基本设置
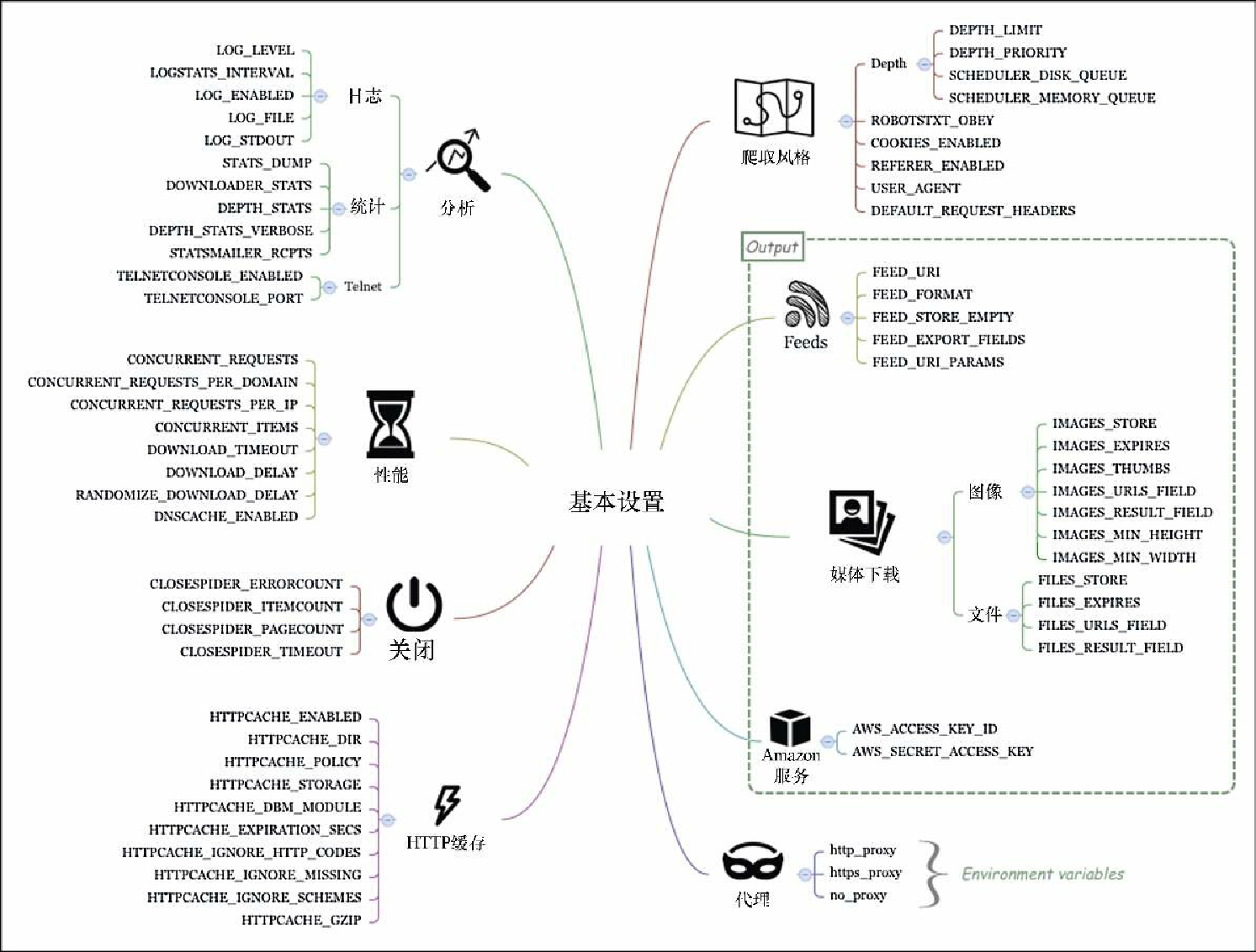
Scrapy 包含非常多的设置,因此为其分类成为了一个迫切的需求。我们将会从图7.1中总结出的大部分基本设置开始讨论。通过它们了解重要的系统特性,并且我们还将频繁地调整它们。
分析
使用这些设置,你可以配置 Scrapy,使其通过日志、统计和 Telnet 工具提供性能和调试信息。
日志
Scrapy 基于严重程度,拥有不同的日志等级:DEBUG(最低等级)、INFO、WARNING、ERROR 及 CRITICAL(最高等级)。除此之外,还有一个 SILENT 等级,使用它将不记录任何日志。通过将 LOG_LEVEL 设置为希望日志记录的最低级别,可以限制日志文件只接受指定等级以上的日志。我们一般将该值设为 INFO,因为 DEBUG 级别过于详细。一个非常有用的 Scrapy 扩展是 Log Stats 扩展,该扩展会打印出每分钟抓取的 item 和页面的数量。日志频率使用 LOGSTATS_INTERVAL 进行设置,其默认值为 60 秒。该设置的频率过低,所以在我开发时,会将该值设置为 5 秒,因为大多数运行都很短暂。写入日志的文件可以通过 LOG_FILE 设置。除非将 LOG_ENABLED 的值设置为 False 进行显式禁用,否则日志将会输出到标准错误当中。最后,可以通过设置 LOG_STDOUT 为 True,告知 Scrapy 将所有标准输出(比如:"print" 消息)写入日志。
统计
STATS_DUMP 默认是开启的,它会在爬虫结束运行时,将统计信息收集器中的值转存到日志当中。可以通过将 DOWNLOADER_STATS 设置为 False,控制是否为下载记录统计信息。还可以通过 DEPTH_STATS 设置,控制是否收集站点深度的统计信息。要想了解有关深度的更多细节,可以将 DEPTH_STATS_VERBOSE 设为 True。STATSMAILER_RCPTS 是一个邮件列表(比如设置为['my@mail.com']),当爬取完成时,会向该列表中的邮箱发送邮件。无需经常调整这些设置,不过它们偶尔会在调试时帮助到你。
Telnet
Scrapy 包含一个内置的 Telnet 控制台,可以为你提供正在运行中的 Scrapy 进程的 Python shell。TELNETCONSOLE_ENABLED 默认情况下是开启的,而 TELNETCONSOLE_PORT 决定了连接到控制台的端口。你可能需要修改该值,以防止端口冲突。
示例1——使用 Telnet
在某些情况下,需要查看正在运行的 Scrapy 的内部状态。下面让我们看看如何使用 Telnet 控制台完成该操作。
|
$ pwd /root/book/ch07/properties $ ls properties scrapy.cfg |
使用如下命令开始爬取。
$ scrapy crawl fast
...
[scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023:6023上面的消息意味着 Telnet 已经被激活,并且使用 6023 端口进行监听。现在,可以在另一个终端中,使用 telnet 命令连接它。
$ telnet localhost 6023
