Scrapyd
现在,我们将要开始介绍 Scrapyd。Scrapyd 这个应用允许我们在服务器上部署爬虫,并使用它们制定爬取的计划任务。让我们来感受一下使用它是多么简单吧。我们在开发机中已经预安装了该应用,所以可以立即使用第 3 章中的代码对其进行测试。我们在之前使用了几乎完全相同的过程,在这里只有一个小的变化。
首先,我们访问 http://localhost:6800/ ,来看一下 Scrapyd 的 Web 界面,如图 11.1 所示。
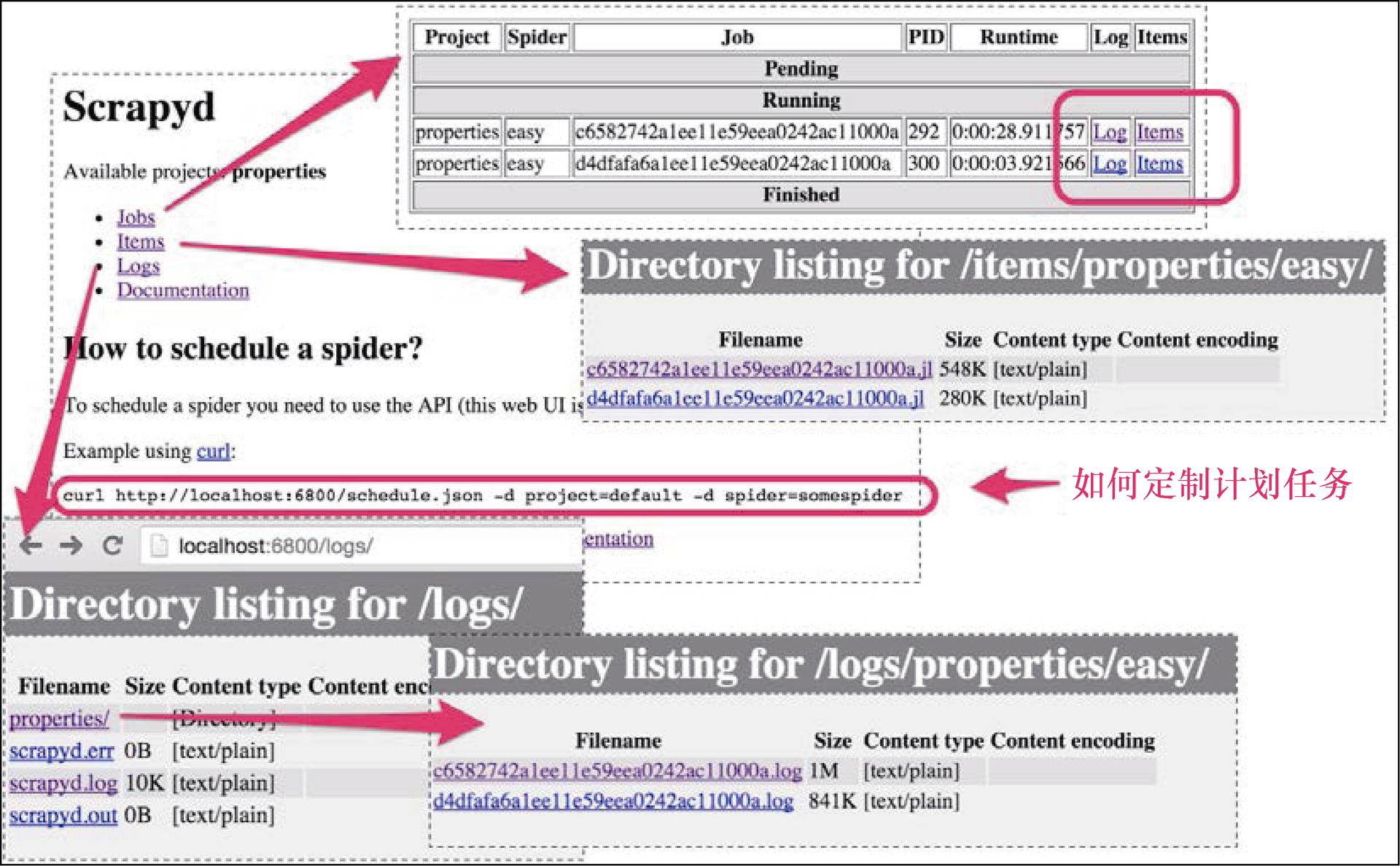
可以看出,Scrapyd 对于 Jobs、Items、Logs 和 Documentation 都有不同的区域。此外,它还提供了一些指引,告知我们如何使用其 API 定制计划任务。
为了完成该测试,我们必须先在 Scrapyd 服务器上部署爬虫。第一步是按照如下操作修改 scrapy.cfg 配置文件。
$ pwd
/root/book/ch03/properties
$ cat scrapy.cfg
...
[settings]
default = properties.settings
[deploy]
url = http://localhost:6800/
project = properties基本上,我们所有需要做的就是去除 url 一行的注释。默认的设置已经很合适了。现在,要想部署爬虫,需要使用 scrapyd-client 提供的 scrapyd-deploy 工具。scrapyd-client 曾经是 Scrapy 的一部分,不过现在已经独立为一个单独的模块,该模块可以使用 pip install scrapyd-client 安装(已经在开发机中安装好了该模块)。
$ scrapyd-deploy
Packing version 1450044699
Deploying to project "properties" in http://localhost:6800/addversion.json
Server response (200):
{"status": "ok", "project": "properties", "version": "1450044699", "spiders": 3, "node_name": "dev"}当部署成功后,可以在 Scrapyd 的 Web 界面主页的 Available projects 区域看到该项目。现在,可以按照提示在该页面提交一个任务。
$ curl http://localhost:6800/schedule.json -d project=properties -d
spider=easy
{"status": "ok", "jobid": " d4df...", "node_name": "dev"}如果回到 Web 界面的 Jobs 区域,可以看到任务正在运行。稍后可以使用 schedule.json 返回的 jobid,通过 cancel.json 取消该任务。
$ curl http://localhost:6800/cancel.json -d project=properties -d job=d4df...
{"status": "ok", "prevstate": "running", "node_name": "dev"}请一定记住执行取消操作,否则你会浪费一段时间的计算机资源。
非常好!当访问 Logs 区域时,可以看到日志;而当访问 Items 区域时,可以看到刚才爬取的 Item。这些都会在一定周期之后清空以释放空间,因此在几次爬取操作后这些内容可能就不再可用。
如果有合理的理由,比如冲突,那么我们可以使用 http_port 修改端口,这是 Scrapyd 提供的诸多设置之一。通过访问 http://scrapyd.readthedocs.org/ 来了解 Scrapyd 的文档是非常值得的。在本章中,我们需要修改的一个重要设置是 max_proc。如果将该设置保留为默认值 0 的话,Scrapyd 将在 Scrapy 任务运行时允许 4 倍于 CPU 数量的并发。由于我们将运行多个 Scrapyd 服务器,并且大部分可能是在虚拟机当中的,因此我们将会设置该值为 4,即允许至多 4 个任务并发运行。这与本章的需求有关,而在实际部署当中,一般情况下使用默认值就能够良好运行。