了解快速排序
快速排序是另一种应用分而治之法的高效排序算法。虽然它不像合并排序那样分成相等的两半,但它会创建动态分区来对数据进行排序。这就是快速排序的工作原理:
-
从数组中随机选取一个值,我们称之为枢轴。
-
对数组重新排序,使小于中枢值的项目排在中枢值的左边,大于或等于中枢值的项目排在中枢值的右边。这就是所谓的分区。
-
递归调用步骤 1 和 2 来解决两个子数组(中枢的左边和右边)的问题,直到所有项目都排序完毕。
从数组中选取枢轴的方法有很多种。我们可以选择数组最左边的项,也可以选择数组最右边的项。在这两种情况下,如果数组已经排序,那么它的复杂度都是最差的。选择一个好的支点可以提高算法的效率。有几种不同的分区方法。我们将介绍霍尔分区法(Hoare Partition),与其他分区法相比,它的交换次数相对较少。下面是我们的快速排序伪算法。我们将进行就地排序,因此不需要额外空间:
procedure Quicksort(A : array,p :int ,r: int)
if (p < r)
q = Partition(A,p,r)
Quicksort(A,p,q)
Quicksort(A,q+1,r)
end if
end procedure
procedure Partition(A : array,p :int ,r: int)
pivot = A[p]
i = p-1
j = r+1
while (true)
do
i := i + 1
while A[i] < pivot
do
j := j - 1
while A[j] > pivot
if i < j then
swap A[i] with A[j]
else
return j
end if
end while
end procedure我们使用第一个项目作为枢轴元素。我们也可以选择最后一项或取中值来选择枢轴元素。现在让我们用 PHP 来实现算法。
实现快速排序
如伪代码所示,我们将使用两个函数来实现快速排序:一个函数用于快速排序本身,另一个用于分区。下面是快速排序的实现:
Unresolved include directive in modules/ROOT/pages/ch07/ch7-07.adoc - include::example$Chapter07/8.php[]下面是进行分区的实现方法:
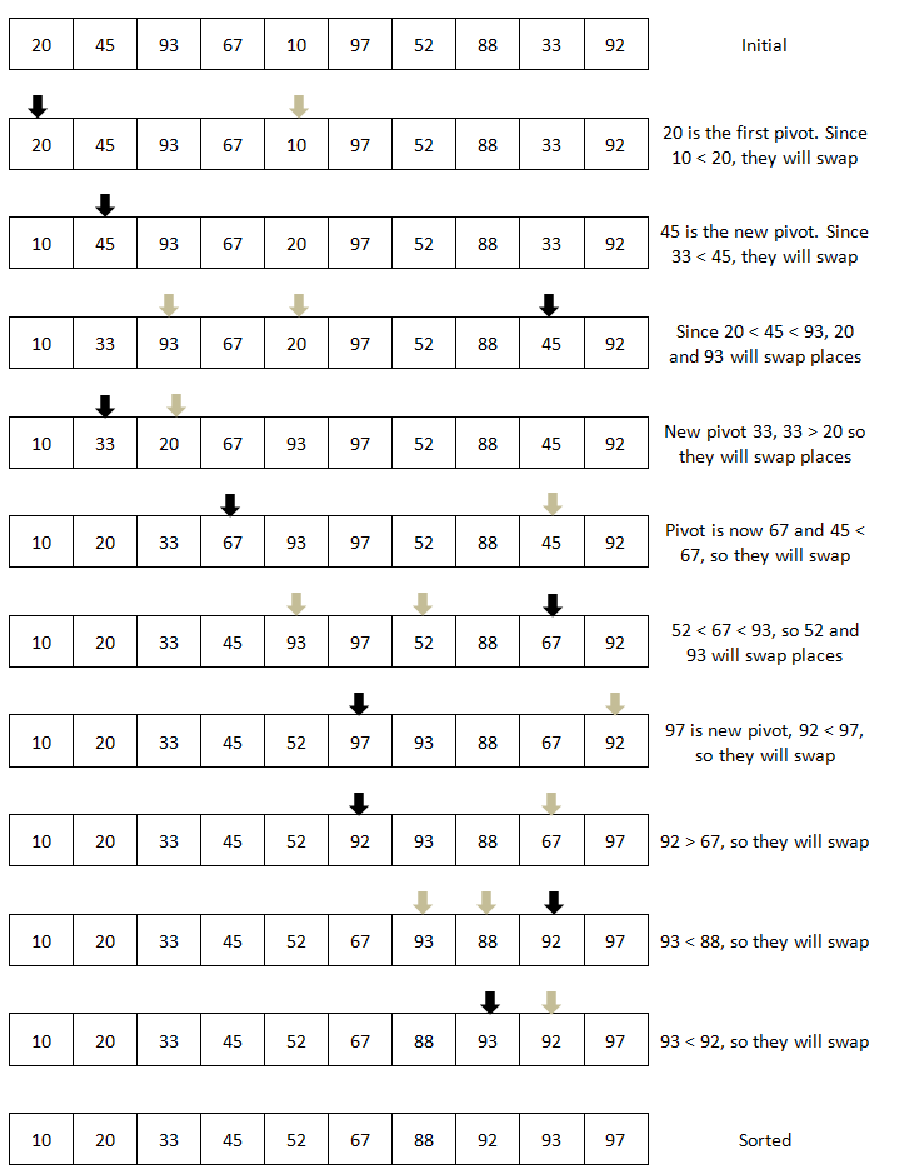
Unresolved include directive in modules/ROOT/pages/ch07/ch7-07.adoc - include::example$Chapter07/8.php[]如果我们直观地说明分区中的枢轴和排序,可以看到下图。为简单起见,我们只显示发生交换的步骤: