故障排除流程
总结来说,Scrapy 在设计时就将下载器作为瓶颈。从一个低数值的 CONCURRENT_REQUESTS 开始,逐渐增加,直到触及下述限制之一:
-
CPU 使用率大于 80%~90%;
-
源网站延迟过度增长;
-
抓取程序中响应达到了 5MB 的内存限制。
同时,执行以下操作:
-
始终保持调度器队列(mqs/dqs)中至少有一定量的请求,避免下载器出现 URL 饥饿;
-
永远不要使用任何阻塞代码或 CPU 密集型代码。
图 10.13 总结了诊断并修复 Scrapy 性能问题的过程。
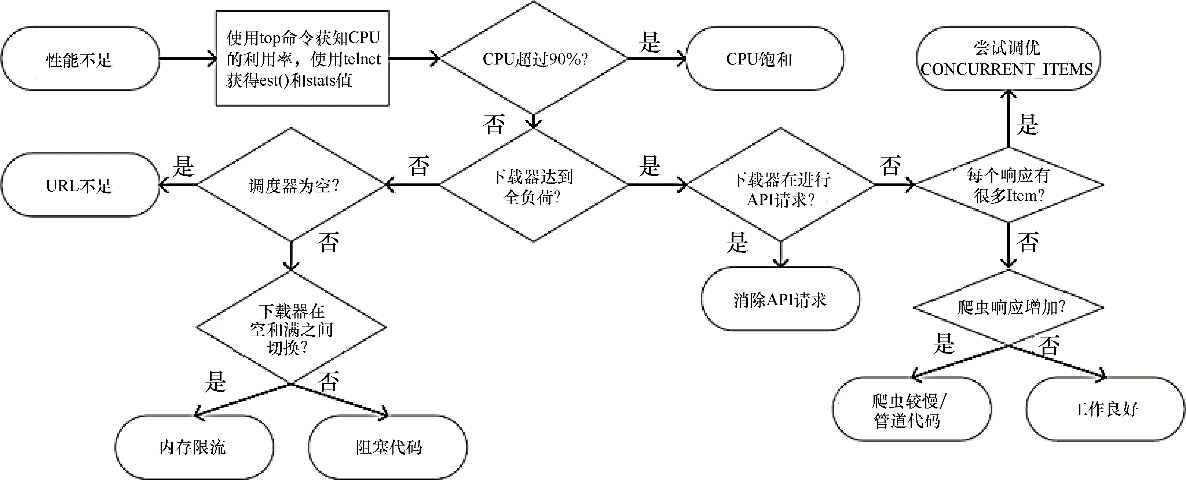
Figure 1. 图10.13 Scrapy性能问题故障排除
本章小结
在本章中,我们尝试通过给出几个有趣的案例,来突出 Scrapy 架构的优秀性能。具体细节可能会在未来版本的 Scrapy 中有所变更,不过本章提供的知识应当会在很长一段时间内保持有效,并且可能会帮助你处理基于 Twisted、Netty Node.js 或类似框架的任何高并发异步系统。
当谈到 Scrapy 的性能问题时,有 3 个有效的答案:我不知道也不介意;我不知道但我会找出来;我知道。正如我们在本章中多次论证的,天真地回答 “我们需要更多的服务器/内存/带宽” 更有可能与 Scrapy 的性能无关。人们需要真正理解瓶颈在什么地方,并且去提升它。
在最后一章中,我们将进一步专注提升性能,通过在多台服务器上分布式部署爬虫,达到超越单机的能力。