进阶设置
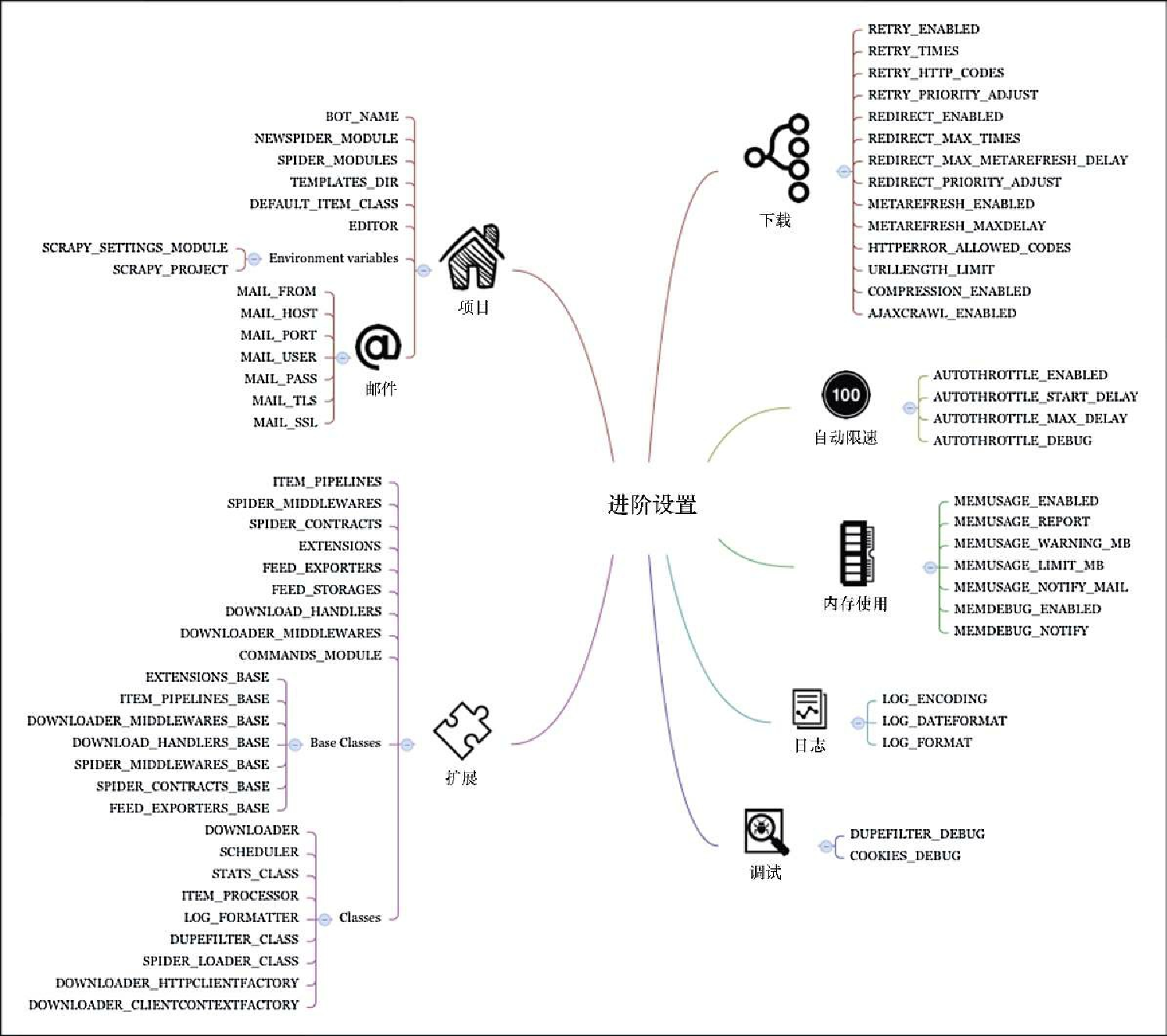
现在,我们要探讨一些 Scrapy 中不太常见的方面,以及 Scrapy 扩展的相关设置,后续章节中会详细介绍这些内容。这些进阶设置如图7.2 所示。
项目相关设置
在这里可以找到一些与具体项目相关的管理设置,如 BOT_NAME、SPIDER_MODULES 等。你可以快速浏览一下这些设置的文档,因为它们会提升具体用例的生产效率,不过通常情况下, Scrapy 的 startproject 和 genspider 命令都已经提供了合理的默认值,即使不 显式修改它们,也能很好地运行。邮件相关的设置,比如 MAIL_FROM,可以让你配置 MailSender 类,该类目前用于统计邮件信息(另外参见 STATSMAILER_RCPTS)以及内存使用信息(另外参见 MEMUSAGE_NOTIFY_MAIL)。还有两个环境变量: SCRAPY_SETTINGS_MODULE 以及 SCRAPY_PROJECT,可以让你调整 Scrapy 项目与其他项目集成的方式,比如 Django 项目。scrapy.cfg 还允许你调整设置模块的名称。
Scrapy扩展设置
这些设置能够让你扩展并修改 Scrapy 的几乎所有方面。这些设置中最重要的当属 ITEM_PIPELINES。它可以让你在项目中使用 Item 处理管道。第 9 章会看到更多的例子。除了管道之外,还可以通过不同的方式扩展 Scrapy,其中一些将会在第 8 章中进行总结。COMMANDS_MODULE 允许我们添加常用命令。比如,可以在 properties/hi.py 文件中添加如下内容。
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
default_settings = {'LOG_ENABLED': False}
def run(self, args, opts):
print("hello")当在 settings.py 文件中添加 COMMANDS_MODULE='properties.hi' 时,就激活了这个小命令,我们可以在 Scrapy 帮助中看到它,并且通过 scrapy hi 运行。在命令的 default_settings 中定义的设置,会被合并到项目的设置当中,并覆盖默认值,不过其优先级低于 settings.py 文件或命令行中设定的设置。
Scrapy 使用-_BASE字典(比如 FEED_EXPORTERS_BASE)存储不同框架扩展的默认值,并允许我们在 settings.py 文件或命令行中,通过设置它们的非-_BASE版本(比如 FEED_EXPORTERS)进行自定义。
