UR2IM基本抓取流程
每个网站都是不同的,如果发现某些不常见的情况,则需要一些额外的学习,或是在 Scrapy 的邮件列表中咨询一些问题。不过,为了知道在哪里和如何搜索,重要的是对其流程有一个整体的了解,并且清楚相关的术语。和 Scrapy 打交道时,你所遵循的最通用的流程是 UR2IM 流程,如图3.3所示。
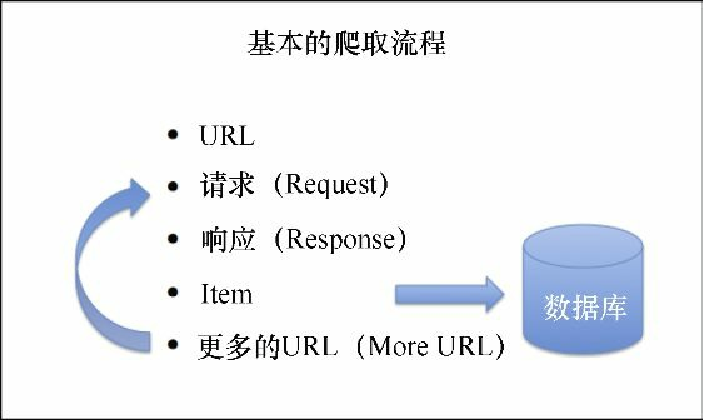
URL
一切始于URL。你需要从准备抓取的网站中选择几个示例 URL。我将使用 Gumtree 分类广告网站(https://www.gumtree.com)作为示例进行演示。
比如,通过访问 Gumtree 上的伦敦房产主页(链接为 http://www.gumtree.com/flats-houses/london ),你能够找到一些房产的示例 URL。可以通过右键单击分类列表,选择 Copy Link Address(复制链接地址)或你浏览器中同样的功能,来复制这些链接。比如,其中一个可能类似于 https://www.gumtree.com/p/studios-bedsits-rent/splitlevel 。虽然可以在真实网站中使用这些 URL 来操作,但不幸的是,经过一段时间后,真实的 Gumtree 网站可能会发生变化,造成 XPath 表达式无法正常工作。此外,除非设置一个用户代理头,否则 Gumtree 不会回应你的请求。稍后我们会对此进行更进一步的讲解,不过就现在而言,如果想加载它们的某个页面,可以在 scrapy shell 中使用如下命令。
scrapy shell -s USER_AGENT="Mozilla/5.0" <your url here e.g. http://www.gumtree.com/p/studios-bedsits-rent/...>如果想要在使用 scrapy shell 时调试问题,可以使用 --pdb 参数启用交互式调试,以避免发生异常。例如:
scrapy shell --pdb https://gumtree.com|
scrapy shell 是一个非常有用的工具,能够帮助我们使用 Scrapy 开发。 |
很显然,我们并不鼓励你在学习本书内容时访问 Gumtree 的网站,我们也不希望本书的示例在不久之后就无法使用。此外,我们还希望即使无法连接互联网,你仍然能够开发和使用我们的示例。这就是为什么你的 Vagrant 开发环境中包含一个提供了类似于 Gumtree 网站页面的 Web 服务器的原因。虽然它们可能不如真实网站那么漂亮,但是从爬虫角度来说,它们其实是一样的。即便如此,我们在本章中的所有截图还是来自真实的 Gumtree 网站。在你 Vagrant 的 dev 机器中,可以通过 http://web:9312/访问该Web服务器,而在你的浏览器中,可以通过 http://localhost:9312/来访问。
在 scrapy shell 中打开服务器中的一个网页,并且在 dev 机器上输入如下内容进行操作。
$ scrapy shell http://web:9312/properties/property_000000.html
...
[s] Available Scrapy objects:
[s] crawler <scrapy.crawler.Crawler object at 0x2d4fb10>
[s] item {}
[s] request <GET http:// web:9312/.../property_000000.html>
[s] response <200 http://web:9312/.../property_000000.html>
[s] settings <scrapy.settings.Settings object at 0x2d4fa90>
[s] spider <DefaultSpider 'default' at 0x3ea0bd0>
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local...