>>>此时,该控制台会提供一个 Scrapy 内部的 Python 控制台。你可以查看某些组件,比如使用 engine 变量查看引擎,不过为了能够更快地了解状态概况,可以使用 est() 命令。
>>> est()
Execution engine status
time()-engine.start_time : 5.73892092705
engine.has_capacity() : False
len(engine.downloader.active) : 8
...
len(engine.slot.inprogress) : 10
...
len(engine.scraper.slot.active) : 2第 10 章将会探讨其中的一些度量标准。此时将发现你依然是在 Scrapy 引擎内部运行它。假设使用了如下命令:
>>> import time
>>> time.sleep(1) # Don't do this!此时,你会发现在另一个终端中会出现短暂的暂停。显然,该控制台不是用来计算 Pi 值前 100 万位的合适地点。你可以在该控制台中操作的事情还包括暂停、继续和终止爬取。你可能会发现,在远程机器操作 Scrapy 会话时,这些事情和终端通常都很有用。
>>> engine.pause()
>>> engine.unpause()
>>> engine.stop()
Connection closed by foreign host.性能
第 10 章将会详细介绍关于性能的设置,这里仅作为一个小结。性能设置可以让我们根据特定的工作负载调整 Scrapy 的性能特性。CONCURRENT_REQUESTS 用于设置同时执行的最大请求数。大多数情况下,该设置用于防止在爬取不同网站(域名/IP) 时超出服务器出站容量。除此之外,还可以找到更加严格的 CONCURRENT_REQUESTS_PER_DOMAIN 以及 CONCURRENT_REQUESTS_PER_IP。 这两个设置分别通过限制同时对每个域名或 IP 地址发出的请求数,达到保护远程服务器的效果。当 CONCURRENT_REQUESTS_PER_IP 为非零值时,CONCURRENT_REQUESTS_PER_DOMAIN 就会被忽略。这些设置不是以秒为单位的。如果 CONCURRENT_REQUESTS = 16,而请求平均花费 1/4 秒的话,你的限制就是每秒 16/0.25 = 64 个请求。CONCURRENT_ITEMS 用于设置对每个响应同时处理的最大 item 数量。你可能会发现该设置并没有它看起来那么实用,因为很多情况下,每个页面或请求中只有一个 Item。并且,其默认值 100 也比较随意。如果减小该值,比如减小到 10 或者 1,你甚至可能会看到性能提升,这取决于每个请求的 Item 数量,以及管道的复杂程度。还需要注意的是,由于该值是每个请求时的数量,如果限制了 CONCURRENT_REQUESTS = 16、CONCURRENT_ITEMS = 100,那么可能意味着会有 1600 个 item 同时在尝试写入数据库。一般来说,建议将该值设置得更保守一些。
