Python 数据结构的性能
你对大 O 记法及其不同函数的差别已经有了大致的了解。本节的目标是针对 Python 的列表和字典介绍如何用大 O 记法描述操作的性能。我们会做一些实验,展示在每个数据结构上做某些操作时的损耗与收益。理解这些 Python 数据结构的效率很重要,因为它们是本书用来实现其他数据结构的基石。本节不会解释性能优劣的原因。在后续章节中,你会看到列表和字典的一些可能的实现,以及为何性能取决于实现。
列表
在实现列表数据结构时,Python 的设计师有许多选择,每一个选择都会影响操作的性能。为了做出正确的选择,他们考虑了列表最常见的用法,并据此优化列表的实现,以使最常用的操作非常快。当然,他们也尽力使不常用的操作也很快,但在需要权衡时,往往会牺牲低频操作的性能。
两个常见操作是索引和给某个位置赋值。无论列表多长,这两个操作所花的时间应该恒定。像这种与列表长度无关的操作就是常数阶的。
另一个常见的操作是加长列表。有两种方式:要么采用追加方法,要么执行连接操作。追加方法是常数阶的。如果待连接列表的长度为 k,那么连接操作的时间复杂度就是 \$O(k)\$。知道这一点很重要,因为它能帮你选择正确的工具,使程序更高效。
假设要从 0 开始生成含有 n 个数的列表,来看看 4 种生成方式。首先,用 for 循环通过连接操作创建列表;其次,采用追加方法;再次,使用列表解析式;最后,用列表构造器调用 range 函数(这可能是最容易想到的方式)。代码清单2-9 给出了 4 种方式的代码。假设代码保存在文件 listfuns.py 中。
def test1():
l = []
for i in range(1000):
l = l + [i]
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = [i for i in range(1000)]
def test4():
l = list(range(1000))要得到每个函数的执行时间,需要用到 Python 的 timeit 模块。该模块使 Python 开发人员能够在一致的环境下运行函数,并且在多种操作系统下使用尽可能相似的机制,以实现跨平台计时。
要使用 timeit 模块,首先创建一个 Timer 对象,其参数是两条 Python 语句。第 1 个参数是要为之计时的 Python 语句;第 2 个参数是建立测试的语句。timeit 模块会统计多次执行语句要用多久。默认情况下,timeit 会执行 100 万次语句,并在完成后返回一个浮点数格式的秒数。不过,既然这是执行 100 万次所用的秒数,就可以把结果视作执行 1 次所用的微秒数。此外,可以给 timeit 传入参数 number,以指定语句的执行次数。下面的例子展示了测试函数各运行 1000 次所花的时间。
t1 = Timer("test1()", "from __main__ import test1")
