Scrapy引擎——一种直观方式
并行系统看起来与管道系统很相似。在计算机科学中,我们使用队列符号来表示队列以及处理中的元素(见图10.1 左侧)。队列系统的基本法则是利特尔法则,该法则认为在稳定状态下,队列系统中的元素数量(N)等于系统吞吐量(T)乘以总排队/服务时间(S),即 N = T · S。 另外两种形式是:T = N / S 以及 S = N / T,在计算中同样有用。
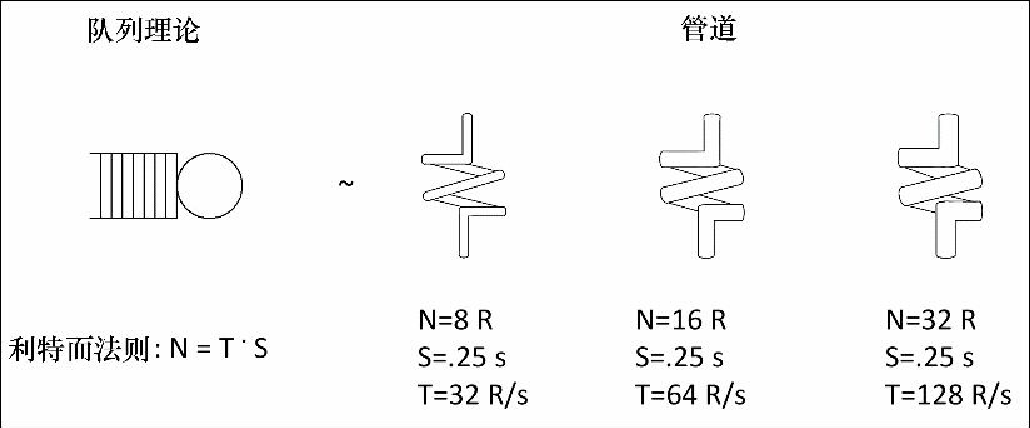
在管道的几何形状中也有相似的法则(见图10.1右侧)。管道容量(V)等于管道长度 L 乘以横截面面积(A),即 V = L·A。
如果我们想象长度表示服务时间(L~S),容量表示处理系统的元素数量(V~N),横截面面积表示吞吐量(A~N),那么利特尔法则和容量公式实际是相同的事情。
|
这个类比有道理吗?答案是差不多。如果我们将工作单位想象为小滴液体,以恒定速率在管道内部移动,那么 L~S 绝对有意义,因为管道越长,水滴移动花费的时间越多。V~N 同样有意义,因为管道越大,能够容纳的水滴越多。烦人的是,我们还可以通过施加更大压力的方式压入更多水滴。A~T 是不太满足类比的一点。在管道中,实际吞吐量,即每秒进出管道的水滴数量,被称为 “体积流量”,除非满足特定条件(孔口),否则其与 A2 成正比,而不是 A。这是因为更宽的管道不只意味着有更多的液体流出,还会使液体流动更快,因为管壁之间存在更大的空间。不过为了本章的学习,我们可以忽略这些技术细节,而是假设生活在一个理想的世界中,在这里压力和速度都是常量,并且吞吐量与横截面面积直接成正比。 |
