可读流的使用
流的读取模式与状态
可读流的读取模式
可读流有两种读取模式,即流动(flowing)模式和暂停(paused)模式。
所有的可读流都是以暂停模式开始,当流处于暂停模式时,可以通过 read() 方法从流中按需读取数据。
流动模式指的是一旦开始读取文件,会按照 highWaterMark 的值按次读取,直到读取完为止。当流处于流动模式时,因为数据是持续变化的,所以需要使用监听事件来处理它。
流的暂停模式和流动模式是可以互相切换的,如通过添加 data 事件、使用 resume() 方法或者 pipe() 方法等都可以将可读流从暂停模式切换为流动模式;使用 paused() 方法或者 unpipe() 方法可以将可读流从流动模式切换为暂停模式。
可读流的状态
在实际使用可读流时,它一共有 3 种状态,即初始状态(null)、流动状态(true)和非流动状态(false)。
当流处于初始状态(null)时,由于没有数据使用者,所以流不会产生数据,这时如果监听 data 事件、调用 pipe() 方法或 resume() 方法,都会将当前状态切换为流动状态(true),这样可读流即可开始主动地产生数据并触发事件。
如果调用 pause() 方法或者 unpipe() 方法,就会将可读流的状态切换为非流动状态(false),这将暂停流,但不会暂停数据生成。此时,如果再为 data 事件设置监听器,就不会再将状态切换为流动状态(true)了。
可读流的创建
Node.js 中的可读流使用 stream 模块中的 Readable 类表示,因此可以直接使用下面代码创建:
const readable = new stream.Readable();另外,还可以使用 fs 模块的 createReadStream 方法创建可读流,语法格式如下:
fs.createReadStream(path[, options])-