[s] view(response) View response in a browser
>>>我们得到了一些输出,现在可以在 Python 提示符下,用它来调试刚才加载的页面(一般情况下,可以使用 Ctrl + D 退出)。
请求和响应
大家可能注意到在前面的日志中,scrapy shell 本身已经为我们做了一些工作。我们给出了一个 URL,然后它执行了一个默认的 GET 请求,并得到了一个状态码为 200 的响应。这就意味着,页面信息已经加载完毕,可以使用了。如果想要打印 response.body 的前 50 个字符,可以按如下命令操作。
>>> response.body[:50]
'<!DOCTYPE html>\n<html>\n<head>\n<meta charset="UTF-8"'|
[:50]是什么?这是 Python 从文本变量(本例为 response.body)中抽取最前面 50 个字符(如果存在)的方式。如果你之前并不了解 Python,请保持冷静,继续向前。很快,你就会熟悉并享受所有这些语法技巧了。 |
这是 Gumtree 上指定页面的 HTML 内容。请求和响应部分不会给我们带来太多麻烦。不过,在很多情况下,你需要做一些工作才能保证其正确。第 5 章中讲到这些内容。就目前来说,我们尽量保持简单,直接进入下一部分——Item。
Item
下一步是尝试从响应中将数据抽取到 Item 的字段中。因为该页面的格式是 HTML,因此可以使用 XPath 表达式进行操作。首先,让我们看一下这个页面,如图3.4所示。
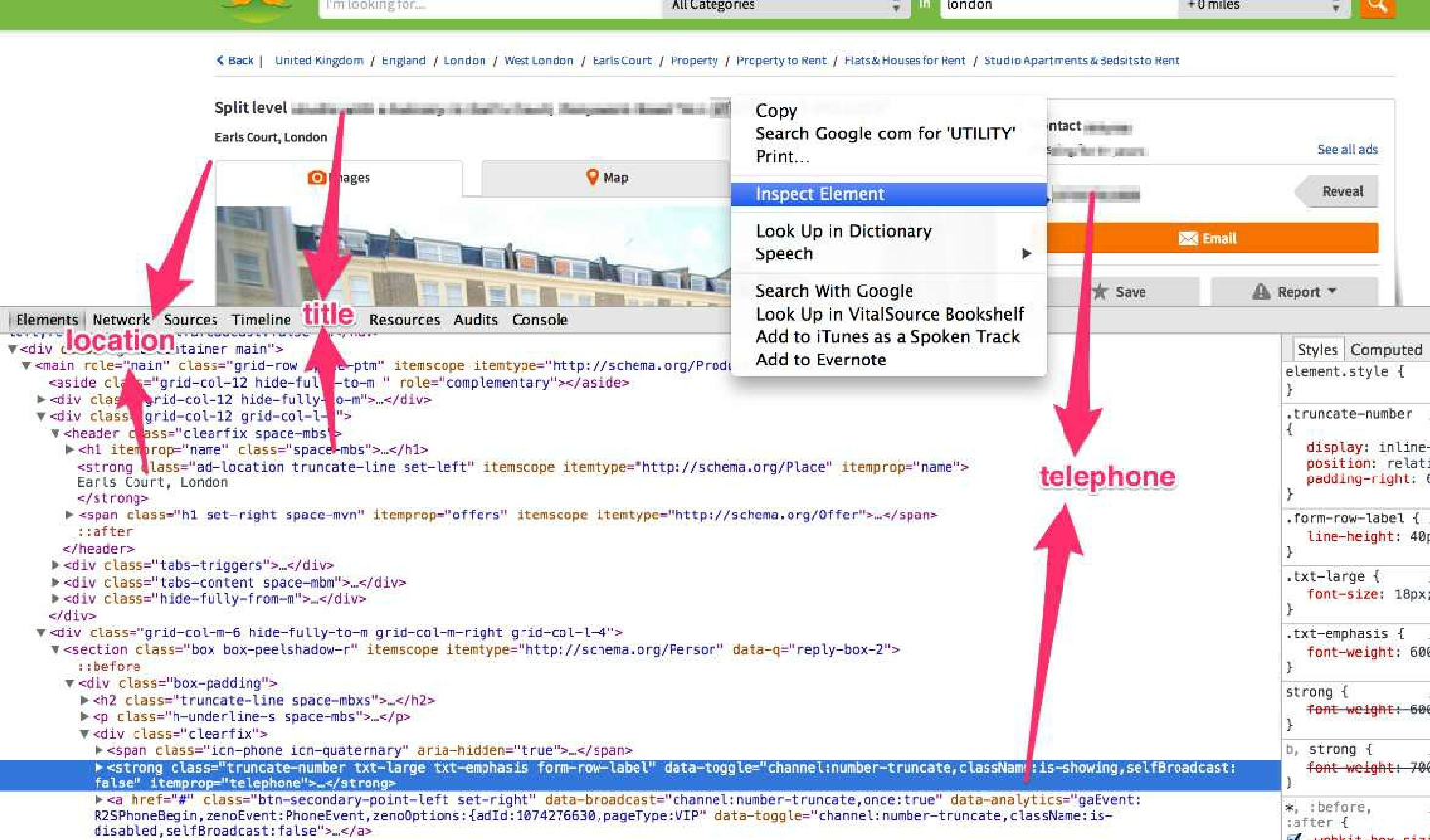
在图3.4中有大量的信息,但其中大部分都是布局:logo、搜索框、按钮等。虽然这些信息都很有用,但是爬虫并不会对其产生兴趣。我们可能感兴趣的字段,比如说包括房源的标题、位置或代理商的电话号码,它们都具有对应的 HTML 元素,我们需要定位到这些元素, 然后使用前一节中所描述的流程抽取数据。那么,先从标题开始吧(如图3.5 所示)。
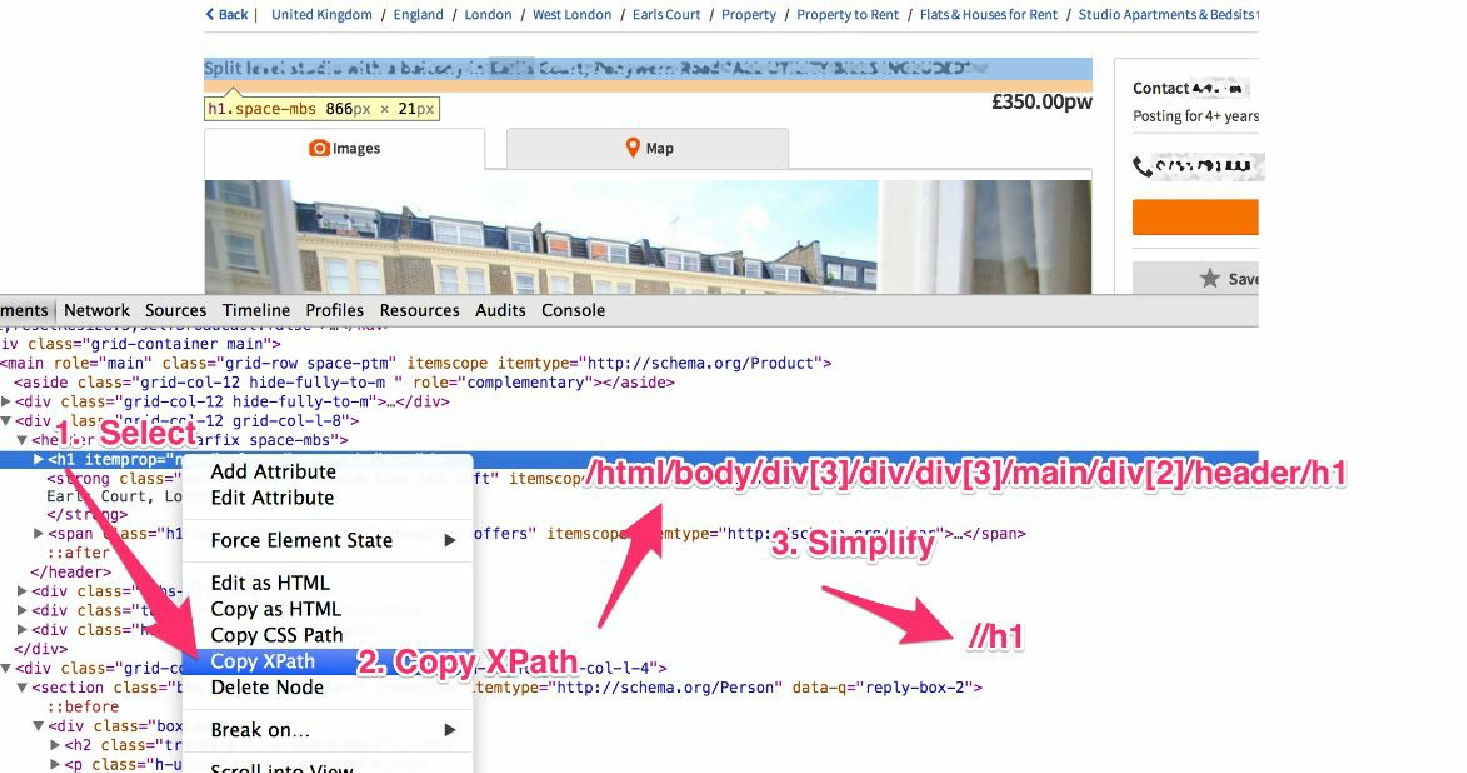
右键单击页面上的标题,并选择 Inspect Element。这样就可以看到相应的 HTML 源代码了。现在,尝试通过右键单击并选择 Copy XPath,抽取标题的 XPath 表达式。你会发现 Chrome 浏览器给我们的 XPath 表达式很精确,但又十分复杂,因此该表达式是非常脆弱的。我们将对其进行一些简化,只使用最后的一部分,通过使用表达式 //h1,选择在页面中可以看到的任何 H1 元素。尽管这种方式有些误导,因为我们并不是真的需要页面中的每一个 H1,不过实际上这里只有标题使用了 H1;而作为优秀的 SEO 实践,每个页面应当只有一个 H1 元素,并且大部分网站确实是这样的。
