使用 Python 编写 MapReduce
Map 与 Reduce 为两个独立函数,为了加快各节点的处理速度,使用并行的计算方式,map 运算的结果再由 reduce 继续进行合并。例如,要统计图书馆有多少本书籍,首先一人一排进行统计(map),其次将每个人的统计结果进行汇总(reduce),最终得出总数。Hadoop 除了提供原生态的Java来编写 MapReduce 任务,还提供了其他语言操作的 API—Hadoop Streaming,它通过使用标准的输入与输出来实现 map 与 reduce 之前传递数据,映射到 Python 中便是 sys.stdin 输入数据、sys.stdout 输出数据。其他业务逻辑也直接在 Python 中编写。
下面实现一个统计文本文件(/home/test/hadoop/input.txt)中所有单词出现的词频功能,分别使用原生 Python 与框架方式来编写 mapreduce。文本文件内容如下:
foo foo quux labs foo bar quux abc bar see you by test welcome test
abc labs foo me python hadoop ab ac bc bec python用原生Python编写MapReduce详解
(1) 编写 Map 代码
见下面的 mapper.py 代码,它会从标准输入(stdin)读取数据,默认以空格分割单词,然后按行输出单词及其词频到标准输出(stdout),不过整个 Map 处理过程并不会统计每个单词出现的总次数,而是直接输出 “word 1”,以便作为 Reduce 的输入进行统计,要求 mapper.py 具备可执行权限,执行 chmod +x /home/test/hadoop/mapper.py 。
#!/usr/bin/env python
import sys
#输入为标准输入stdin;
for line in sys.stdin:
#删除开头和结尾的空格;
line = line.strip()
#以默认空格分隔行单词到words列表;
words = line.split()
for word in words:
#输出所有单词,格式为“单词,1”以便作为Reduce的输入;
print '%s\t%s' % (word, 1)(2) 编写 Reduce 代码
见下面的 reducer.py 代码,它会从标准输入(stdin)读取 mapper.py 的结果,然后统计每个单词出现的总次数并输出到标准输出(stdout),要求 reducer.py 同样具备可执行权限,执行 chmod +x /home/test/hadoop/reducer.py 。
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# 获取标准输入,即mapper.py的输出;
for line in sys.stdin:
#删除开头和结尾的空格;
line = line.strip()
# 解析mapper.py输出作为程序的输入,以tab作为分隔符;
word, count = line.split('\t', 1)
# 转换count从字符型成整型;
try:
count = int(count)
except ValueError:
# count非数字时,忽略此行;
continue
# 要求mapper.py的输出做排序(sort)操作,以便对连续的word做判断;
if current_word == word:
current_count += count
else:
if current_word:
# 输出当前word统计结果到标准输出
print('%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
# 输出最后一个word统计
if current_word == word:
print('%s\t%s' % (current_word, current_count))(3) 测试代码