path:读取文件的文件路径,可以是字符串、缓冲区或网址。 -
options:读取文件时的可选参数,可选值如下。-
flags:指定文件系统的权限,默认为r。 -
encoding:编码方式,默认为null。 -
fd:文件描述符,默认为null。 -
mode:设置文件模式,默认为0o666。 -
autoClose:文件出错或者结束时,是否自动关闭文件,默认为true。 -
emitClose:流销毁时,是否发送close事件,默认为true。 -
start:指定开始读取的位置。 -
end:指定结束读取的位置。 -
highWaterMark:可读取的阈值,一般设置在16~100KB范围内。
-
例如,下面代码创建一个可读流:
const fs = require("fs");
const read = fs.createReadStream("凉州词.txt");可读流的属性方法及事件
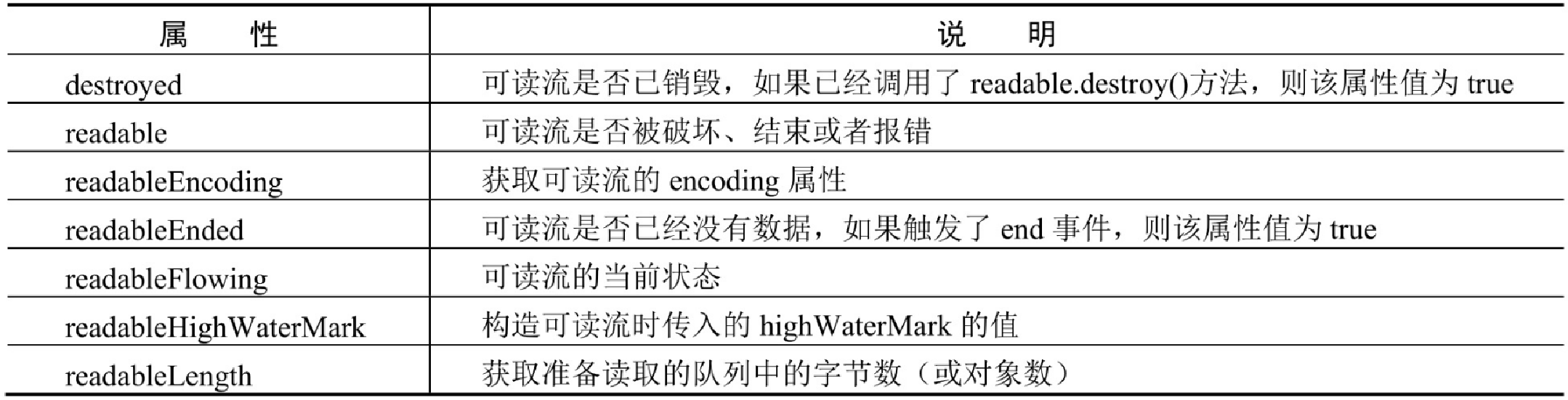
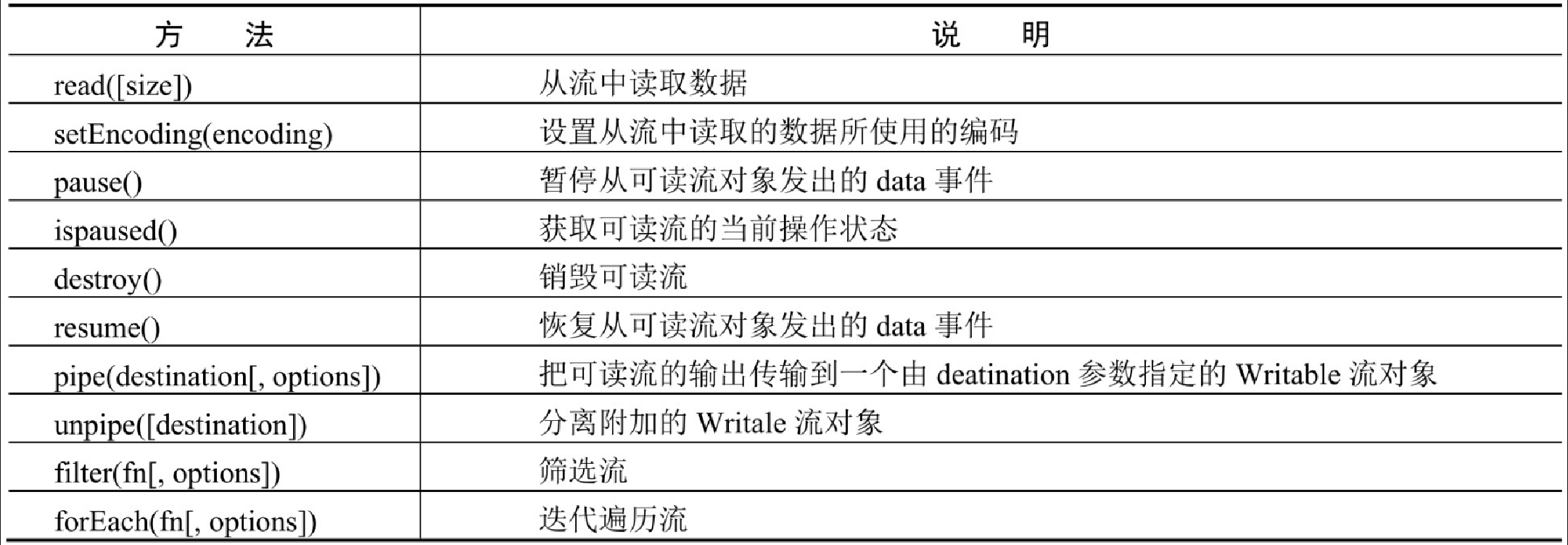
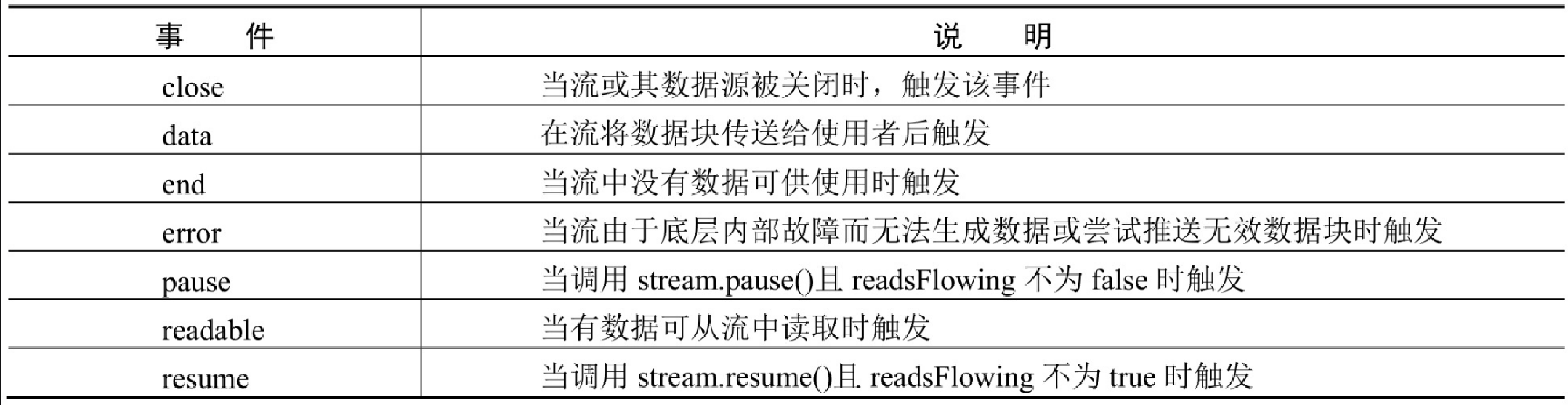
可读流提供了很多属性、方法和事件,用来获取可读流信息、对可读流进行操作,以及监听可读流的相应操作,它们的说明分别如表10.1、表10.2和表10.3所示。
|
触发流事件同样采用第 5 章中讲解过的 |
可读流的常见操作
读取数据
使用 read() 方法可以从流中读取数据,其语法格式如下:
对象名.read([size])-
size:要读取的数据的字节数。 -
返回值:返回值可能为字符串、
Buffer、null等。
例如,创建一个可读流,读取文件 “凉州词.txt” 中的内容,代码如下:
const fs = require("fs");
const read = fs.createReadStream("凉州词.txt");
