使用XPath选择HTML元素
如果你具有传统软件工程背景,并且不了解 XPath 相关知识的话,可能会担心为了访问 HTML 文档中的信息,你将需要做很多字符串匹配、在文档中搜索标签、处理特殊情况等工作,或是需要设法解析整个树表示法以获取你想抽取的东西。有一个好消息是这些工作都不是必需的。你可以通过一种称为 XPath 的语言选择并抽取元素、属性和文本,这种语言正是专门为此而设计的。
为了在 Google Chrome 浏览器中使用 XPath,需要单击 Developer Tools 的 Console 标签,并使用 $x 工具函数。比如,你可以尝试在 http://example.com/ 上使用 $x('//h1')。它将会把浏览器移动到 <h1> 元素上,如图2.5所示。
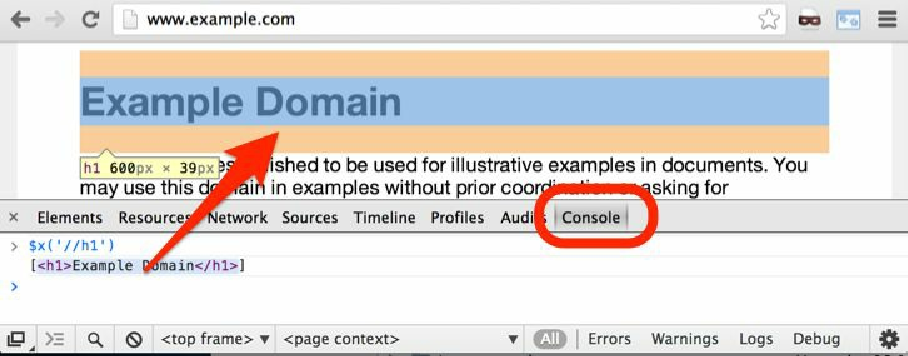
你在 Chrome 的 Console 标签中将会看到返回的是一个包含选定元素的 JavaScript 数组。如果将鼠标指针移动到这些属性上,被选取的元素将会在屏幕上高亮显示,这样就会十分方便。
有用的XPath表达式
文档的层次结构始于 <html> 元素,可以使用元素名和斜线来选择文档中的元素。比如,下面是几种表达式从 http://example.com 页面返回的结果。
$x('/html')
[ <html>...</html> ]
$x('/html/body')
[ <body>...</body> ]
$x('/html/body/div')
[ <div>...</div> ]
$x('/html/body/div/h1')
[ <h1>Example Domain</h1> ]
$x('/html/body/div/p')
[ <p>...</p>, <p>...</p> ]
$x('/html/body/div/p[1]')
[ <p>...</p> ]
$x('/html/body/div/p[2]')
[ <p>...</p> ]需要注意的是,因为在这个特定页面中,<div> 下包含两个 <p> 元素,因此 html/body/div/p 会返回两个元素。可以使用 p[1] 和 p[2] 分别访问第一个和第二个元素。
另外还需要注意的是,从抓取的角度来说,文档标题可能是 head 部分中我们唯一感兴趣的元素,该元素可以通过下面的表达式进行访问。
$x('//html/head/title')
[ <title>Example Domain</title> ]对于大型文档,可能需要编写一个非常大的 XPath 表达式以访问指定元素。为了避免这一问题,可以使用 // 语法,它可以让你取得某一特定类型的元素,而无需考虑其所在的层次结构。比如,//p 将会选择所有的 p 元素,而 //a 则会选择所有的链接。
$x('//p')
[ <p>...</p>, <p>...</p> ]
$x('//a')
[ <a href="http://www.iana.org/domains/example">More information...</a> ]同样,//a 语法也可以在层次结构中的任何地方使用。比如,要想找到 div 元素下的所有链接,可以使用 //div//a。需要注意的是,只使用单斜线的 //div/a 将会得到一个空数组,这是因为在 example.com 中,'div' 元素的直接下级中并没有任何 'a' 元素:
$x('//div//a')
[ <a href="http://www.iana.org/domains/example">More information...</a> ]
$x('//div/a')
[ ]还可以选择属性。http://example.com/ 中的唯一属性是链接中的 href,可以使用符号 @ 来访问该属性,如下面的代码所示。
$x('//a/@href')
[ href="http://www.iana.org/domains/example" ]|
实际上,在 Chrome 的最新版本中,@href 不再返回 URL,而是返回一个空字符串。不过不用担心,你的 XPath 表达式仍然是正确的。 |
还可以通过使用 text() 函数,只选取文本。
$x('//a/text()')
[ "More information..." ]可以使用 * 符号来选择指定层级的所有元素。比如:
$x('//div/*')
[ <h1>Example Domain</h1>, <p>...</p>, <p>...</p> ]你将会发现选择包含指定属性(比如 @class)或是属性为特定值的元素非常有用。可以使用更高级的谓词来选取元素,而不再是前面例子中使用过的 p[1] 和 p[2]。比如,//a[@href] 可以用来选择包含 href 属性的链接,而 //a[@href="http://www.iana.org/domains/example"] 则是选择 href 属性为特定值的链接。
更加有用的是,它还拥有找到 href 属性中以一个特定子字符串起始或包含的能力。下面是几个例子。
$x('//a[@href]')
[ <a href="http://www.iana.org/domains/example">More information...</a>
]
$x('//a[@href="http://www.iana.org/domains/example"]')
[ <a href="http://www.iana.org/domains/example">More information...</a>
]
$x('//a[contains(@href, "iana")]')
[ <a href="http://www.iana.org/domains/example">More information...</a>
]
$x('//a[starts-with(@href, "http://www.")]')
