Hadoop 部署
由于部署 Hadoop 需要 Master 访问所有 Salve 主机实现无密码登录,即配置账号公钥认证,具体参考 9.2.5 节关于配置 Linux 主机 SSH 无密码访问的介绍,本节将不再陈述。
(1) 安装
SSH 登录 Master 主机,这里使用 root 账号进行相关演示。安装 JDK 环境:
# mkdir -p /usr/java/ && cd /usr/java
# wget http://uni-smr.ac.ru/archive/dev/java/SDKs/sun/j2se/6/jdk-6u45-
linux-x64.bin
# chmod +x jdk-6u45-linux-x64.bin
# ./jdk-6u45-linux-x64.bin
# vi /etc/profile (配置Java环境变量,追加以下内容)
export JAVA_HOME=/usr/java/jdk1.6.0_45
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
# cd /etc (使环境变量生效)
# . profile安装 Hadoop,版本为 1.2.1,安装路径为 /usr/local。
# cd /usr/local
# wget http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
# tar -zxvf hadoop-1.2.1.tar.gz
# cd /usr/local/hadoop-1.2.1/conf修改目录(/usr/local/hadoop-1.2.1/conf)中的四个 Hadoop 核心配置文件 hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml,具体内容如下:
-
hadoop-env.sh,Hadoop 环境变量配置文件,指定 JAVA_HOME。
export JAVA_HOME=/usr/java/jdk1.6.0_45 -
core-site.xml,Hadoop core 的配置项,主要针对 Common 组件的属性配置。由于默认的 hadoop.tmp.dir 的路径为 /tmp/hadoop-${user.name},笔者的 Linux 系统的 /tmp 文件系统的类型是 Hadoop 不支持的,会报 “File /tmp/<user>/input/conf/slaves could only be replicated to 0 nodes, instead of 1” 异常,因此手工修改 hadoop.tmp.dir 指向 /data/tmp/hadoop-${user.name},作为 Hadoop 用户的临时存储目录,配置如下:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/data/tmp/hadoop-${user.name}</value> </property> <property> <name>fs.default.name</name> <value>hdfs://192.168.1.20:9000</value> //master主机IP:9000端口 </property> </configuration> -
hdfs-site.xml,Hadoop 的 HDFS 组件的配置项,包括 Namenode、Secondarynamenode 和 Datanode 等,配置如下:
<configuration> <property> <name>dfs.name.dir</name> <value>/data/hdfs/name</value> //Namenode持久存储名字空间、事务日志路径 </property> <property> <name>dfs.data.dir</name> <value>/data/hdfs/data</value> //Datanode数据存储路径 </property> <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> //Datanode所允许同时执行的发送和接受任务数量,默认为256 </property> <property> <name>dfs.replication</name> <value>2</value> //数据备份的个数,默认为3 </property> </configuration> -
mapred-site.xml,配置 map-reduce 组件的属性,包括 jobtracker 和 tasktracker,配置如下:
<configuration> <property> <name>mapred.job.tracker</name> <value>192.168.1.20:9001</value> </property> </configuration> -