print("concat ", t1.timeit(number=1000), "milliseconds")
t2 = Timer("test2()", "from __main__ import test2")
print("append ", t2.timeit(number=1000), "milliseconds")
t3 = Timer("test3()", "from __main__ import test3")
print("comprehension ", t3.timeit(number=1000), "milliseconds")
t4 = Timer("test4()", "from __main__ import test4")
print("list range ", t4.timeit(number=1000), "milliseconds")
concat 6.54352807999 milliseconds
append 0.306292057037 milliseconds
comprehension 0.147661924362 milliseconds
list range 0.0655000209808 milliseconds在本例中,计时的语句是对 test1()、test2() 等的函数调用。你也许会觉得建立测试的语句有些奇怪,所以我们仔细研究一下。你可能已经熟悉 from 和 import,但它们通常在 Python 程序文件的开头使用。本例中,from __main__ import test1 将 test1 函数从 __main__ 命名空间导入到 timeit 设置计时的命名空间。timeit 模块这么做,是为了在一个干净的环境中运行计时测试,以免某些变量以某种意外的方式干扰函数的性能。
实验结果清楚地表明,0.30 毫秒的追加操作远快于 6.54 毫秒的连接操作。实验也测试了另两种列表创建操作:使用列表解析式,以及使用列表构造器调用 range。有趣的是,与用 for 循环进行追加操作相比,使用列表解析式几乎快一倍。
关于这个小实验要说明的最后一点是,执行时间其实包含了调用测试函数的额外开销,但可以假设 4 种情形的函数调用开销相同,所以对比操作还是有意义的。鉴于此,说连接操作花了 6.54 毫秒不太准确,应该说用于连接操作的测试函数花了 6.54 毫秒。可以做个练习,测一下调用空函数的时间,然后从之前得到的数字中减去。
知道如何衡量性能之后,可以对照表2-2,看看基本列表操作的大 O 效率。仔细考虑之后,你可能会对 pop 的两种效率有疑问。在列表末尾调用 pop 时,操作是常数阶的,在列表头一个元素或中间某处调用 pop 时,则是 n 阶的。原因在于 Python 对列表的实现方式。在 Python 中,从列表头拿走一个元素,其他元素都要向列表头挪一位。你可能觉得这个做法有点傻,但再看看表2-2,你会明白这种实现保证了索引操作为常数阶。Python 的实现者认为这是不错的取舍决策。