对于下载,DOWNLOAD_TIMEOUT 决定了下载器在取消一个请求之前需要等待的时间,其默认值为 180 秒,这似乎有些偏高(当并发请求数为 16 时,这意味着站点下载的速度大约为 5 页/分钟)。建议降低该值,比如当存在超时问题时,将其降低为 10 秒。默认情况下,Scrapy 将两次下载间的延迟设置为 0,以最大化抓取速度。可以使用 DOWNLOAD_DELAY 设置将其修改为更加保守的下载速度。有些网站会将请求频率作为 “机器人” 行为的测量指标。通过设置 DOWNLOAD_DELAY,还会在下载延迟中启用一个 ±50% 的随机偏移量。可以通过将 RANDOMIZE_DOWNLOAD_DELAY 设置为 False 来禁用该功能。
最后,为了更快的 DNS 查找,Scrapy 默认使用了 DNSCACHE_ENABLED 设置,启用了内存中的 DNS 缓存。
提前终止爬取
Scrapy 的 CloseSpider 扩展可以在达成某个条件时,自动终止爬虫爬取。可以分别使用 CLOSESPIDER_TIMEOUT(以秒计)、CLOSESPIDER_ITEMCOUNT、CLOSESPIDER_PAGECOUNT 以及 CLOSESPIDER_ERRORCOUNT 这些设置,配置在一段时间后、抓取一定数量 item 后、接收到一定数量响应后或是遇到一定数量错误后,关闭爬虫。通常情况下,你会在运行爬虫时使用命令行的方式设置这些内容,我们已经在前面的几章中做过几次此类操作。
$ scrapy crawl fast -s CLOSESPIDER_ITEMCOUNT=10
$ scrapy crawl fast -s CLOSESPIDER_PAGECOUNT=10
$ scrapy crawl fast -s CLOSESPIDER_TIMEOUT=10HTTP缓存和离线运行
Scrapy 的 HttpCacheMiddleware 组件(默认未激活)为 HTTP 请求和响应提供了一个低级的缓存。当启用该组件时,缓存会存储每个请求及其对应的响应。通过将 HTTPCACHE_POLICY 设置为 scrapy.contrib.httpcache.RFC2616Policy, 可以启用一个遵从 RFC2616 的更复杂的缓存策略。为了启用该缓存,还需要将 HTTPCACHE_ENABLED 设置为 True,并将 HTTPCACHE_DIR 设置为文件系统中的一个目录(使用相对路径将会在项目的数据文件夹下创建一个目录)。
还可以选择通过设置存储后端类 HTTPCACHE_STORAGE 为 scrapy.contrib.httpcache.DbmCacheStorage,为缓存文件指定数据库后端,并且还可以选择调整 HTTPCACHE_DBM_MODULE 设置(默认为任意数据库管理系统)。还有一些设置可以用于缓存行为调优,不过默认值已经能够为你很好地服务了。
示例2——使用缓存的离线运行
假设你运行了如下代码:
$ scrapy crawl fast -s LOG_LEVEL=INFO -s CLOSESPIDER_ITEMCOUNT=5000你会发现大约一分钟后运行可以完成。如果此时无法访问 Web 服务器,可能就无法爬取任何数据。假设你现在使用如下代码,再次运行爬虫。
$ scrapy crawl fast -s LOG_LEVEL=INFO -s CLOSESPIDER_ITEMCOUNT=5000 -s
HTTPCACHE_ENABLED=1
...