masters,配置 Secondarynamenode 项,环境使用主设备 192.168.1.20 同时承担 Secondarynamenode 的角色,生产环境要求使用独立服务器,起到 HDFS 文件系统元数据(metadata)信息的备份作用,当 NameNode 发生故障后可以快速还原数据,配置内容如下:
192.168.1.20 -
slaves,配置所有 Slave 主机信息,填写 IP 地址即可。本示例中 Slave 的信息如下:
192.168.1.21 192.168.1.22
接下来,从主节点(Master)复制 jdk 及 Hadoop 环境到所有 Slave,目标路径要与 Master 保持一致,切记!执行以下命令进行复制:
# ssh root@192.168.1.21 '[ -d /usr/java ] || mkdir -p /usr/java ]'
# ssh root@192.168.1.22 '[ -d /usr/java ] || mkdir -p /usr/java ]'
# scp -r /usr/java/jdk1.6.0_45 root@192.168.1.21:/usr/java
# scp -r /usr/java/jdk1.6.0_45 root@192.168.1.22:/usr/java
# scp -r /usr/local/hadoop-1.2.1 root@192.168.1.21:/usr/local
# scp -r /usr/local/hadoop-1.2.1 root@192.168.1.22:/usr/localHadoop 部分功能是通过主机名来寻址的,因此需要配置主机名 hosts 信息(生产环境建议直接搭建内网 DNS 服务),保证 Hadooop 环境所有主机的 /etc/hosts 文件配置如下:
192.168.1.20 SN2013-08-020
192.168.1.21 SN2013-08-021
192.168.1.22 SN2013-08-022管理员通过浏览器查看 datanode 信息,需要配置本地 hosts,如 Windows 7 系统 hosts 文件路径为 C:\Windows\System32\drivers\etc,添加所有 datanode 主机信息,如下:
192.168.1.21 SN2013-08-021
192.168.1.22 SN2013-08-022如设备启用了 iptables 防火墙,需要对主节点(Master)及 Slave 主机添加以下规则:
Master:
iptables -I INPUT -s 192.168.1.0/24-p tcp --dport 50030-j ACCEPT
iptables -I INPUT -s 192.168.1.0/24-p tcp --dport 50070-j ACCEPT
iptables -I INPUT -s 192.168.1.0/24-p tcp --dport 9000-j ACCEPT
iptables -I INPUT -s 192.168.1.0/24-p tcp --dport 9001-j ACCEPT
Slaves:
iptables -I INPUT -s 192.168.1.0/24-p tcp --dport 50075-j ACCEPT
iptables -I INPUT -s 192.168.1.0/24-p tcp --dport 50060-j ACCEPT
iptables -I INPUT -s 192.168.1.20-p tcp --dport 50010-j ACCEPT配置完成后在主节点(Master)上格式化文件系统的 namenode,执行:
# cd /usr/local/hadoop-1.2.1
# bin/hadoop namenode -format最后,在主节点(Master)上执行启动命令,如下:
# bin/start-all.sh(2) 检验安装结果
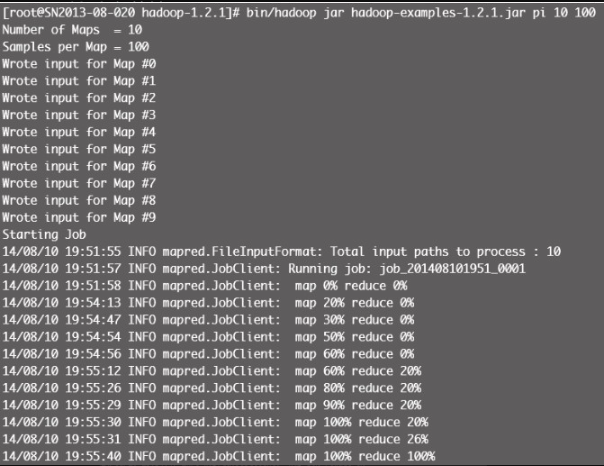
Hadoop 官方提供的一个测试 MapReduce 的示例,执行:
# bin/hadoop jar hadoop-examples-1.2.1.jar pi 10100如果返回如图12-1所示结果,则说明配置成功。
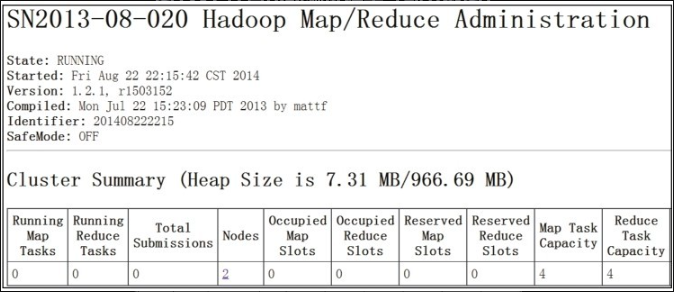
访问 Hadoop 提供的管理页面,Map/Reduce 管理地址: http://192.168.1.20:50030/ ,如图12-2所示。
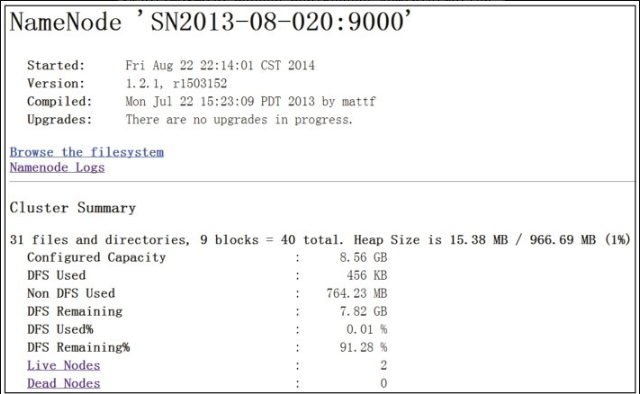
HDFS 存储管理地址: http://192.168.1.20:50070/ ,如图12-3所示。