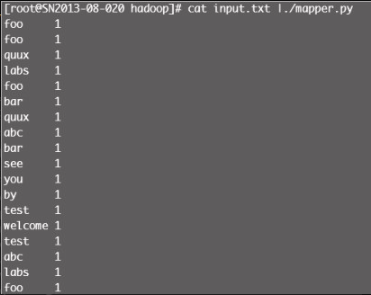
我们可以在 Hadoop 平台运行之前在本地进行测试,校验 mapper.py 与 reducer.py 运行的结果是否正确,测试结果如图12-4所示。
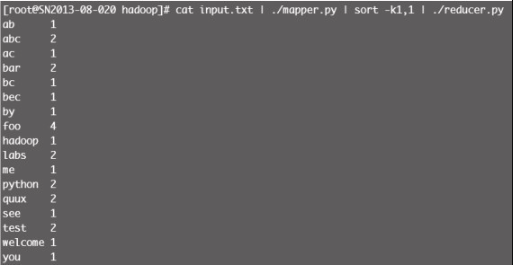
测试 reducer.py 时需要对 mapper.py 的输出做排序(sort)操作,当然, Hadoop 环境会自动实现排序,如图12-5所示。
(4) 在 Hadoop 平台运行代码
首先在 HDFS 上创建文本文件存储目录,本示例中为 /user/root/word,运行命令:
# /usr/local/hadoop-1.2.1/bin/hadoop dfs -mkdir /user/root/word上传文件至 HDFS,本示例中为 /home/test/hadoop/input.txt,如果有多个文件,可采用以下方法进行操作,因为 Hadoop 分析目标默认针对目录,目录下的文件都在运算范围中。
# /usr/local/hadoop-1.2.1/bin/hadoop fs -put /home/test/hadoop/input.txt /user/
root/word/
# /usr/local/hadoop-1.2.1/bin/hadoop dfs -ls /user/root/word/
Found 1 items
-rw-r--r-- 2 root supergroup 1182014-02-10 09:49 /user/root/word/input.txt下一步便是关键的执行 MapReduce 任务了,输出结果文件指定 /output/word,执行以下命令:
# /usr/local/hadoop-1.2.1/bin/hadoop jar /usr/local/hadoop-1.2.1/contrib/ streaming/hadoop-streaming-1.2.1.jar -file ./mapper.py -mapper ./mapper.py -file
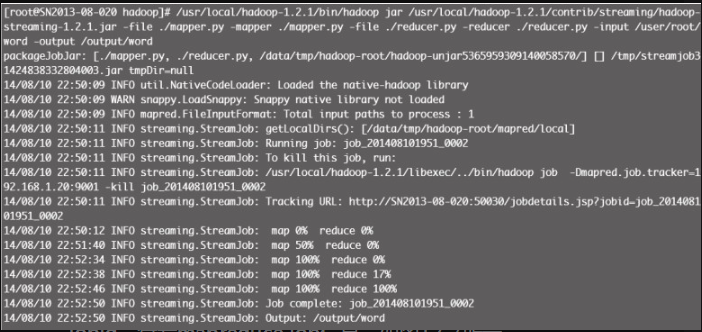
./reducer.py -reducer ./reducer.py -input /user/root/word -output /output/word图12-6为返回的执行结果,可以看到 map 及 reduce 计算的百分比进度。
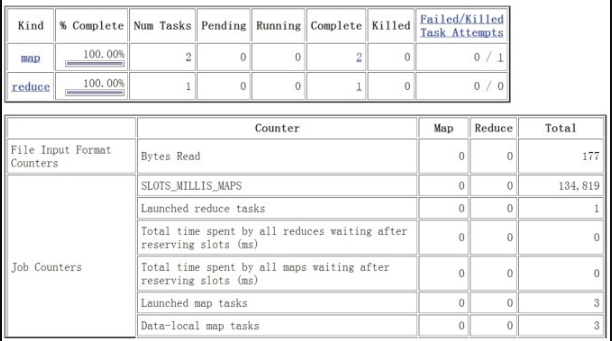
访问 http://192.168.1.20:50030/jobtracker.jsp ,点击生成的Jobid,查看 mapreduce job 信息,如图12-7所示。
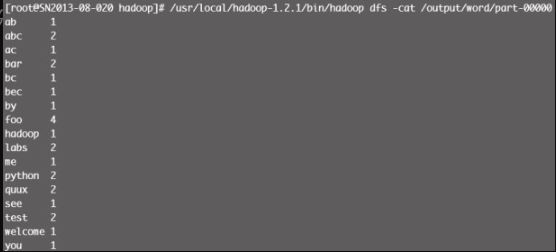
查看生成的分析结果文件清单,其中 /output/word/part-00000 为分析结果文件,如图12-8所示。

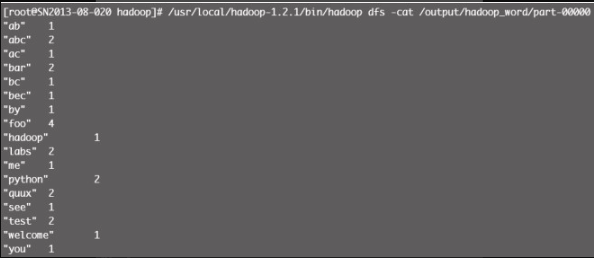
最后查看结果数据,图12-9显示了单词个数统计的结果,整个分析过程结束。
|
HDFS 常用操作命令有:
|
用Mrjob框架编写MapReduce详解
Mrjob( http://pythonhosted.org/mrjob/index.html )是一个编写 MapReduce 任务的开源 Python 框架,它实际上对 Hadoop Streaming 的命令行进行了封装,因此接触不到 Hadoop 的数据流命令行,使我们可以更轻松、快速编写 MapReduce 任务。Mrjob 具有如下特点。
-
代码简洁,map 及 reduce 函数通过一个 Python 文件就可以搞定;
-
支持多步骤的 MapReduce 任务工作流;
-
支持多种运行方式,包括内嵌方式、本地环境、Hadoop、远程亚马逊;
-
支持亚马逊网络数据分析服务 Elastic MapReduce (EMR);
-
调试方便,无须任何环境支持。