INFO: Enabled downloader middlewares:...*HttpCacheMiddleware*你会注意到此时启用了 HttpCacheMiddleware,当查看当前目录下的隐藏目录时,将会发现一个新的 .scrapy 目录,目录结构如下所示。
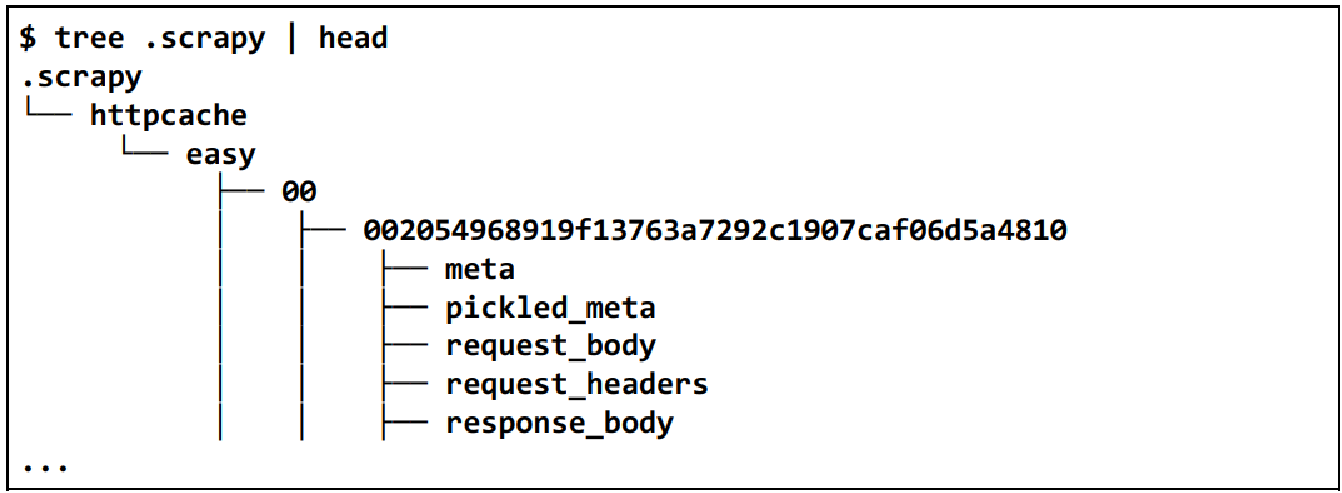
现在,如果重新运行爬虫,获取略少于前面数量的 item 时,就会发现即使在无法访问 Web 服务器的情况下,也能完成得更加迅速。
$ scrapy crawl fast -s LOG_LEVEL=INFO -s CLOSESPIDER_ITEMCOUNT=4500 -s HTTPCACHE_ENABLED=1我们使用了略少于前面数量的 item 作为限制,是因为当使用 CLOSESPIDER_ITEMCOUNT 结束时,一般会在爬虫完全结束前读取更多的页面,但我们不希望命中的页面不在缓存范围内。要想清理缓存,只需删除缓存目录即可。
$ rm -rf .scrapy爬取风格
Scrapy 允许我们调整选择优先爬取页面的方式。可以在 DEPTH_LIMIT 设置中设定最大深度,该值为 0 时表示不限制。通过 DEPTH_PRIORITY 设置,可以基于请求的深度指定优先级。最值得注意的是,可以将该值设置为正数,以执行广度优先爬取,并将任务队列由 LIFO(后入先出)转为 FIFO(先入先出):
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'在爬取时进行这些设置非常有用,比如,在一个新闻门户网站中,最近的新闻更应该接近首页,并且每个新闻页都有到其他相关新闻的链接。Scrapy 的默认行为是对首页的前几个新闻报道进行尽可能深地爬取,之后才会继续爬取接下来的头版新闻。而广度优先的顺序则是首先爬取最顶层的新闻,之后才会进一步深入,当结合 DEPTH_LIMIT 设置时,比如设为 3,可以让你快速浏览门户网站中最近的新闻。
网站在其根目录下使用 Web 标准的 robots.txt 文件,声明它们允许的爬取策略,以及不希望被访问的网站结构。如果将 ROBOTSTXT_OBEY 设置为 True,Scrapy 将会遵守该约定。如果启用了该设置,请在调试时记住该点,以防发现任何意外的行为。
CookiesMiddleware 显然包含了和 cookie 相关的所有操作,其中包括会话跟踪、准许登录等。如果你想拥有更 “私密” 的爬取,可以通过将 COOKIES_ENABLED 设置 False 以禁用。禁用 cookie 还会轻微降低你使用的带宽,并且可能会对你的爬取操作有一点提速,当然它会依赖于你爬取的网站。与 CookiesMiddleware 类似, REFERER_ENABLED 的默认设置是 True,即启用了用于填充 Referer 头的 RefererMiddleware。可以使用 DEFAULT_REQUEST_HEADERS 自定义头部。你可能会发现该设置对于某些奇怪的网站很有用,在这些网站中只有包含了特定请求头的请求才不会被禁止。最后,自动生成的 settings.py 文件推荐我们设置 USER_AGENT。该设置的默认值是 Scrapy 的版本,而我们需要将其修改为能够让网站拥有者联系到我们的信息。
feed