[ <a href="http://www.iana.org/domains/example">More information...</a>]
$x('//a[not(contains(@href, "abc"))]')
[ <a href="http://www.iana.org/domains/example">More information...</a>]XPath 有很多像 not()、contains() 和 starts-with() 这样的函数,你可以在在线文档( http://www.w3schools.com/xsl/xsl_functions.asp )中找到它们,不过即使不使用这些函数,你也可以走得很远。
现在,我还要再多说一点,大家可以在 Scrapy 命令行中使用同样的 XPath 表达式。要打开一个页面并访问 Scrapy 命令行,只需要输入如下命令:
scrapy shell http://example.com在命令行中,可以访问很多在编写爬虫代码时经常需要用到的变量(参见下一章)。这其中最重要的就是响应,对于 HTML 文档来说就是 HtmlResponse 类,该类可以让你通过 xpath() 方法模拟 Chrome 中的 $x。下面是一些示例。
response.xpath('/html').extract()
[u'<html><head><title>...</body></html>']
response.xpath('/html/body/div/h1').extract()
[u'<h1>Example Domain</h1>']
response.xpath('/html/body/div/p').extract()
[u'<p>This domain ... permission.</p>', u'<p><a href="http://www.
iana.org/domains/example">More information...</a></p>']
response.xpath('//html/head/title').extract()
[u'<title>Example Domain</title>']
response.xpath('//a').extract()
[u'<a href="http://www.iana.org/domains/example">More
information...</a>']
response.xpath('//a/@href').extract()
[u'http://www.iana.org/domains/example']
response.xpath('//a/text()').extract()
[u'More information...']
response.xpath('//a[starts-with(@href, "http://www.")]').extract()
[u'<a href="http://www.iana.org/domains/example">More
information...</a>']这就意味着,你可以使用 Chrome 开发 XPath 表达式,然后在 Scrapy 爬虫中使用它们,正如我们在下一节中将要看到的那样。
使用 Chrome 获取 XPath 表达式
Chrome 通过向我们提供一些基本的 XPath 表达式,从而对开发者更加友好。从前文提到的检查元素开始:右键单击想要选取的元素,然后选择 Inspect Element。该操作将会打开 Developer Tools,并且在树表示法中高亮显示这个 HTML 元素。现在右键单击这里,在菜单中选择 Copy XPath,此时 XPath 表达式将会被复制到剪贴板中。上述过程如图2.6所示。
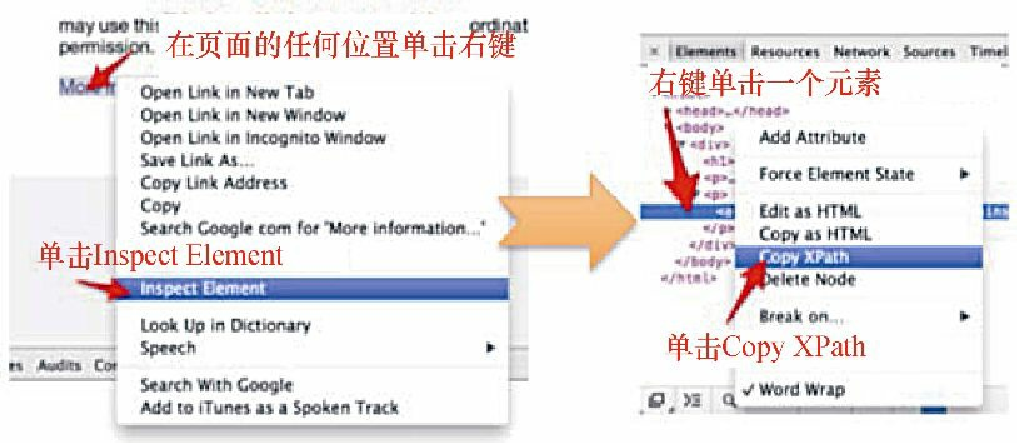
你可以和之前一样,在命令行中测试该表达式。
$x('/html/body/div/p[2]/a')
[ <a href="http://www.iana.org/domains/example">More information...</a>]常见任务示例
有一些 XPath 表达式,你将会经常遇到。让我们看一些目前在维基百科页面上的例子。维基百科拥有一套非常稳定的格式,所以我认为它们不会很快发生改变,不过改变终究还是会发生的。我们把如下这些表达式作为说明性示例。
-
获取 id 为 "firstHeading" 的 h1 标签下 span 中的 text。
//h1[@id="firstHeading"]/span/text() -
获取 id 为 "toc" 的 div 标签内的无序列表(ul)中所有链接 URL。
