实战分析
在互联网企业中,随着业务量、访问量的不断增长,用户产生的数据也越来越大,如何处理大数据的存储与分析问题呢?比如 Web 服务器的访问 log,当日志只有 GB 单位大小时,我们还可以勉强通过 shell、awk 进行分析,当达到上百 GB,甚至上 PB 级别时,通过脚本的方式已经力不从心了。另外一个待解决的问题就是数据存储。Hadoop 很好地解决了这两个问题,即分布式存储与计算。下面将通过示例介绍如何从 Web 日志中快速获取访问流量、HTTP 状态信息、用户 IP 信息、连接数/分钟统计等。
示例场景
站点 www.website.com 共有 5 台 Web 设备,日志文件存放位置:/data/logs/日期(20140215)/access.log,日志为默认的 Apache 定义格式,如:
125.26.28.8- - [01/Aug/2010:09:56:53 +0700] "GET /teacher/jitra/image/pen.
gif HTTP/1.1" 200 12014 "http://www.kpsw.ac.th/teacher/jitra/page4.htm"
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB6.5;
InfoPath.1; .NET CLR 2.0.50727; yie8)"
125.26.28.8- - [01/Aug/2010:09:56:53 +0700] "GET /favicon.ico HTTP/1.1" 200
1187 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0;
GTB6.5; InfoPath.1; .NETCLR 2.0.50727; yie8)"
66.249.65.37- - [01/Aug/2010:09:57:59 +0700] "GET /picture/49-02/DSC02630.jpg
HTTP/1.1" 20079220 "-" "Googlebot-Image/1.0"
66.249.65.37- - [01/Aug/2010:09:59:19 +0700] "GET /elearning/index.php?cal_
m=2&cal_y=2011 HTTP/1.1" 2009232 "-" "Mozilla/5.0 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)"共有 12 列数据(空格分隔),分别为:①客户端IP;②空白(远程登录名称);③空白(认证的远程用户);④请求时间;⑤UTC时差;⑥方法;⑦资源;⑧协议;⑨状态码;⑩发送字节数;⑪访问来源;⑫客户浏览器信息(不具体拆分)。
接下来在 5 台 Web 服务器部署 HDFS 的客户端,以便定期上传 Web 日志到 HDFS 存储平台,最终实现分布式计算。需要安装(JDK 配置环境变量)、Hadoop(原版 tar 包解析即可),详细见 12.2 相关内容。添加上传日志功能作业到 crontab,内容如下:
55 23 * * * /usr/bin/python /home/test/hadoop/hdfsput.py >> /dev/null 2>&1通过 subprocess.Popen() 方法调用 Hadoop HDFS 相关外部命令,实现创建 HDFS 目录及客户端文件上传,详细代码如下:
import subprocess
import sys
import datetime
webid = "web1" # HDFS存储日志标志,其他Web服务器分别为web2、web3、web4、web5
currdate = datetime.datetime.now().strftime('%Y%m%d')
logspath = "/data/logs/" + currdate + "/access.log" # 日志本地路径
logname = "access.log." + webid # HDFS存储日志名
try:
subprocess.Popen(["/usr/local/hadoop-1.2.1/bin/hadoop", "dfs", "-mkdir",
"hdfs://192.168.1.20:9000/user/root/website.com/" + currdate], stdout=subprocess.PIPE)
# 创建HDFS目录,目录格式:website.com/20140205
except Exception as e:
pass
putinfo = subprocess.Popen(["/usr/local/hadoop-1.2.1/bin/hadoop","dfs", "-put", logspath, "hdfs://192.168.1.20:9000/user/root/website.com / "+currdate+" / "+logname], stdout=subprocess.PIPE) #上传本地日志到HDFS
for line in putinfo.stdout:
print(line)在 crontab 定时作业运行后,5台 Web 服务器的日志在 HDFS 上的信息如下:
# /usr/local/hadoop-1.2.1/bin/hadoop dfs -ls /user/root/website.com/20140215
Found 5 items
-rw-r--r-- 3 root supergroup 1565417462014-02-15 23:55 /user/root/website.
com/20140215/access.log.web1
-rw-r--r-- 3 root supergroup 2512453152014-02-15 23:53 /user/root/website.
com/20140215/access.log.web2
-rw-r--r-- 3 root supergroup 1342564122014-02-15 23:55 /user/root/website.
com/20140215/access.log.web3
-rw-r--r-- 3 root supergroup 1923145542014-02-15 23:54 /user/root/website.
com/20140215/access.log.web4
-rw-r--r-- 3 root supergroup 1832678342014-02-15 23:55 /user/root/website.
