工程速度
您的公司如何衡量开发者的工作效率(开发者速度)?最常见的方法是通过工作量来衡量。过去,一些公司曾使用代码行数或代码测试覆盖率等指标,但这些显然是糟糕的选择,我不认为现在还有公司在使用这些方法。如果您能用一行代码解决问题,而不是 100 行代码,显然一行代码更可取,因为每一行代码都会带来维护成本。代码测试覆盖率也是一样,覆盖率本身并不能说明测试的质量,差的测试也会带来额外的维护成本。
|
我尽量保持措辞不偏向某一种开发方法。我见过一些团队在采用 DevOps 实践的同时,使用了敏捷、Scrum、Scaled Agile Framework(SAFe)、看板(Kanban)等方法,但也有使用瀑布模型的团队。每种系统都有自己的术语,我尽量保持中立。我谈论的是需求,而不是用户故事或产品待办事项(product backlog items),但我使用的大部分示例基于 Scrum 方法。 |
衡量开发者速度的最常见方法是通过估算需求。您将需求拆解成小项——例如 用户故事——然后产品负责人为每个需求分配一个业务价值。开发团队接着对每个故事进行估算,并分配一个工作量的值。无论您使用故事点、小时、天数或任何其他数字,本质上它们都是对交付该需求所需工作量的表示。
通过工作量衡量速度
通过估算工作量和业务价值来衡量速度,如果您将这些数字报告给管理层,可能会产生副作用。存在某种观察者效应:人们会尝试提高这些数字。在工作量和业务价值的情况下,这是很容易的——您可以简单地给故事分配更大的数字。这通常会发生,尤其是当您跨团队进行比较时:开发人员会给故事分配更大的数字,产品负责人会分配更大的业务价值。
虽然这种方法对于衡量开发者速度并不最优,但如果估算是在团队和产品负责人之间的正常对话中进行的,它也不会造成太大危害。但如果估算发生在正常开发流程之外,估算甚至可能变得有害,并产生非常负面的副作用。
有害的估算
对 “大型功能或计划的成本是多少?” 这个问题的追问,通常会导致在正常开发流程之外进行估算,并且是在决定是否实施之前进行的。那么我们如何估算一个复杂的功能或计划呢?