//div[@id="toc"]/ul//a/@href -
获取 class 属性包含 "ltr" 以及 class 属性包含 "skin-vector" 的任意元素内所有标题元素(h1)中的文本。这两个字符串可能在同一个 class 中,也可能在不同的 class 中。
//*[contains(@class,"ltr") and contains(@class,"skin-vector")]//h1//text()
实际上,你将会经常在 XPath 表达式中使用到类。在这些情况下,需要记住由于一些被称为 CSS 的样式元素,你会经常看到 HTML 元素在其 class 属性中拥有多个类。 比如,在一个导航系统中,你会看到一些 div 标签的 class 属性是 "link",而另一些是 "link active"。后者是当前激活的链接,因此会表现为可见或使用一种特殊的颜色(通过 CSS)高亮表示。当抓取时,你通常会对包含有特定类的元素感兴趣,具体来说,就是前面例子中的 "link" 和 "link active"。对于这种情况,XPath 的 contains() 函数可以让你选择包含有指定类的所有元素。
-
选择 class 属性值为 "infobox" 的表格中第一张图片的 URL。
//table[@class="infobox"]//img[1]/@src -
选择 class 属性以 "reflist" 开头的 div 标签中所有链接的 URL。
//div[starts-with(@class,"reflist")]//a/@href -
选择子元素包含文本 "References" 的元素之后的 div 元素中所有链接的 URL。
//*[text()="References"]/../following-sibling::div//a请注意该表达式非常脆弱并且很容易无法使用,因为它对文档结构做了过多假设。
-
获取页面中每张图片的 URL。
//img/@src
预见变化
抓取时经常会指向我们无法控制的服务器页面。这就意味着如果它们的 HTML 以某种方式发生变化后,就会使 XPath 表达式失效,我们将不得不回到爬虫当中进行修正。通常情况下,这不会花费很长时间,因为这些变化一般都很小。但是,这仍然是需要避免发生的情况。一些简单的规则可以帮助我们减少表达式失效的可能性。
-
避免使用数组索引(数值)
Chrome 经常会给你的表达式中包含大量常数,例如:
//*[@id="myid"]/div/div/div[1]/div[2]/div/div[1]/div[1]/a/img这种方式非常脆弱,因为如果像广告块这样的东西在层次结构中的某个地方添加了一个额外的 div 的话,这些数字最终将会指向不同的元素。本案例的解决方法是尽可能接近目标的 img 标签,找到一个可以使用的包含 id 或者 class 属性的元素,如:
//div[@class="thumbnail"]/a/img -
类并没有那么好用
使用 class 属性可以更加容易地精确定位元素,不过这些属性一般是用于通过 CSS 影响页面外观的,因此可能会由于网站布局的微小变更而产生变化。例如下面的 class:
//div[@class="thumbnail"]/a/img一段时间后,可能会变成:
//div[@class="preview green"]/a/img -
有意义的面向数据的类要比具体的或者面向布局的类更好
在前面的例子中,无论是 "thumbnail" 还是 "green" 都是我们所依赖类名的坏示例。虽然 "thumbnail" 比 "green" 确实更好一些,但是它们都不如 "departure-time"。前面两个类名是用于描述布局的,而 "departure-time" 更加有意义,与 div 标签中的内容相关。因此,在布局发生变化时,后者更可能保持有效。这可能也意味着该站的开发者非常清楚使用有意义并且一致的方式标注他们数据的好处。
-
ID通常是最可靠的
通常情况下,id 属性是针对一个目标的最佳选择,因为该属性既有意义又与数据相关。部分原因是 JavaScript 以及外部链接锚一般选择 id 属性以引用文档中的特定部分。例如,下面的 XPath 表达式非常健壮。
//*[@id="more_info"]//text()例外情况是以编程方式生成的包含唯一标记的 ID。这种情况对于抓取毫无意义。比如:
//[@id="order-F4982322"]尽管使用了 id,但上面的表达式仍然是一个非常差的 XPath 表达式。需要记住的是,尽管 ID 应该是唯一的,但是你仍然会发现很多 HTML 文档并没有满足这一要求。