com/20140215/access.log.web5截至目前,数据的分析源已经准备就绪,接下来的工作便是分析了。
网站访问流量统计
网站访问流量作为衡量一个站点的价值、热度的重要标准,另外在 CDN 服务中流量会涉及计费,如何快速准确分析当前站点的流量数据至关重要,当然,使用 Mrjob 可以很轻松实现此类需求。下面实现精确到分钟统计网站访问流量,原理是在 mapper 操作时将 Web 日志中小时的每分钟作为 key,将对应的行发送字节数作为 value,在 reducer 操作时对相同 key 作累加(sum)统计,详细源码如下:
from mrjob.job import MRJob
import re
class MRCounter(MRJob):
def mapper(self, key, line):
i = 0
for flow in line.split():
if i == 3: # 获取时间字段,位于日志的第4列,内容如“[06/Aug/2010:03:19:44”
timerow = flow.split(":")
hm = timerow[1] + ":" + timerow[2] # 获取“小时:分钟”,作为key
if i == 9 and re.match(r"\d{1,}", flow): # 获取日志第10列-发送的字节数,
作为value
yield hm, int(flow) # 初始化key:value
i += 1
def reducer(self, key, occurrences):
yield key, sum(occurrences) # 相同key“小时:分钟”的value作累加操作
if __name__ == '__main__':
MRCounter.run()生成 Hadoop 任务,运行:
# python /home/test/hadoop/httpflow.py -r hadoop --jobconf mapreduce.job. priority=VERY_HIGH -o hdfs:///output/httpflow hdfs:///user/root/website.com/20140215分析结果见图12-14。
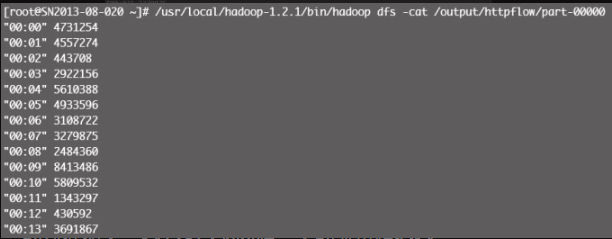
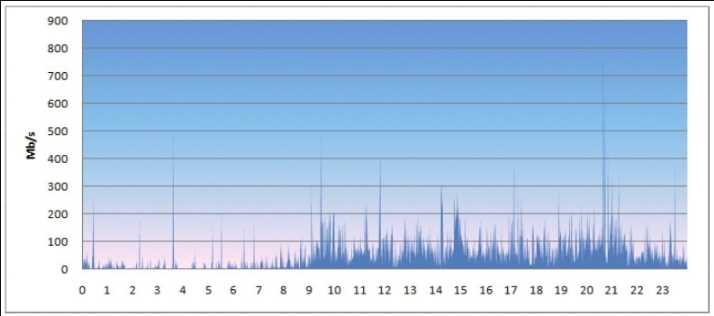
建议将分析结果数据定期入库 MySQL,利用 MySQL 灵活、丰富的 SQL 支持,可以很方便地对数据进行加工,轻松输出比较美观的数据报表。图12-15为网站一天的流量趋势图。
网站HTTP状态码统计
统计一个网站的 HTTP 状态码比例数据,可以帮助我们了解网站的可用度及健康状态,比如我们关注的 200、404、5xx 状态等。在此示例中我们利用 Mrjob 的多步调用的形式来实现,除了基本的 mapper、reducer 方法外,还可以添加自定义处理方法,在 steps 中添加调用即可,详细源码如下:
from mrjob.job import MRJob
import re
class MRCounter(MRJob):
def mapper(self, key, line):
i = 0
for httpcode in line.split():
if i == 8 and re.match(r"\d{1,3}", httpcode): # 获取日志中HTTP状态码段,作为key
yield httpcode, 1 # 初始化key:value,value计数为1,方便reducer作累加
i += 1
def reducer(self, httpcode, occurrences):
yield httpcode, sum(occurrences) # 对排序后的key对应的value作sum累加
def steps(self):
return [self.mr(mapper=self.mapper), # 在steps方法中添加调用队列
self.mr(reducer=self.reducer)]
if __name__ == '__main__':
MRCounter.run()生成 hadoop 任务,分析数据源保持不变,输出目录改成 /output/httpstatus,执行:
# python /home/test/hadoop/httpstatus.py -r hadoop --jobconf mapreduce.job.priority=VERY_HIGH -o hdfs:///output/httpstatus hdfs:///user/root/website.com/20140215分析结果见图12-16。
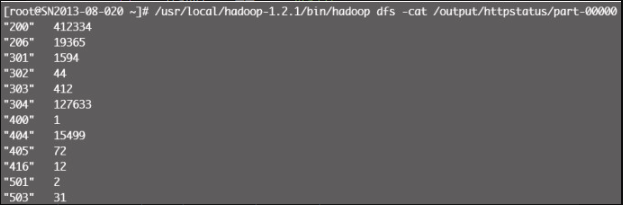
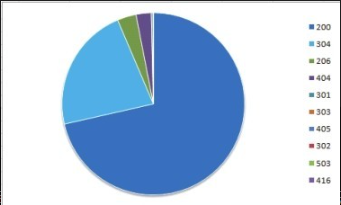
我们可以根据结果数据输出比例饼图,如图12-17所示。
网站分钟级请求数统计
一个网站的请求量大小,直接关系到网站的访问质量,非常有必要对该数据进行分析且关注。本示例以分钟为单位对网站的访问数进行统计,原理与 12.4.2 类似,区别是 value 初始为 1,以便作累加统计,详细源码如下:
from mrjob.job import MRJob
import re
class MRCounter(MRJob):
def mapper(self, key, line):
i = 0
for dt in line.split():
if i == 3: # 获取时间字段,位于日志的第4列,内容如“[06/Aug/2010:03:19:44”
timerow = dt.split(":")
hm = timerow[1] + ":" + timerow[2] # 获取“小时:分钟”,作为key
yield hm, 1 # 初始化key:value,value计数为1,方便reducer作累加
i += 1
def reducer(self, key, occurrences):
yield key, sum(occurrences)
if __name__ == '__main__':
MRCounter.run()生成 Hadoop 任务,输出目录 /output/ http_minute_conn,执行:
# python /home/test/hadoop/http_minute_conn.py -r hadoop --jobconf mapreduce.job.priority=VERY_HIGH -o hdfs:///output/http_minute_conn hdfs:///user/root/website.com/20140215分析结果见图12-18。
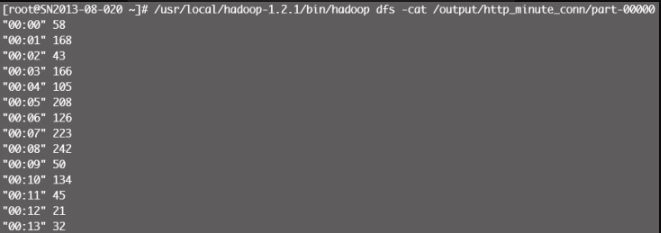
网站访问来源IP统计
统计用户的访问来源 IP 可以更好地了解网站的用户分布,同时也可以帮助安全人员捕捉攻击来源。实现原理是定义匹配 IP 正则字符串作为 key,将 value 初始化为 1,执行 reducer 操作时作累加(sum)统计,详细源码如下:
from mrjob.job import MRJob
import re
IP_RE = re.compile(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}") # 定义IP正则匹配
class MRCounter(MRJob):
def mapper(self, key, line):
# 匹配IP正则后生成key:value,其中key为IP地址,value初始值为1
for ip in IP_RE.findall(line):
yield ip, 1
def reducer(self, ip, occurrences):
yield ip, sum(occurrences)
if __name__ == '__main__':
MRCounter.run()生成 Hadoop 任务,输出目录 /output/ ipstat,执行:
# python /home/test/hadoop/ipstat.py -r hadoop --jobconf mapreduce.job.priority=VERY_HIGH -o hdfs:///output/ipstat hdfs:///user/root/website.com/20140215分析结果见图12-19。
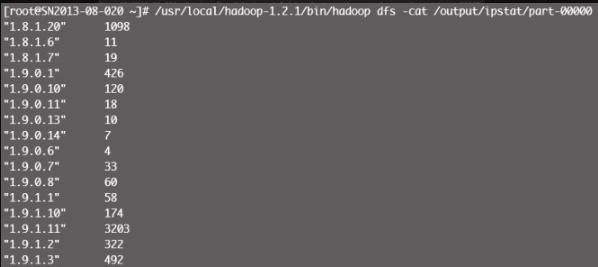
网站文件访问统计
通过统计网站文件的访问次数可以帮助运维人员了解访问最集中的文件,以便进行有针对性的优化,比如调整静态文件过期策略、优化动态 cgi 的执行速度、拆分业务逻辑等。实现原理是将访问文件作为 key,初始化 value 为 1,执行 reducer 时作累加(sum)统计,详细源码如下:
from mrjob.job import MRJob
import re
class MRCounter(MRJob):
def mapper(self, key, line):
i = 0
for url in line.split():
if i == 6: # 获取日志中URL文件资源字段,作为key
yield url, 1
i += 1
def reducer(self, url, occurrences):
yield url, sum(occurrences)
if __name__ == '__main__':
MRCounter.run()执行结果如图12-20所示。
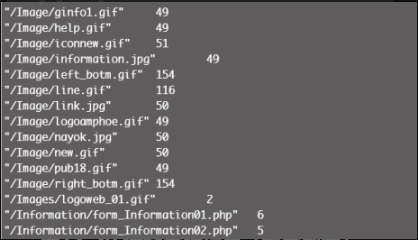
同理,我们可以使用以上方法对 User-Agent 域进行分析,包括浏览器类型及版本、操作系统及版本、浏览器内核等信息,为更好地提升用户体验提供数据支持。
参考提示
-
原生 Python 编写 mapreduce 示例参考 http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/ 。