最后,Scrapy 使用 DOWNLOADER、SCHEDULER 等设置,保存系统基本组件的包/类名。我们可以继承默认的下载器(scrapy.core.downloader.Downloader),重载一些方法,然后将 DOWNLOADER 设置为自定义的类。这样可以让开发者大胆地对新特性进行实验,并且可以简化自动化测试过程,不过除非你明确了解自己做的事情,否则不要轻易修改这些设置。
下载调优
RETRY_*、REDIRECT_* 以及 METAREFRESH_* 设置分别用于配置重试、重定向以及元刷新中间件。例如,将 REDIRECT_PRIORITY_ADJUST 设为 2,意味着每次发生重定向时,新请求将会在所有非重定向请求完成服务后才会被调度;而将 REDIRECT_MAX_TIMES 设置为 20,则表示在执行 20 次重定向后,下载器将会放弃尝试,并返回目前所见到的内容。这些设置在爬取一些运行不太正常的网站时非常有用,不过在大多数情况下,默认值已经可以提供很好的服务了。它同样也适用于 HTTPERROR_ALLOWED_CODES 以及 URLLENGTH_LIMIT。
自动限制扩展设置
AUTOTHROTTLE_* 设置用于启用并配置自动限速扩展。虽然对它有很大期望,但从实践来看,我发现它往往有些保守,不容易调整。它使用下载延迟,来了解我们和目标服务器的负载情况,并据此调整下载器的延迟。如果你很难找到 DOWNLOAD_DELAY 的最佳值(默认为 0),就会发现该模块很有用。
内存使用扩展设置
MEMUSAGE_* 设置用于启用并配置内存使用扩展。当超出内存限制时,将会关闭爬虫。当运行在共享环境时,该设置非常有用,因为此时需要非常礼貌的行为。大多数情况下,你可能会发现它只有在接收报警邮件时才会有用,此时我们需要将 MEMUSAGE_LIMIT_MB 设置为 0,禁用关闭爬虫的功能。该扩展只在类 UNIX 平台上适用。
MEMDEBUG_ENABLED 和 MEMDEBUG_NOTIFY 用于启用并配置内存调试扩展,在爬虫关闭时打印出仍然存活的引用数量。总之,追踪内存泄露不是一件简单而有趣的事情(好吧,它还是有一些乐趣的)。我们可以阅读 Debugging memory leaks with trackref 这篇优秀的文档,了解更多内存泄露排查的方法,不过最重要的建议是,保持你的爬虫相对简短、批 量处理,并且需要根据服务器的能力运行。我认为没有什么好的理由可以让我们批量运行超过几千页或几分钟。