我们在软件开发中所做的每一件事都是新的。如果您之前做过,您就可以使用现有的软件,而不是重新编写它。因此,即使是对现有模块的完全重写,仍然是新的,因为它使用了新的架构或新的框架。那些从未做过的事情只能在有限的确定性下进行估算。这是猜测,且复杂度越大,不确定性范围越大(参见图1.2)。
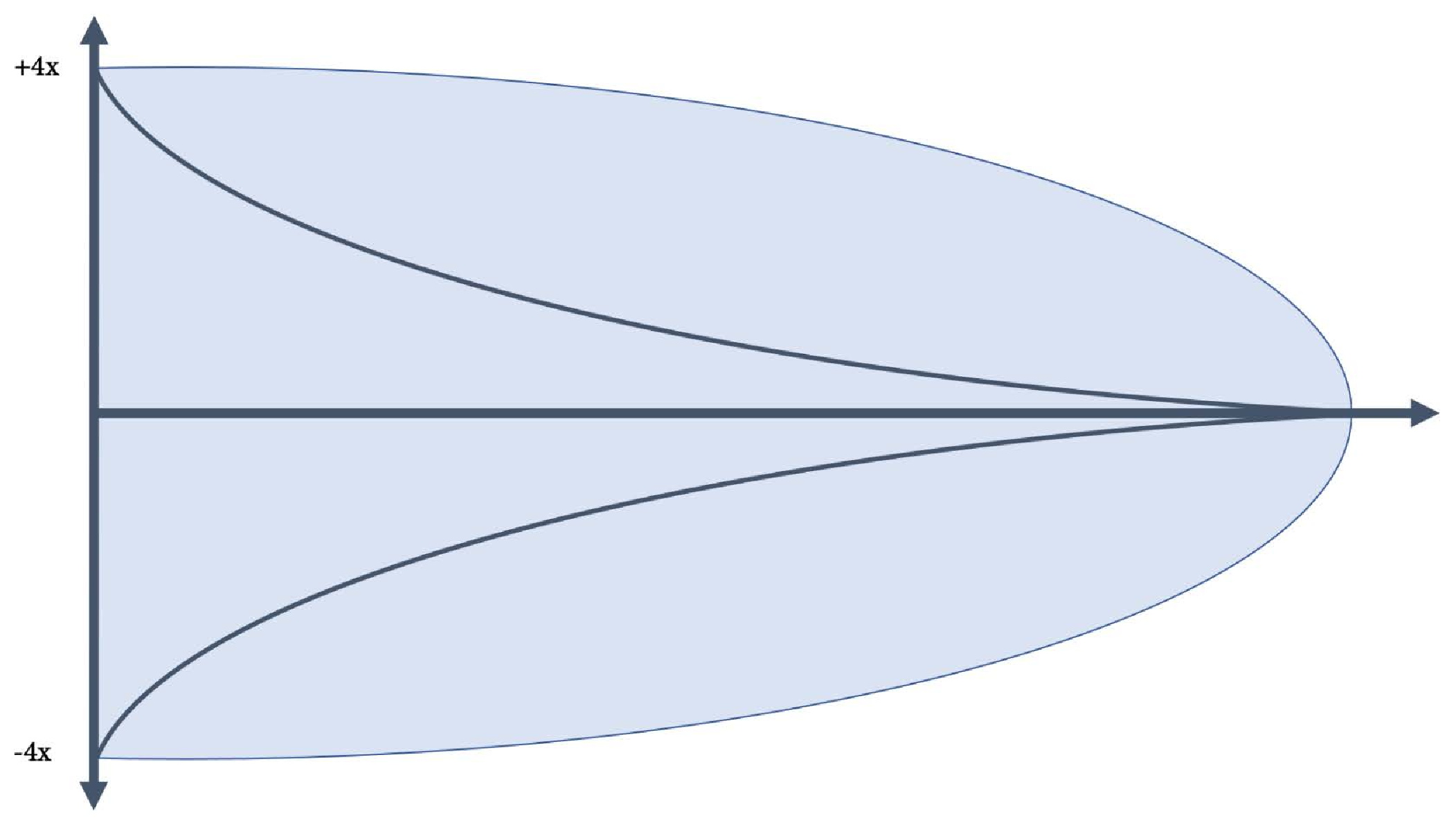
不确定性范围(Cone of Uncertainty)用于项目管理,其前提是,在项目开始时,成本估算存在一定的不确定性,这种不确定性随着滚动计划的推进而逐渐减少,直到项目结束时不确定性为零。x 轴通常表示时间,但也可以与复杂性和抽象性相关:需求越抽象和复杂,估算中的不确定性就越大。
为了更好地估算复杂的功能或计划,这些内容会被分解成更小的部分,这些部分更容易进行估算。你还需要制定一个解决方案架构,作为工作分解的一部分。由于这些工作是在正常开发过程之外进行的,而且是在时间上提前做出的,脱离了上下文,因此它也有一些不良的副作用,如下所示:
-
通常,整个团队并不参与。这导致多样性减少、沟通减少,因此在解决问题时创造性也减少。
-
重点是发现问题。你能提前发现的越多问题,你的估算可能就越准确。特别是当估算后来被用来衡量绩效时,人们很快学会了通过发现更多问题来争取更多时间,因此可以在需求中增加更高的估算值。
-
如果有疑问,负责估算的工程师往往会选择更复杂的解决方案。例如,如果他们不确定能否用现有框架解决问题,他们可能会考虑自己编写一个解决方案,以确保万无一失。
如果这些数字仅用于管理层决定是否实施某个功能,那也不会带来太大危害。但通常,需求—包括估算和解决方案架构—并不会被丢弃,反而会在后续用于实现功能。在这种情况下,最终看到的解决方案通常更加关注问题而非解决方案,这不可避免地导致在实现功能时创造性降低,缺乏跳出框架的思维。
|
# 无需估算 (#NoEstimates) 估算并不是坏事。如果在正确的时机进行,估算是有价值的。如果开发团队和产品负责人讨论下一个故事(user stories),估算可以帮助推动讨论。例如,如果团队使用规划扑克(planning poker)来估算用户故事,而估算结果有差异,这表明大家对如何实现该功能有不同的想法。这可能引发有价值的讨论,并且可能更富有成效,因为大家可以在达成共识的情况下跳过一些故事。这对于业务价值也是适用的。 