安装 Mrjob 要求环境为 Python 2.5 及以上版本,源码下载地址: https://github.com/yelp/mrjob 。
# pip install mrjob #PyPI安装方式
# python setup.py install #源码安装方式回到实现一个统计文本文件(/home/test/hadoop/input.txt)中所有单词出现的词频功能,Mrjob 通过 mapper() 与 reducer() 方法实现了 MR 操作,实现代码如下:
from mrjob.job import MRJob
class MRWordCounter(MRJob):
def mapper(self, key, line):
for word in line.split():
yield word, 1
def reducer(self, word, occurrences):
yield word, sum(occurrences)
if __name__ == '__main__':
MRWordCounter.run()可以看出代码行数只是原生 Python 的 1/3,逻辑也比较清晰,代码中包含了mapper、reducer 函数。mapper 函数接收每一行的输入数据,处理后返回一对 key:value,初始化 value 为数据 1;reducer 接收 mapper 输出的 key-value 对进行整合,把相同 key 的 value 作累加(sum)操作后输出。Mrjob 利用 Python 的 yield 机制将函数变成一个Generators(生成器),通过不断调用 next() 去实现 key-value 的初始化或运算操作。前面介绍 Mrjob 支持四种运行方式,包括内嵌(-r inline)、本地(-r local)、Hadoop(-r hadoop)、Amazon EMR(-r emr),下面主要介绍前三者的运行方式。
(1) 内嵌(-r inline)方式
特点是调试方便,启动单一进程模拟任务执行状态及结果,默认(-r inline)可以省略,输出文件使用 “> output-file” 或 “-o output-file”。下面两条命令是等价的:
# python word_count.py -r inline input.txt >output.txt
# python word_count.py input.txt -o output.txt输出文件 output.txt 内容见图12-10。
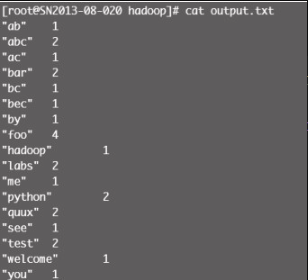
(2) 本地(-r local)方式
用于本地模拟 Hadoop 调试,与内嵌(inline)方式的区别是启动了多进程执行每一个任务,如:
# python word_count.py -r local input.txt >output.txt执行的结果与 inline 一样,只是运行过程存在差异。
(3) Hadoop(-r hadoop)方式
用于 Hadoop 环境,支持 Hadoop 运行调度控制参数,如:
-
指定 Hadoop 任务调度优先级(VERY_HIGH|HIGH),如,--jobconf mapreduce.job. priority=VERY_HIGH。
-
Map 及 Reduce 任务个数限制,如,--jobconf mapred.map.tasks=10—jobconf mapred.reduce.tasks=5。
注意,执行之前需要指定 Hadoop 环境变量,执行结果见图12-11。
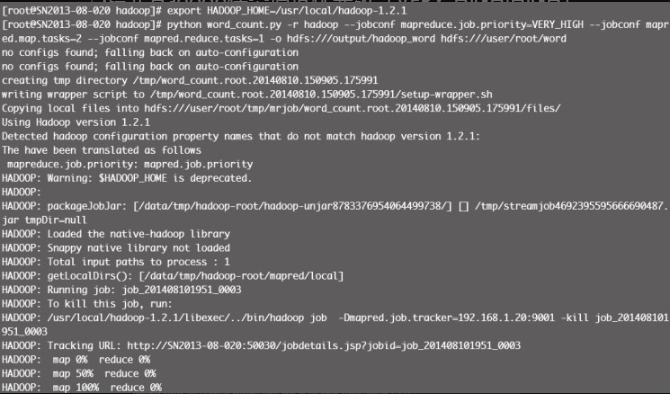
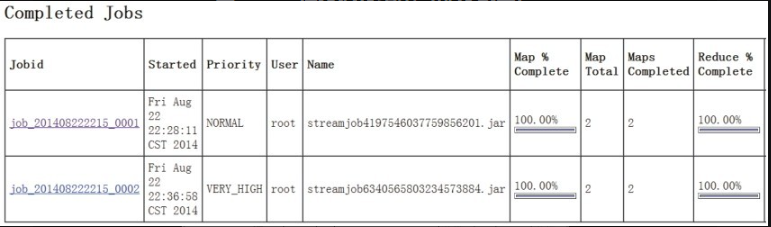
访问 http://192.168.1.20:50030/jobtracker.jsp ,显示的最后一行便是任务执行的信息,从中可以看到任务的优先级、map 及 reduce 的总数,如图12-12所示。
查看 Hadoop 分析结果文件,内容见图12-13。
Mrjob 框架的介绍告一段落,下一节重点以实际案例进行说明。