read.on('readable', function () {
while (null !== (chunk = read.read(25))) {
console.log(chunk.toString());
}
});设置编码格式
可读流读取数据时,默认情况下没有设置字符编码,流数据返回的是 Buffer 对象。如果设置了字符编码,则流数据返回指定编码的字符串。设置可读流中数据的编码格式需要使用 setEncoding() 方法,其语法格式如下:
对象名.setEncoding(encoding)参数 encoding 用来设置编码格式。
下面使用 utf8 编码方式读取 “凉州词.txt” 文件中的内容,代码如下:
const fs = require("fs");
const read = fs.createReadStream("凉州词.txt");
read.setEncoding("utf8") //设置编码格式
read.on('readable', function () {
console.log(read.read()); //设置编码格式后,此处不再需要使用toString()方法
});暂停与恢复流
pause() 方法可以使流动模式的可读流停止触发 data 事件,并切换为非流动模式,其语法格式如下:
对象名.pause()resume() 方法可以恢复从可读流对象发出的 data 事件,将可读流切换为流动模式,其语法格式如下:
对象名.resume()【例10.1】按行输出古诗内容。(实例位置:资源包\源码\10\01)
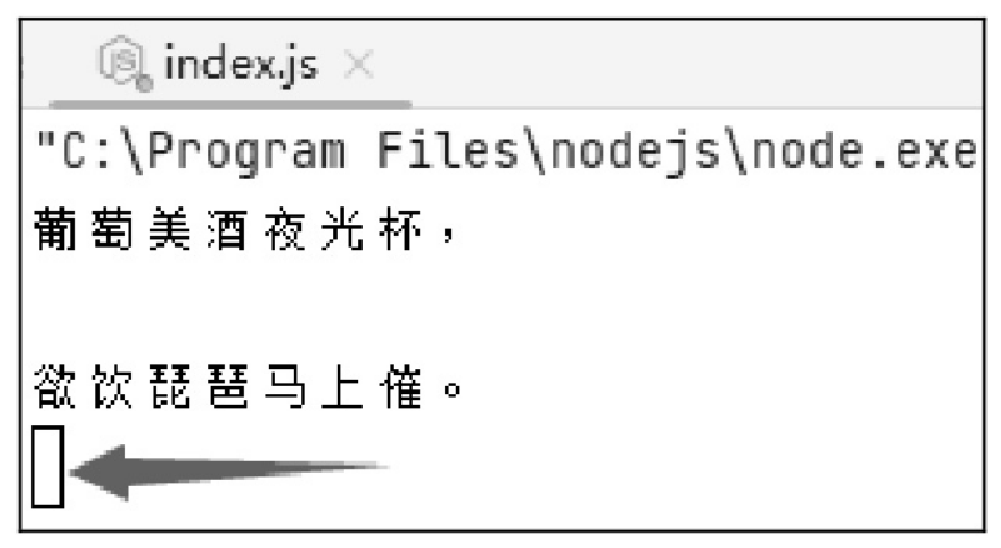
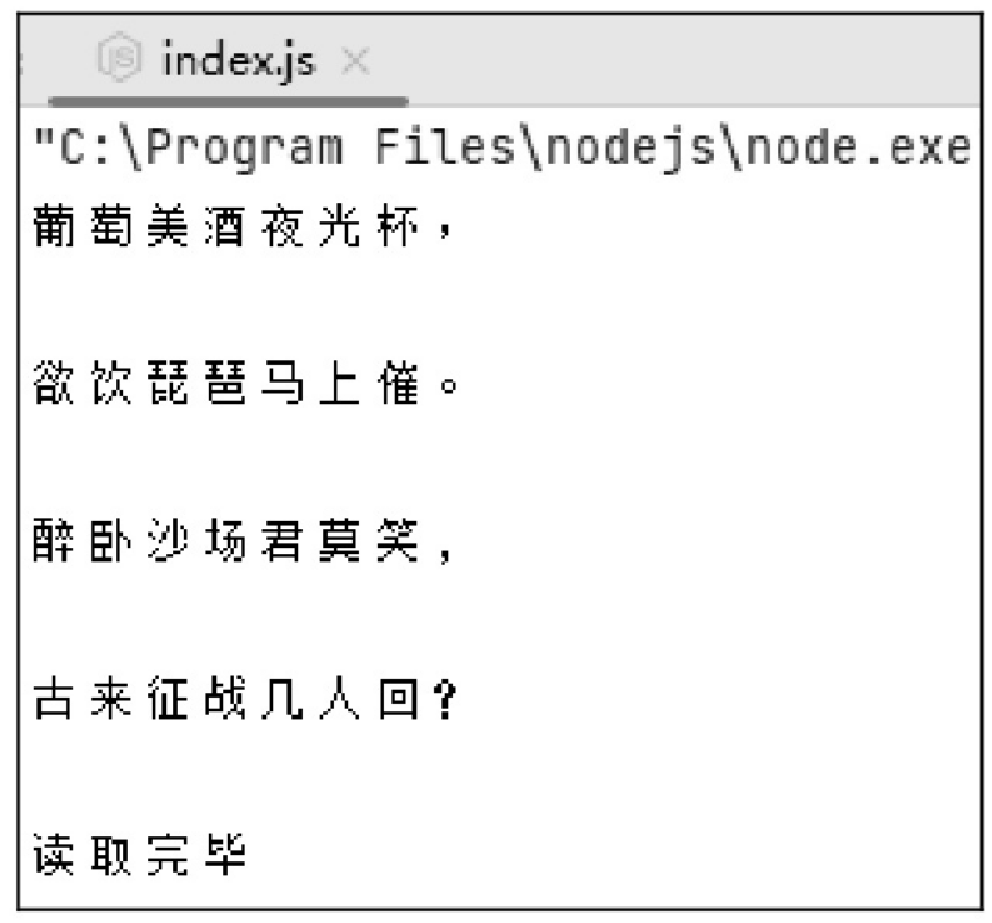
创建一个 .js 文件,使用可读流读取文件 “凉州词.txt” 的内容并显示,读取时,设置每隔一秒读取一行内容,这里使用可读流的 pause() 方法在读取每行数据后暂停,然后每隔 1 秒后,再使用 resume() 方法恢复流数据的读取。代码如下:
const fs = require('fs');
const read= fs.createReadStream("凉州词.txt", {highWaterMark: 25});
read.setEncoding("utf8") //设置编码格式
read.on('data', function (chunk) {
console.log(chunk.toString());
read.pause();
setTimeout(function () {
read.resume();
}, 1000);
});
read.on("close",function(){
console.log("读取完毕");
})运行程序,每隔一行会显示一行内容,效果如图10.1和图10.2所示。
获取流的运行状态
对可读流进行操作时,可以使用 ispaused() 方法判断流当前的操作状态,该方法不需要参数,返回结果为 true 或 false,其语法格式如下:
对象名.ispaused()示例代码如下:
const readable = new stream.Readable();
console.log(readable.ispaused());
readable.pause()
console.log(readable.ispaused());上面代码的运行结果如下:
false
true|
|
销毁流
使用 destroy() 方法可以销毁可读流,其语法格式如下:
对象名.destroy([error])该方法中有一个可选参数 error,用于在处理错误事件时发出错误。
例如,创建一个可读流对象,使用该对象读取文件内容后,使用 destroy() 销毁该对象,代码如下:
const fs = require("fs")
var read = fs.createReadStream('凉州词.txt')
read.setEncoding("utf8")
read.on('data', function (chunk) {
console.log("读取到的数据:\n" + chunk.toString());
})
read.destroy()上面代码运行结果为空,因为最后一行代码销毁了可读流 read,可读流在销毁后,会将读取的数据清空,因此,通常在程序可能出现异常时,才会在处理异常的过程中使用销毁流方法。
绑定可写流至可读流
readable.pipe() 方法可以将可写流绑定到可读流,并将可读流自动切换到流动模式,同时将可读流的所有数据推送到绑定的可写流。pipe() 方法的语法格式如下:
可读流对象名.pipe(destination[, options])-
destination:要绑定到可读流的可写流对象。 -
options:保存管道选项,通常为end参数,其参数值为true,表示如果可读流触发end事件,可写流也调用steam.end()结束写入,如果设置end值为false,则目标流就会保持打开。 -
返回值:返回目标可写流。
|
|
【例10.2】通过将可写流绑定至可读流为文件追加内容。(实例位置:资源包\源码\10\02)
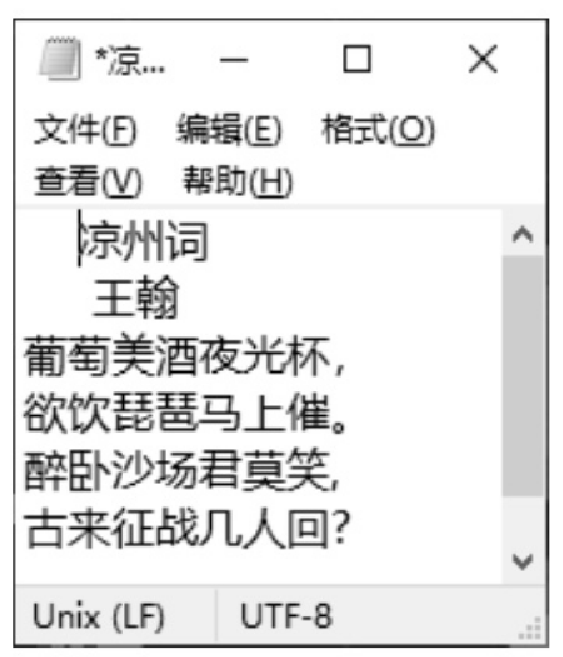
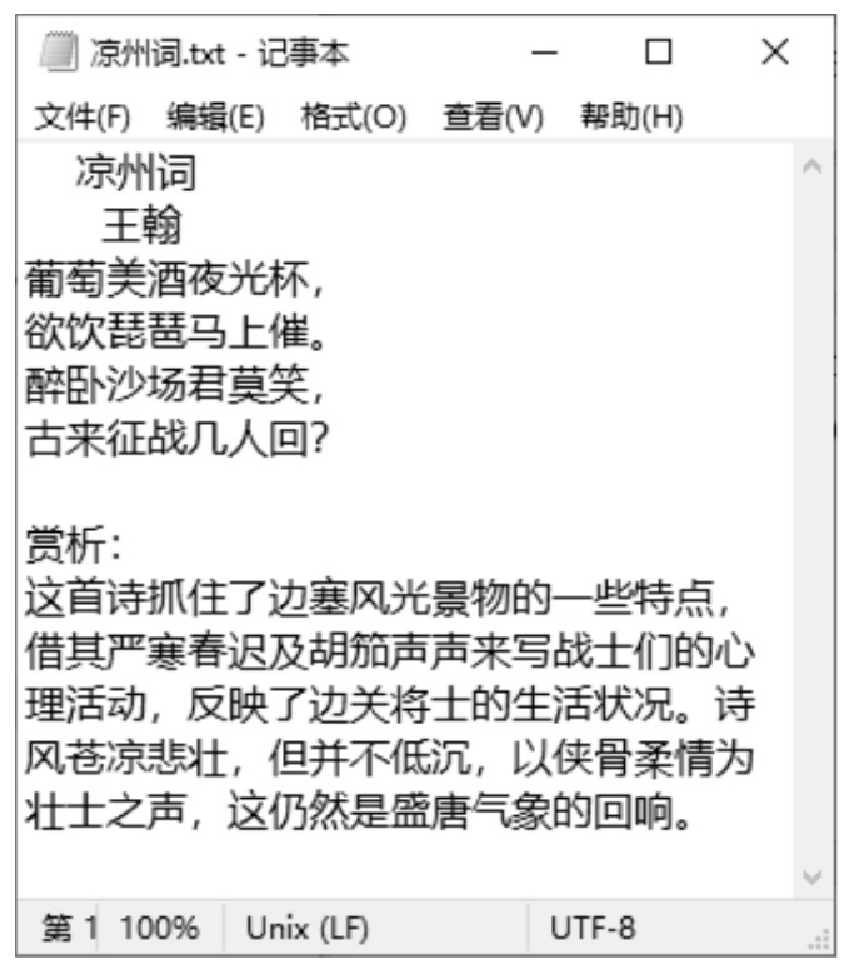
创建一个可读流 read,从中读取文本文件 demo.txt 的内容,文件中的内容为《凉州词》古诗赏析;然后创建一个可写流 write,其操作的 “凉州词.txt” 文件内容为《凉州词》古诗内容,使用可读流的 pipe() 方法将可写流 write 绑定到可读流 read,代码如下:
var fs = require("fs");