利特尔法则和这个简单的体积公式非常相似,这就使得该 “管道模型” 非常直观有用。让我们更详细地看一下图10.1中的示例(右侧)。假设管道系统表示 Scrapy 的下载器。第一个非常 “细” 的下载器,其总体积/并发级别(N)可能是 8 个并发请求。管道长度/延迟(S)对于一个快速的网站来说,可能 S=250ms。在给定 N 和 S 时,现在可以计算处理元素的体积/吞吐量,每秒请求数为 T = N / S = 8 / 0.25 = 32。
你会发现延迟经常是我们无法控制的,因为它依赖于远端服务器的性能以及网络的延迟。我们比较容易控制的是下载器中并发(N)的级别,可以将其从 8 增长到 16 或 32 个并发请求,即10.1图中的第二个和第三个管道。对于常量的长度(超出我们控制范围之外),可以通过只增加横截面面积的方式增长体积,也就是说增加吞吐量!按照利特尔法则,16 个并发请求时,我们得到的每秒请求数为 T = N / S = 16 / 0.25 = 64 个,而在 32 个并发请求时,我们得到的每秒请求数是 T = N / S = 32 / 0.25 = 128 个。太好了!我们似乎可以通过增加并发的方式,使系统无限快。在急于得出这样的结论之前,还需要考虑队列系统级联的影响。
级联队列系统
当将不同横截面面积/吞吐量的几个管道依次连接起来时,可以很直观地理解整个系统的流量将由最窄的(最小吞吐量:T)管道所限制(见图10.2) 。
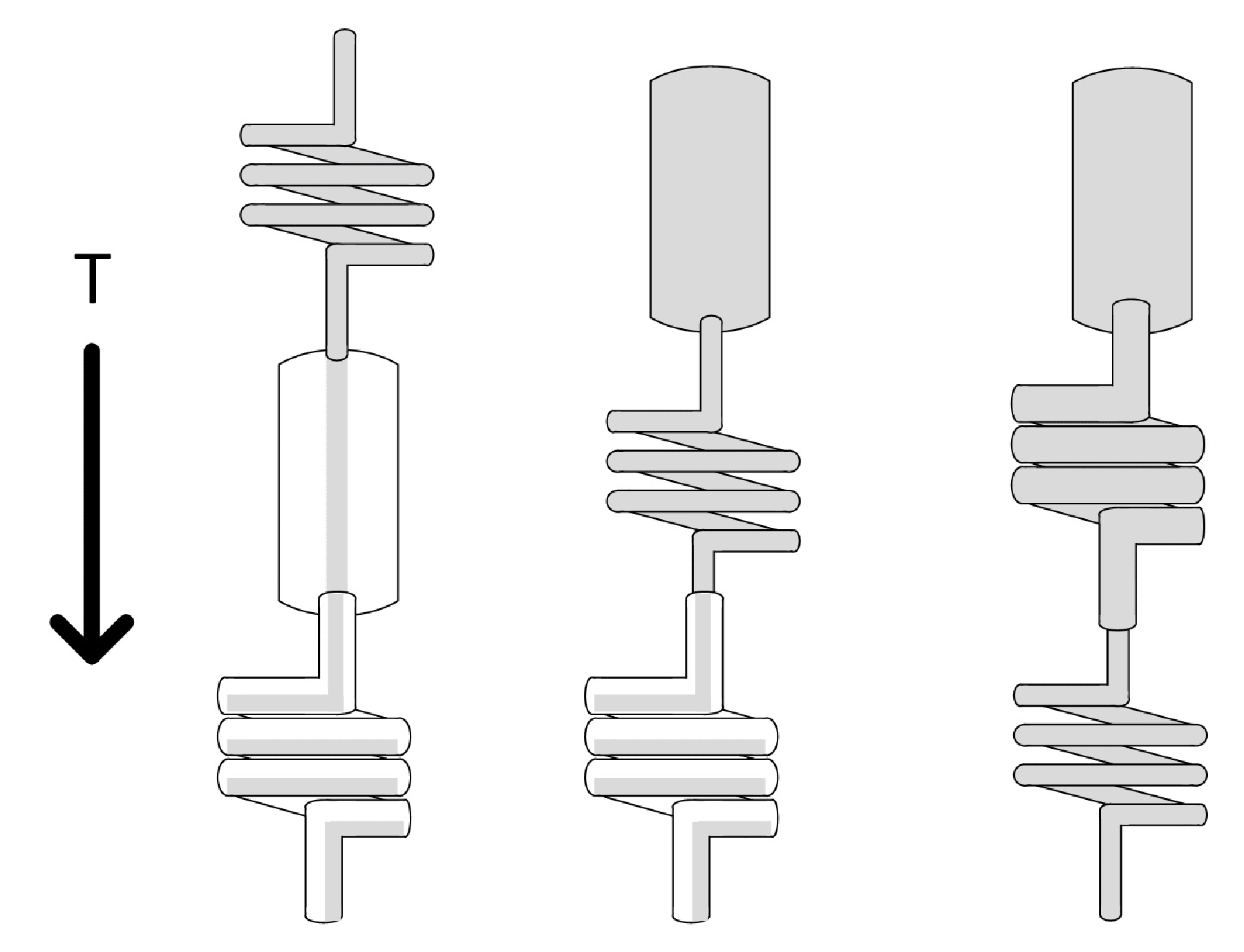