|
SEO 是 Search Engine Optimization(搜索引擎优化)的缩写,即通过优化网站代码、内容和出入站链接的流程,实现提供给搜索引擎的最佳方式。 |
我们来检查下该 XPath 表达式能否在 scrapy shell 中良好运行。
>>> response.xpath('//h1/text()').extract()
[u'set unique family well']非常好,完美工作。你应该已经注意到我在 //h1 表达式的结尾处添加了 /text()。如果想要只抽取 H1 元素所包含的文本内容,而不是 H1 元素自身的话,就需要使用到它。我们通常都会使用 /text() 来获得文本字段。如果忽略它,就会得到整个元素的文本,包括并不需要的标记。
>>> response.xpath('//h1').extract()
[u'<h1 itemprop="name" class="space-mbs">set unique family well</h1>']此时,我们就得到了抽取本页中第一个感兴趣的属性(标题)的代码,不过如果你观察得更仔细的话,就会发现还有一种更好更简单的方法也可以做到。
Gumtree 通过微数据标记注解它们的 HTML。比如,我们可以看到,在其头部有一个 itemprop="name" 的属性,如图3.6所示。非常好,这样我们就可以使用一个更简单的 XPath 表达式,而不再包含任何可视化元素了,此时得到的表达式为 //*[@itemprop="name"][1]/text()。你可能会奇怪为什么我们选择了包含 itemprop="name" 的第一个元素。

|
稍等!你是说第一个?如果你是一个经验丰富的程序员,可能已经将 array[1] 作为数组的第二个元素了。令人惊讶的是,XPath 是从 1 开始的,因此 array[1] 是数组的第一个元素。 |
我们这么做,不只是因为 itemprop="name" 在许多不同的上下文中作为微数据来使用,还因为 Gumtree 在其页面的 “你可能还喜欢……” 部分为其他属性使用了嵌套的信息,以这种方式阻止我们对其轻易识别。尽管如此,这并不是一个大问题。我们只需要选择第一个,而且我们也将使用同样的方式处理其他字段。
让我们来看一下价格。价格被包含在如下的 HTML 结构当中。