var read = fs.createReadStream('demo.txt'); //创建可读流
var write = fs.createWriteStream('凉州词.txt', {flags: "a"}); //创建可写流
read.pipe(write); //将可写流绑定到可读流
console.log("已完成")“凉州词.txt” 文件原内容如图10.3所示,运行上面代码后,再次打开 “凉州词.txt” 文件,内容如图10.4所示。
解绑可写流
上文讲解了使用可读流的 pipe() 方法可以将可写流绑定到可读流,还可以通过可读流的 unpipe() 方法将已经绑定的可写流进行解绑,其语法格式如下:
可读流对象名.unpipe([destination])该方法中有一个可选参数 destination,表示要解绑的可写流,如果该参数省略,表示解绑所有的可写流。
例如,代码如下:
var fs = require("fs");
var read = fs.createReadStream('demo.txt'); //创建可读流
var write = fs.createWriteStream('凉州词.txt', {flags: "a"}); //创建可写流
read.pipe(write); //将可写流绑定到可读流
console.log("已绑定可写流")
read.unpipe(write) //解绑
console.log("已解绑可写流")上面代码先为可读流 read 绑定一个可写流 write,这时 demo.txt 文件中的内容都被追加到 “凉州词.txt” 文件中,然后将 write 解绑,于是从 “凉州词.txt” 文件中移除 demo.txt 中的内容,最终 “凉州词.txt” 文件中的内容将不会发生变化。
|
由于解绑可写流操作会将已经绑定至可读流的可写流清除,因此,为了保持数据的一致性,通常在写入或者追加操作出现异常情况时,使用 |