feed 可以让你将 Scrapy 抓取得到的数据输出到本地文件系统或远程服务器当中。FEED_URI.FEED_URI 决定了 feed 的位置,该设置中可能会包含命名参数。比如, scrapy fast -o "%(name)s_% (time)s.jl" 将会自动以当前时间和爬虫名称(fast)填充输出文件名。如果需要使用一个自定义参数,比如 %(foo)s,那么 feed 输出器需要你在爬虫中提供 foo 属性。此外,feed 的存储,如 S3、FTP 或本地文件系统,也定义在 URI 中。例如,FEED_URI='s3://mybucket/file.json' 将使用你的 Amazon 凭证(AWS_ACCESS_KEY_ID 和 AWS_SECRET_ACCESS_KEY)上传文件到 Amazon 的 S3 当中。Feed 的格式(JSON、 JSON Line、 CSV 及 XML)可以使用 FEED_FORMAT 确定。如果没有设定该设置,Scrapy 将会根据 FEED_URI 的扩展名猜测格式。通过将 FEED_STORE_EMPTY 设置为 True,可以选择输出空的 feed。此外,还可以使用 FEED_EXPORT_FIELDS 设置,选择只输出指定的几个字段。该设置对于具有固定标题列的 .csv 文件尤其有用。最后,FEED_URI_PARAMS 用于定义对 FEED_URI 中任意参数进行后置处理的函数。
媒体下载
Scrapy 可以使用图像管道下载媒体内容,此外还可以将图像转换为不同的格式、生成缩略图以及基于大小过滤图像。
IMAGES_STORE 设置用于设定图像存储的目录(使用相对路径时,将会在项目根目录下创建目录)。每个 Item 的图像 URL 应该在 image_urls 字段中设定(可以被 IMAGES_URLS_FIELD 设置覆写),而下载图像的文件名则是在一个新的 images 字段中设定(可以被 IMAGES_RESULT_FIELD 设置覆写)。可以使用 IMAGES_MIN_WIDTH 和 IMAGES_MIN_HEIGHT 设置过滤过小的图像。 IMAGES_EXPIRES 决定了图像在过期前保留在缓存中的天数。对于缩略图的生成,可以使用 IMAGES_THUMBS 设置,它可以让你按照一种或多种尺寸生成缩略图。比如,可以让 Scrapy 生成一种图标大小的缩略图以及一种用于每次图像下载时的中等大小缩略图。
其他媒体
可以使用文件管道下载其他媒体文件。与图像类似,FILES_STORE 设置用于确定已下载文件的存放位置,而 FILES_EXPIRES 设置用于确定文件保留的天数。FILES_URLS_FIELD 以及 FILES_RESULT_FIELD 设置都和对应的 IMAGES_* 设置的功能相似。文件管道和图像管道可以同时激活,不会产生冲突。
示例3——下载图像
为了能够使用图像功能,必须使用 sudo pip install image 安装图像包。在我们的开发机中,已经为大家安装好该三方包了。想要启用图像管道,只需要编辑项目的 settings.py 文件,添加少量设置。首先,需要在 ITEM_PIPELINES 中包含 scrapy.pipelines.images.ImagesPipeline。然后,设置 IMAGES_STORE 为相对路径 "images",此外还可以选择通过 IMAGES_THUMBS 设置一些缩略图的描述,相关代码如下所示。
ITEM_PIPELINES = {
...