你还可以观察到最窄管道(即瓶颈) 的位置,决定了其他管道是如何 “填满” 的。如果考虑到与系统内存需求相关的填充,就会意识到瓶颈的位置是非常重要的。我们最好通过配置保持管道充满,且单个工作单元的花销最少。在 Scrapy 中,一个工作单元(爬取一个页面)主要是由下载器前的 URL(几个字节)以及下载后的 URL 加上服务器响应(较大)组成。
|
这就是为什么在 Scrapy 系统中,通常将瓶颈放置在下载器中。 |
定义瓶颈
使用管道系统作为类比的一个非常重要的好处是,它在定义瓶颈的过程中更加直观。如果观察图 10.2 就会发现,“瓶颈” 前的所有地方都是满的,而之后的所有地方都不是。
好消息是,在大多数系统中,可以相对容易地使用系统度量监控队列系统是如何填满的。通过仔细检查 Scrapy 的队列,我们可以了解瓶颈在什么地方,如果发现不在下载器中,则可以调整设置让其变为下载器。没有改善瓶颈的任何改进都不会带来吞吐量的收益。如果修改系统其他部分,只会让事情变得更糟,很有可能将瓶颈转移到别的地方。这个感觉有点像追尾,可能需要很长时间,并且会令你感到绝望。你必须遵循系统方法,定义瓶颈,并且需要在修改任何代码或配置之前,“知道锤子应该击中哪里”。你在大部分例子中(包括本书的大多数例子) 可以看到,瓶颈不是总在人们期望的地方出现。
Scrapy性能模型
让我们回到 Scrapy,详细看一下其性能模型(见图10.3) 。
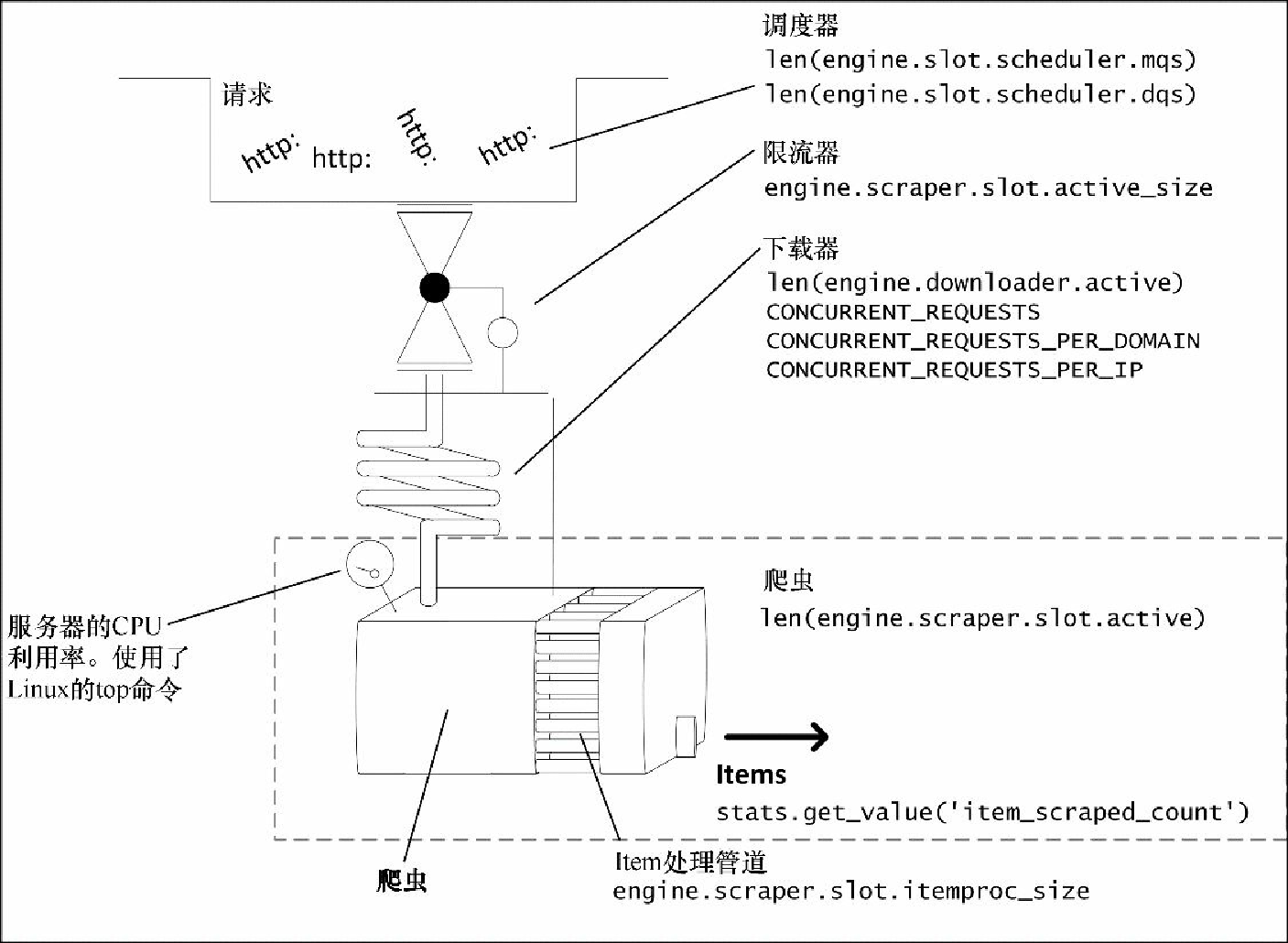