如果团队无法理解为什么产品负责人给某个需求分配了一个很高或很低的数字,这也可以引发重要的讨论。也许团队已经知道了实现成功结果的方法,或者在不同角色的认知上存在差异。 然而,许多团队会觉得完全不进行需求估算更为舒适,这种做法通常被称为 #noestimates。特别是在高度实验性的环境中,估算通常被视为浪费时间。远程和分布式团队也通常更倾向于不进行估算。他们往往将面对面的讨论转移到问题(issues)和拉取请求(pull requests,PRs)上。这也有助于记录讨论,并帮助团队以更异步的方式工作,从而更好地跨越不同时区的障碍。 既然开发者的生产力不再是重点,团队应该被允许自行决定是否需要估算。这种做法也可能随着时间的推移而改变。有些团队从中获益,而有些则没有。让团队自己决定什么对他们有效,什么无效。 |
高层次计划的正确估算方式
那么,如何估算更复杂的功能或计划,以便产品负责人可以决定这些计划是否值得实施呢?将整个团队聚集在一起,并提出以下问题:这个任务能在几天、几周还是几个月内交付?另一种方法是使用类比估算,将这个计划与已完成的类似任务进行对比。问题是:这个计划比之前完成的那个更小、相等,还是更复杂?
最重要的不是将需求细分或提前制定解决方案架构——关键在于所有工程师的直觉感觉。然后,让每个人为该任务分配一个最小值和最大值。对于类比估算,使用相对于原始计划的百分比,并利用历史数据计算结果。
报告此估算的最简单方法如下:
假设当前团队, 如果我们优先考虑 <计划名称>, 团队有信心在 <最小估算值> 和 <最大估算值> 之间交付该功能。
采取最小估算值和最大估算值是最安全的方法,但如果悲观估算和乐观估算相差甚远,也可能导致数字失真。在这种情况下,平均值可能是更好的数字,如下所示:
假设当前团队, 如果我们优先考虑 <计划名称>, 团队有信心在 <平均最小估算值> 和 <平均最大估算值> 之间交付该功能。
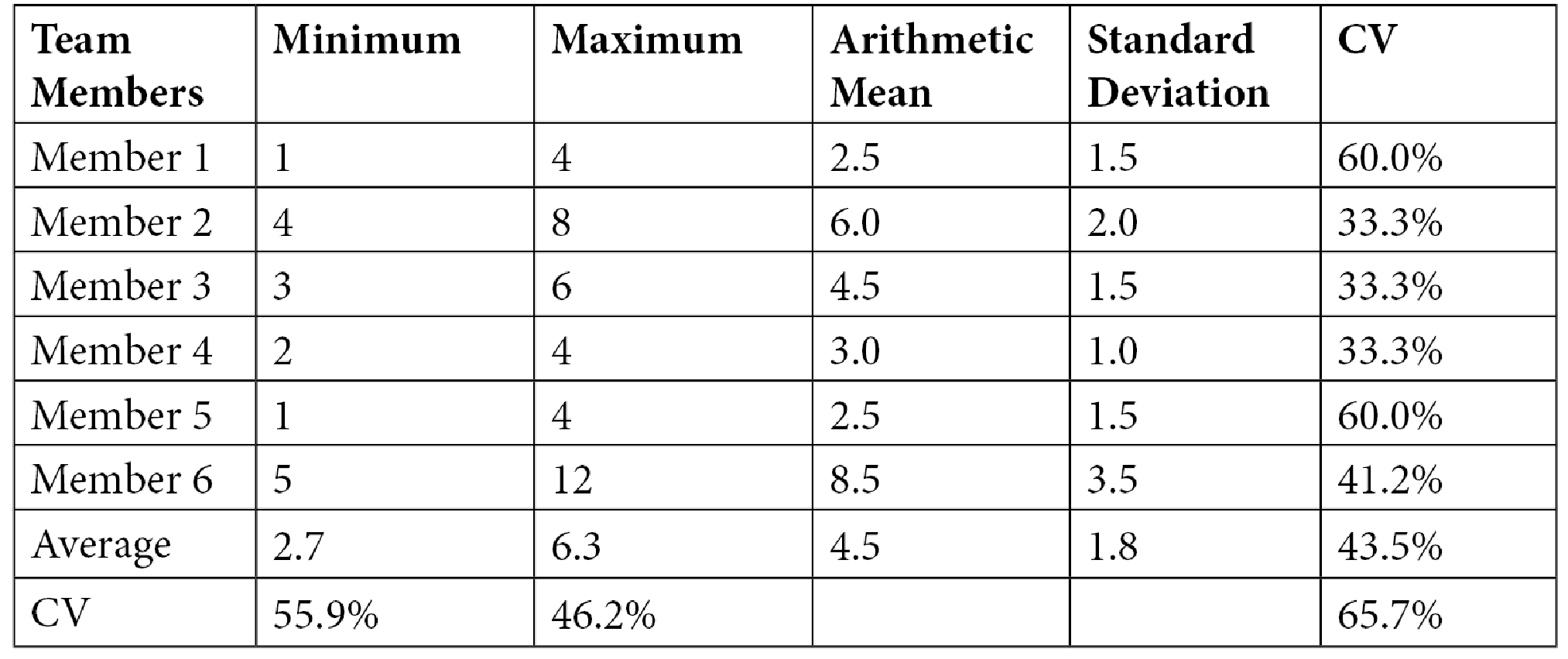