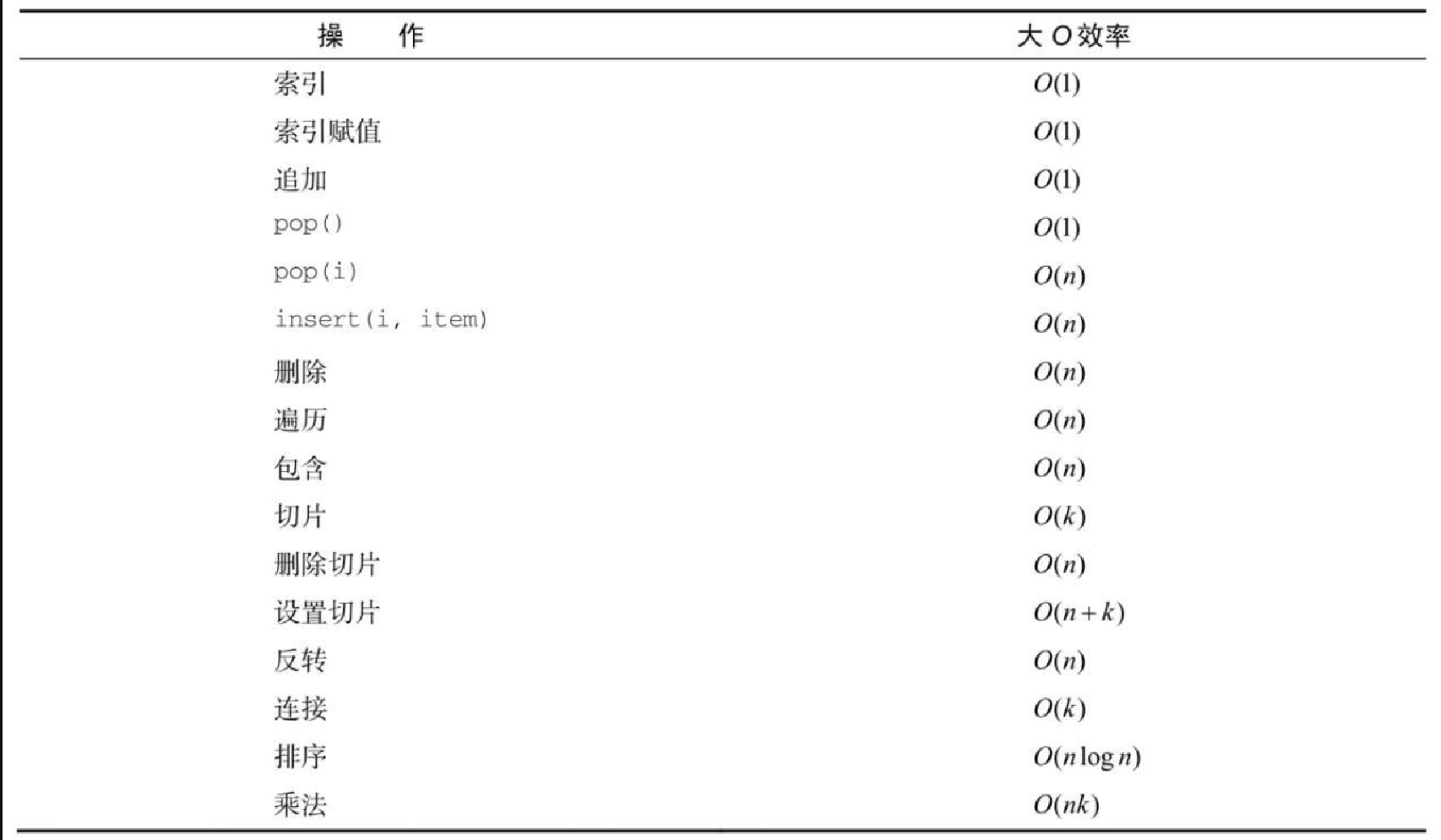
为了展示 pop() 和 pop(i) 的性能差异,我们使用 timeit 模块做另一个实验。实验目标是针对一个长度已知的列表,分别从列表头和列表尾弹出一个元素。我们也想衡量不同长度下的执行时间。预期结果是,从列表尾弹出元素的时间是恒定的,而从列表头弹出元素的时间会随着列表变长而增加。代码清单2-10是实验代码。可以看到,从列表尾弹出元素花了 0.0003 毫秒,从列表头弹出花了 4.8214 毫秒。对于含有 200 万个元素的列表来说,后者是前者的 16000 倍。
有两点需要说明。首先是 from __main__ import x 语句。尽管没有定义一个函数,但是我们仍然希望能在测试中使用列表对象 x。这个办法允许我们只对 pop 语句计时,从而准确地获得这一个操作的耗时。其次,因为计时重复了 1000 次,所以列表每次循环都少一个元素。不过,由于列表的初始长度是 200 万,因此对于整体长度来说,只减少了 0.05%。
popzero = timeit.Timer("x.pop(0)",
"from __main__ import x")
popend = timeit.Timer("x.pop()",
"from __main__ import x")
x = list(range(2000000))
popzero.timeit(number=1000)
4.8213560581207275
x = list(range(2000000))
popend.timeit(number=1000)
0.0003161430358886719虽然测试结果说明 pop(0) 确实比 pop() 慢,但是并没有证明 pop(0) 的时间复杂度是 \$O(n)\$,也没有证明 pop() 的是 \$O(1)\$。要证明这一点,需要看看两个操作在各个列表长度下的性能。代码清单2-11实现了这个测试。

图2-3展示了实验结果。可以看出,列表越长,pop(0) 的耗时也随之变长,而 pop() 的耗时很稳定。这刚好符合 \$O(n)\$ 和 \$O(1)\$ 的特征。
popzero = Timer("x.pop(0)",
"from __main__ import x")
popend = Timer("x.pop()",
"from __main__ import x")
print("pop(0) pop()")
for i in range(1000000,100000001,1000000):
x = list(range(i))
pt = popend.timeit(number=1000)
x = list(range(i))
pz = popzero.timeit(number=1000)
print("%15.5f, %15.5f" %(pz,pt))实验会有一些误差。因为用来测量的计算机运行着其他进程,所以可能拖慢代码的速度。因此,尽管我们尽力减少计算机所做的其他工作,测出的时间仍然会有些许变化。这也是测试 1000 遍的原因,从统计角度来说,收集足够多的信息有助于得到可靠的结果。
字典
Python 的第二大数据结构就是字典。你可能还记得,字典不同于列表的地方在于,可以通过键——而不是位置——访问元素。你会在后文中发现,实现字典有许多方法。现在最重要的是,知道字典的取值操作和赋值操作都是常数阶。另一个重要的字典操作就是包含(检查某个键是否在字典中),它也是常数阶。表2-3总结了所有字典操作的大 O 效率。要注意,表中给出的效率针对的是普通情况。在某些特殊情况下,包含、取值、赋值等操作的时间复杂度可能变成 \$O(n)\$。后文在讨论不同的字典实现方式时会详细说明。

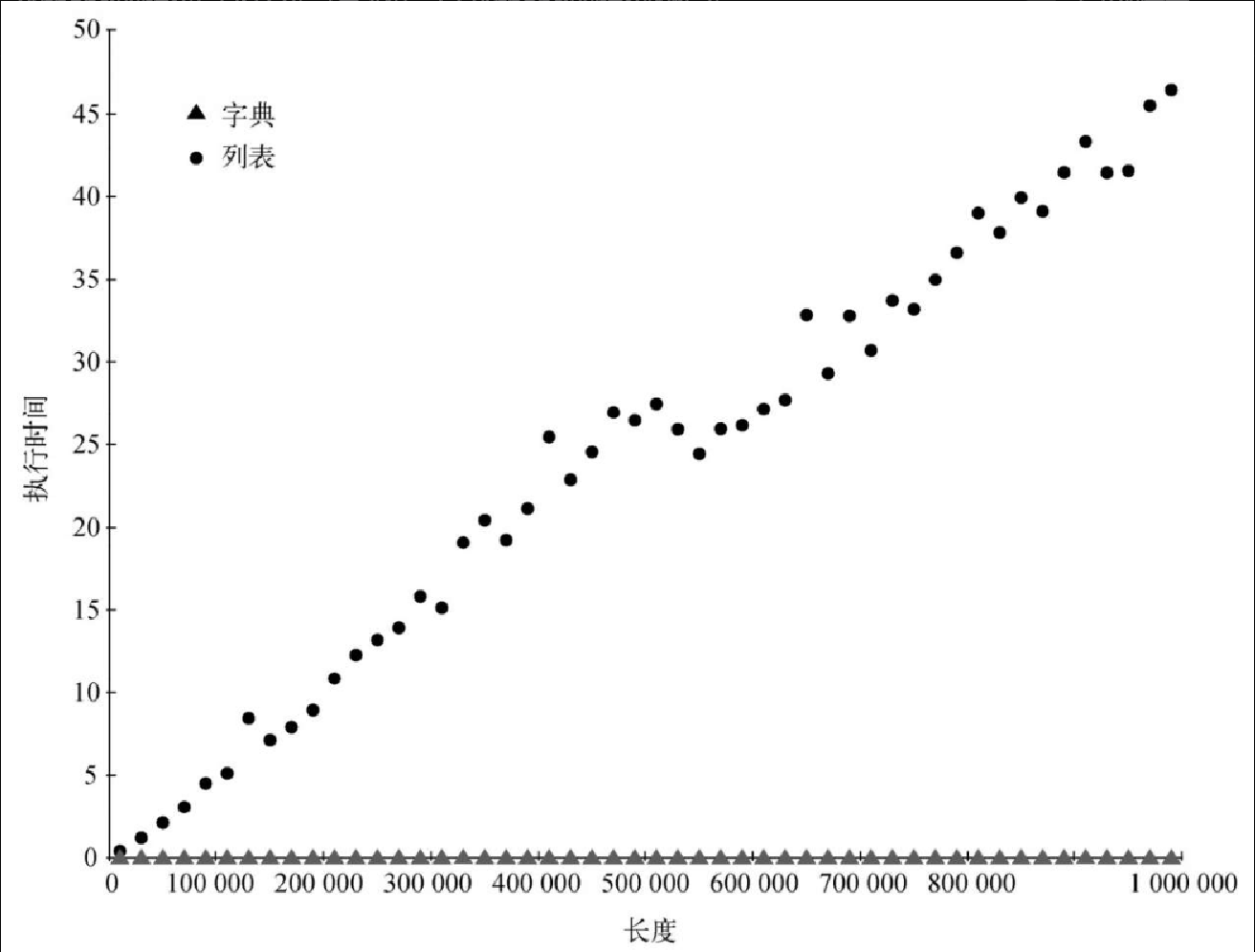
最后一个性能实验会比较列表和字典的包含操作,并验证列表的包含操作是 \$O(n)\$,而字典的是 \$O(1)\$。实验很简单,首先创建一个包含一些数的列表,然后随机取一些数,看看它们是否在列表中。如果表2-2 给出的效率是正确的,那么随着列表变长,判断一个数是否在列表中所花的时间也就越长。
对于以数字为键的字典,重复上述实验。我们会看到,判断数字是否在字典中的操作,不仅快得多,而且当字典变大时,耗时基本不变。
代码清单2-12 实现了这个对比实验。注意,我们进行的是完全相同的操作。不同点在于,第 7 行的 x 是列表,第 9 行的 x 则是字典。
import timeit
import random
for i in range(10000,1000001,20000):
t = timeit.Timer("random.randrange(%d) in x"%i,
"from __main__ import random,x")
x = list(range(i))
lst_time = t.timeit(number=1000)
x = {j:None for j in range(i)}
d_time = t.timeit(number=1000)
print("%d,%10.3f,%10.3f" % (i, lst_time, d_time))图2-4 展示了运行结果。可以看出,字典一直更快。对于元素最少的情况(10000),字典的速度是列表的 89.4 倍。对于元素最多的情况(990000),字典的速度是列表的 11603 倍!还可以看出,随着规模增加,列表的包含操作在耗时上的增长是线性的,这符合 \$O(n)\$。对于字典来说,即使规模增加,包含操作的耗时也是恒定的。实际上,当字典有 10000 个元素时,包含操作的耗时是 0.004 毫秒,当有 990000 个元素时,耗时还是 0.004 毫秒。
Python 是一门变化中的语言,内部实现一直会有更新。可以在官网上找到 Python 数据结构性能的最新信息。此外,可以参考 Python 的时间复杂度页面: http://wiki.python.org/moin/TimeComplexity 。