<strong class="ad-price txt-xlarge txt-emphasis" itemprop="price">£334.39pw</strong>我们又一次看到了 itemprop="name" 这种形式,太棒了。此时,XPath 表达式将会是 //*[@itemprop="price"][1]/text()。我们来试一下吧。
>>> response.xpath('//*[@itemprop="price"][1]/text()').extract()
[u'\xa3334.39pw']我们注意到,这里包含一些 Unicode 字符(英镑符号 £),然后是 334.39pw 的价格。这表明数据并不总是像我们希望的那样干净,所以可能还需要对其进行一些清洗的工作。比如,在本例中,我们可能需要使用一个正则表达式,以便只选择数字和点号。可以使用 re() 方法做到这一要求,并使用一个简单的正则表达式替代 extract()。
>>> response.xpath('//*[@itemprop="price"][1]/text()').re('[.0-9]+')
[u'334.39']|
这里使用了一个 response 对象,并调用了它的 xpath() 方法来抽取感兴趣的值。不过,xpath() 返回的值是什么呢? 如果在一个简单的 XPath 表达式中,不使用 .extract() 方法,将会得到如下的显示输出: xpath() 返回了网页内容预加载的 Selector 对象。我们目前只使用了 xpath() 方法,不过它还有另一个有用的方法:css()。xpath() 和 css() 都会返回选择器,只有当调用 extract() 或 re() 方法的时候,才会得到真实的文本数组。这种方式非常好用,因为这样就可以将 xpath() 和 css() 操作串联起来了。比如,可以使用 css() 快速抽取正确的 HTML 元素。 请注意,在后台中 css() 实际上编译了一个 xpath() 表达式,不过我们输入的内容要比 XPath 自身更加简单。接下来,串联一个 xpath() 方法,只抽取其中的文本。 最后,还可以通过 re() 方法,串联上正则表达式,以抽取感兴趣的值。 实际上,这个表达式与原始表达式相比,并无好坏之差。请把它当作一个引起思考的说明性示例。在本书中,我们将尽可能保持事物简单,同时也会尽可能多地使用虽然有些老旧但仍然好用的 XPath。关键点是记住 xpath() 和 css() 返回的 Selector 对象是可以被串联起来的。为了获取真实值,可以使用 extract(),也可以使用 re()。在 Scrapy 的每个新版本当中,都会围绕这些类添加新的令人兴奋且高价值的功能。相关的 Scrapy 文档部分为 http://doc.scrapy.org/en/latest/topics/selectors.html 。该文档非常优秀,相信你可以从中找到抽取数据的最有效的方式。 |