但采取平均值(算术平均数;在 Excel 中使用 =AVERAGE())意味着根据单个估算值的分布,可能会有较高或较低的偏差。偏差越大,您越不能确定是否能在那个周期内交付该功能。为了了解估算的分布情况,您可以计算标准差(=STDEV.P() 在 Excel 中)。您可以查看最小值和最大值的偏差,也可以查看每个成员的估算。偏差越小,值越接近平均值。由于标准差是绝对值,因此无法与其他估算进行比较。为了得到一个相对数值,您可以使用变异系数(CV):标准差除以平均值,通常表示为百分比(=STDEV.P() / AVERAGE() 在 Excel 中)。值越高,估算值从平均值的分布越广;值越低,每个团队成员对估算值的信心越高,或者整个团队对最小值和最大值的信心越强。请参阅下表中的示例:
为了表达数值偏差的不确定性,可以为估算添加一个置信度级别。这个级别可以是文本(例如低、中、高),也可以是百分比级别,如下所示:
给定当前团队, 如果我们优先考虑 <项目名称>, 团队有 <置信度级别> 的信心在 <算术平均值> 时间内交付该功能。
我在这里没有使用固定的公式,因为这需要了解团队的情况。如果你查看表格 1.1 中的数据,你会看到最小值(2.7)和最大值(6.3)的平均值并不是很远。如果你查看各个团队成员,你会发现有更多的悲观和乐观成员。如果过去的估算验证了这一点,那么即使最小值和最大值的变异系数(CV)相当高,也能非常有信心地认为平均值是现实的。你的估算可能会是这样的:
给定当前团队, 如果我们优先考虑 "fancy-new-thing" 项目, 团队有 85% 的信心在 4.5 个月内交付该功能。
这种估算并不是火箭科学。它与复杂的估算和预测系统如三点估算法([三点估算](https://en.wikipedia.org/wiki/Three-point_estimation) )、PERT 分布( [PERT 分布](https://en.wikipedia.org/wiki/PERT_distribution ))或蒙特卡洛模拟方法( [蒙特卡洛方法](https://en.wikipedia.org/wiki/Monte_Carlo_method) )没有关系,这些方法都依赖于对需求的详细拆解和任务(工作)级别的估算。这里的思路是避免提前规划和拆解需求,而是更多依赖于你工程团队的直觉感受。这个技巧只是帮助你从团队中收集的数据点中获得一些洞察,它仍然仅仅是猜测。