'scrapy.pipelines.images.ImagesPipeline': 1,
}
IMAGES_STORE = 'images'
IMAGES_THUMBS = { 'small': (30, 30) }我们在 Item 中已经包含了合适的 image_urls 字段,所以现在可以参照如下命令执行爬虫了。
$ scrapy crawl fast -s CLOSESPIDER_ITEMCOUNT=90
...
DEBUG: Scraped from <200 http://http://web:9312/.../index_00003.html/
property_000001.html>{
'image_urls': [u'http://web:9312/images/i02.jpg'],
'images': [{'checksum': 'c5b29f4b223218e5b5beece79fe31510',
'path': 'full/705a3112e67...a1f.jpg',
'url': 'http://web:9312/images/i02.jpg'}],
...
$ tree images
images
├── full
│ ├── 0abf072604df23b3be3ac51c9509999fa92ea311.jpg
│ ├── 1520131b5cc5f656bc683ddf5eab9b63e12c45b2.jpg
...
└── thumbs
└── small
├── 0abf072604df23b3be3ac51c9509999fa92ea311.jpg
├── 1520131b5cc5f656bc683ddf5eab9b63e12c45b2.jpg
...可以看到图像成功下载,并且创建了缩略图。主文件的 JPG 名称按照预期存储在了 images 字段当中,因此很容易推测缩略图的路径。如果想要清空图像,我们可以使用 rm -rf images。
Amazon Web服务
Scrapy 对访问 Amazon Web 服务有内置支持。你可以在 AWSACCESS_KEY_ID 设置中存储 AWS 访问密钥,在 AWS_SECRET_ACCESS_KEY 设置中存储私密密钥。默认情况下,这些设置均为空。可以在如下场景中使用:
-
当下载以 s3:// 开头的 URL 时(而不是 https:// 等);
-
当通过媒体管道使用 s3:// 路径存储文件或缩略图时;
-
当在 s3:// 目录中存储 Item 的输出 Feed 时。
不要将这些设置存储在 settings.py 文件当中,以防未来某天由于任何原因造成代码公开时被泄露。
使用代理和爬虫
Scrapy 的 HttpProxyMiddleware 组件允许你使用代理设置,根据 UNIX 约定,这些设置是通过 http_proxy、https_proxy 以及 no_proxy 这几个环境变量定义的。该组件默认是启用状态的。
示例4——使用代理和Crawlera的智能代理
DynDNS(或任何类似的服务)提供了一个免费的在线工具,用于查看当前的 IP 地址。使用 Scrapy shell,我们向 checkip.dyndns.org 发送请求,查看响应,获取当前的 IP 地址。
$ scrapy shell http://checkip.dyndns.org
>>> response.body
'<html><head><title>Current IP Check</title></head><body>Current IP
Address: xxx.xxx.xxx.xxx</body></html>\r\n'
>>> exit( )想要开始代理请求,需要退出 shell,并使用 export 命令设置新的代理。可以通过搜索 HMA 的公开代理列表测试免费代理( http://proxylist.hidemyass.com )。比如,我们从该列表中选择了一个 IP 为 10.10.1.1、端口为 80 的代理(非真实存在的代理,请将其替换为你自己的代理地址),可以按照如下操作。
$ # First check if you already use a proxy
$ env | grep http_proxy
$ # We should have nothing. Now let's set a proxy
$ export http_proxy=http://10.10.1.1:80按照刚才的步骤重新运行 scrapy shell,可以看到执行的请求使用了不同的 IP。此外,你还会发现这些代理通常速度都很慢,而且在一些情况下无法成功,如果遇到这类情况,可以尝试更换为其他的代理。如果想要禁用代理,则需要退出 Scrapy shell,并执行 unset http_proxy(或恢复为之前的值)。
Crawlera 是 Scrapinghub 的一项服务,可以为 Scrapy 的开发者提供一个非常智能的代理。除了在后台使用很大的 IP 池路由你的请求外,该代理还会调整延迟和失败重试,让你在保持尽可能快的情况下,获得尽可能多且稳定的成功响应流。它基本上可以使爬虫开发者的梦想成真,并且只需像之前那样,设置 http_proxy 环境变量,就可以使用。
$ export http_proxy=myusername:mypassword@proxy.crawlera.com:8010除了 HTTP 代理外,Crawlera 还可以通过 Scrapy 的中间件组件方式使用。