过重新排列爬取的 Rule 进行实验。如果使用 LIFO(默认)顺序,你可能会看到如果先调用索引页请求,最后在列表中抽取它们的话,能够得到较小的改善。你也可以尝试为访问索引页的请求设置高优先级。虽然这两种技术都没有显著的改善,但可以通过分别设置 SPEED_INDEX_RULE_LAST=1 和 SPEED_INDEX_HIGHER_PRIORITY=1 来进行尝试。请注意这两种解决方案都会首先下载整个索引页(由于优先级高),因此会在调度器中生成大量 URL,增加内存需求。在它们完成所有索引之前,只会给出少量的结果。对于少量索引还可以接受,但是对于大量索引的情况,就不太可取了。
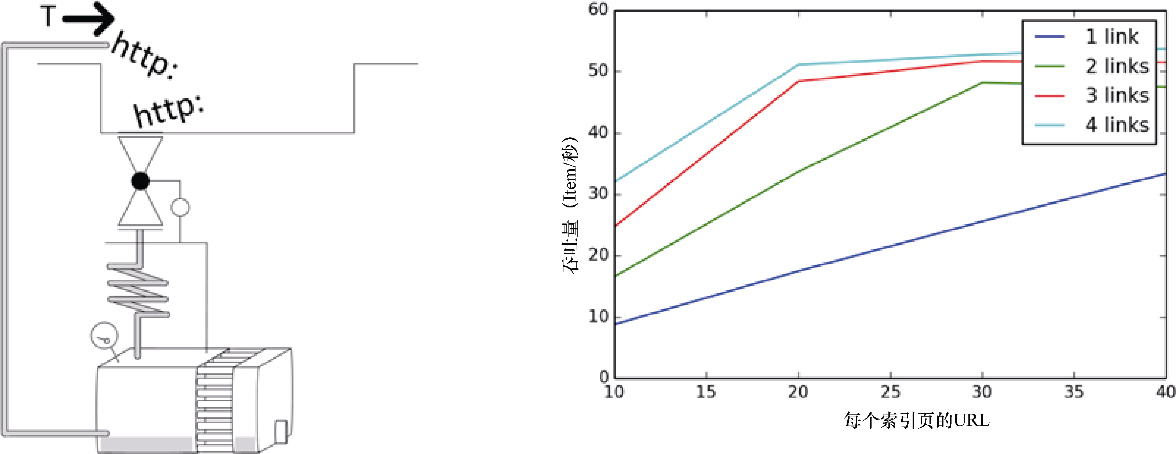
一个简单而又强大的技术是索引分片。这就需要你使用超过一个初始索引 URL,在它们之间有一个最大距离。比如,如果索引包含 100 页,你可以选取 1 和 51 作为起始索引。然后,爬虫可以以两倍速率使用下一页链接有效遍历索引。如果你能找到一种遍历索引的方式,比如基于产品的品牌或提供给你的任何其他属性,并且可以将其按照大致相等的段进行拆分的话,也可以做到类似的事情。你可以使用 -s SPEED_INDEX_SHARDS 设置进行模拟。
$ for details in 10 20 30 40; do for shards in 1 2 3 4; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500 -s SPEED_T_RESPONSE=1 \
-s CONCURRENT_REQUESTS=64 -s SPEED_START_REQUESTS_STYLE=UseIndex \
-s SPEED_DETAILS_PER_INDEX_PAGE=$details -s SPEED_INDEX_SHARDS=$shards
done; done结果要比前面的技术更好,如果该方法适合你的话,我将会推荐这种方法,因为它更加简单整洁。