Scrapy 包含如下组成部分。
-
调度器:在这里,多个请求会排队等待下载器处理。它们主要由 URL 组成,因此会十分紧凑,这就意味着即使拥有大量 URL 也不会对系统有很大伤害,并且可以让我们在传入不规则请求流的情况下能够充分利用下载器。
-
限流器:这是抓取过程(大储水池)反馈的安全阀,如果正在执行的响应的总计大小超过 5MB,那么它会让前往下载器的后续请求停止。这可能会导致不可预料的性能起伏。
-
下载器:这是 Scrapy 关于性能最重要的组成部分。它对能够并行执行的请求的数量有着复杂的限制。其延迟(管道长度)等于远程服务器响应的时间,加上所有网络/操作系统以及 Python/Twisted 的延迟。我们可以调整并行请求的数量,不过通常情况下,我们几乎无法控制延迟。下载器的容量由 CONCURRENT_REQUESTS* 设置限制,我们将会很快看到。
-
爬虫:这是抓取过程中将响应转为 Item 和后续请求的部分。同时这也是我们编写的部分,通常情况下,只要遵照规则,它们就不会是性能瓶颈。
-
Item 管道:这是我们编写的代码的第二个部分。我们的爬虫可以对每个请求生成上百个 Item,同一时刻只会处理 CONCURRENT_ITEMS 个。该值十分重要,因为假设你在管道中要处理数据库访问,那么使用默认值(100)就可能会过高,从而在无意间拖垮数据库。
爬虫和管道都应该使用异步代码,并且在必要时引发更多的延迟,但不应因此成为瓶颈。极少情况下,我们的爬虫/管道会处理非常繁重的事情。如果发生此种情况,那么服务器的 CPU 可能会成为瓶颈。