描述文本的抽取也是相似的。有一个 itemprop="description" 的属性用于标示描述。其 XPath 表达式为 //*[@itemprop="description"][1]/text()。相似地,住址部分使用 itemtype="http://schema.org/Place" 注解;因此,XPath 表达式为 //*[@itemtype="http://schema.org/Place"][1]/text()。
同理,图片使用了 itemprop="image"。因此使用 //img[@itemprop="image"][1]/@src。这里需要注意的是,我们没有使用 /text(),这是因为我们并不需要任何文本,而是只需要包含图片 URL 的 src 属性。
假设这些是我们想要抽取的全部信息,我们可以将其总结到表 3.1 中。
| 基本字段 | XPath表达式 |
|---|---|
title |
//*[@itemprop="name"][1]/text() 示例值: [u’set unique family well'] |
price |
//*[@itemprop="price"][1]/text() 示例值(使用re()) : [u'334.39'] |
description |
//*[@itemprop="description"][1]/text() 示例值: [u’website court warehouse\r\npool…'] |
address |
//*[@itemtype="http://schema.org/Place"][1]/text() 示例值: [u’Angel, London'] |
image_urls |
//*[@itemprop="image"][1]/@src 示例值: [u'../images/i01.jpg'] |
现在,表3.1 就变得非常重要了,因为如果我们有许多包含相似信息的网站,则很可能需要创建很多类似的爬虫,此时只需改变前面的这些表达式。此外,如果想要抓取大量网站,也可以使用这样一张表格来拆分工作量。
到目前为止,我们主要在使用 HTML 和 XPath。接下来,我们将开始编写一些真正的 Python 代码。