列表
本章使用了 Python 列表来实现其他抽象数据类型。列表是简洁而强大的元素集合,它为程序员提供了很多操作。但是,并非所有编程语言都有列表。对于不提供列表的编程语言,程序员必须自己动手实现。
列表是元素的集合,其中每一个元素都有一个相对于其他元素的位置。更具体地说,这种列表称为无序列表。可以认为列表有第一个元素、第二个元素、第三个元素,等等;也可以称第一个元素为列表的起点,称最后一个元素为列表的终点。为简单起见,我们假设列表中没有重复元素。
假设 54, 26, 93, 17, 77, 31 是考试分数的无序列表。注意,列表通常使用逗号作为分隔符。这个列表在 Python 中显示为 [54, 26, 93, 17, 77, 31] 。
无序列表抽象数据类型
如前所述,无序列表是元素的集合,其中每一个元素都有一个相对于其他元素的位置。以下是无序列表支持的操作。
-
List() 创建一个空列表。它不需要参数,且会返回一个空列表。
-
add(item) 假设元素 item 之前不在列表中,并向其中添加 item。它接受一个元素作为参数,无返回值。
-
remove(item) 假设元素 item 已经在列表中,并从其中移除 item。它接受一个元素作为参数,并且修改列表。
-
search(item) 在列表中搜索元素 item。它接受一个元素作为参数,并且返回布尔值。
-
isEmpty() 检查列表是否为空。它不需要参数,并且返回布尔值。
-
length() 返回列表中元素的个数。它不需要参数,并且返回一个整数。
-
append(item) 假设元素 item 之前不在列表中,并在列表的最后位置添加 item。它接受一个元素作为参数,无返回值。
-
index(item) 假设元素 item 已经在列表中,并返回该元素在列表中的位置。它接受一个元素作为参数,并且返回该元素的下标。
-
insert(pos, item) 假设元素 item 之前不在列表中,同时假设 pos 是合理的值,并在位置 pos 处添加元素 item。它接受两个参数,无返回值。
-
pop() 假设列表不为空,并移除列表中的最后一个元素。它不需要参数,且会返回一个元素。
-
pop(pos) 假设在指定位置 pos 存在元素,并移除该位置上的元素。它接受位置参数,且会返回一个元素。
实现无序列表:链表
为了实现无序列表,我们要构建链表。无序列表需要维持元素之间的相对位置,但是并不需要在连续的内存空间中维护这些位置信息。以图3-18 中的元素集合为例,这些元素的位置看上去都是随机的。如果可以为每一个元素维护一份信息,即下一个元素的位置(如图3-19 所示),那么这些元素的相对位置就能通过指向下一个元素的链接来表示。

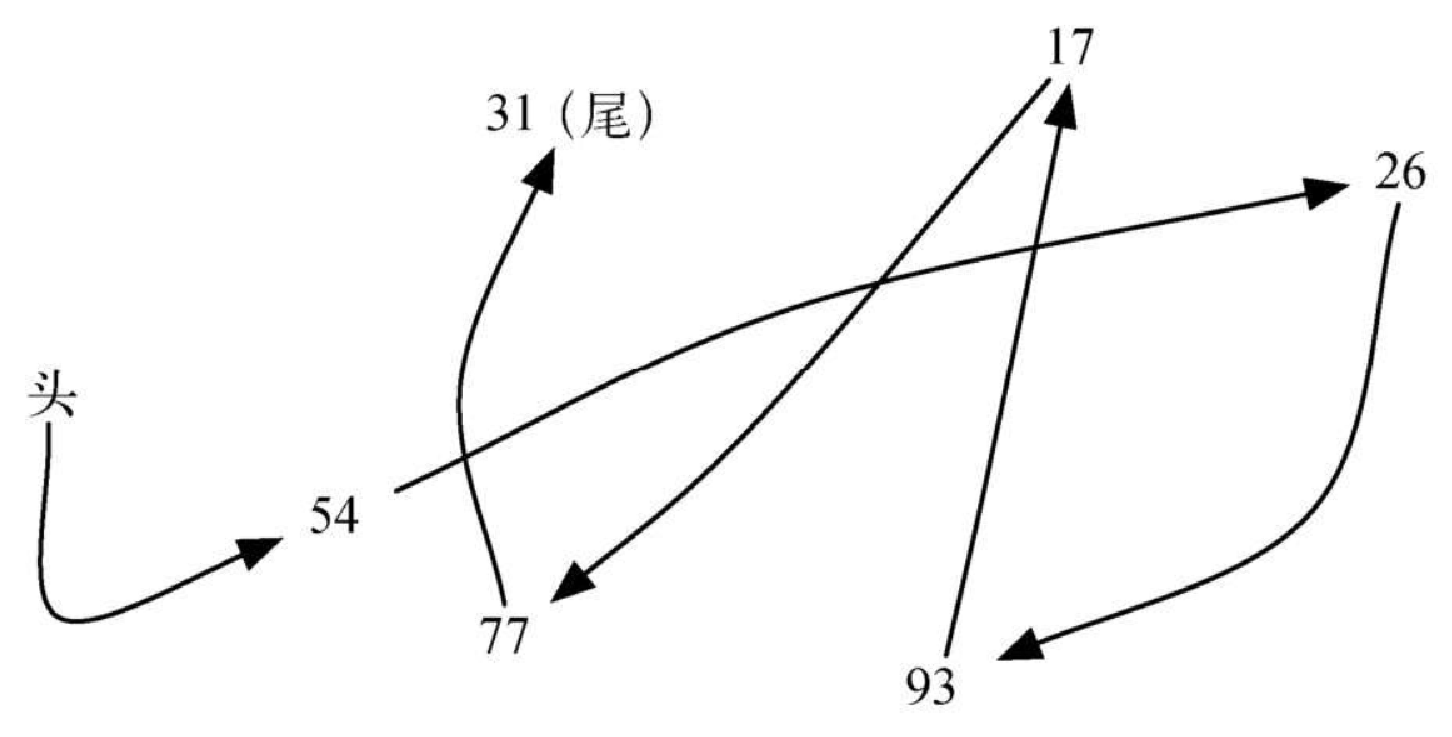
需要注意的是,必须指明列表中第一个元素的位置。一旦知道第一个元素的位置,就能根据其中的链接信息访问第二个元素,接着访问第三个元素,依此类推。指向链表第一个元素的引用被称作头。最后一个元素需要知道自己没有下一个元素。
-
Node类
节点(node)是构建链表的基本数据结构。每一个节点对象都必须持有至少两份信息。首先,节点必须包含列表元素,我们称之为节点的数据变量。其次,节点必须保存指向下一个节点的引用。代码清单3-16 展示了 Node 类的 Python 实现。在构建节点时,需要为其提供初始值。执行下面的赋值语句会生成一个包含数据值93的节点对象,如图3-20 所示。需要注意的是,一般会像图3-21 所示的那样表示节点。Node 类也包含访问和修改数据的方法,以及指向下一个元素的引用。
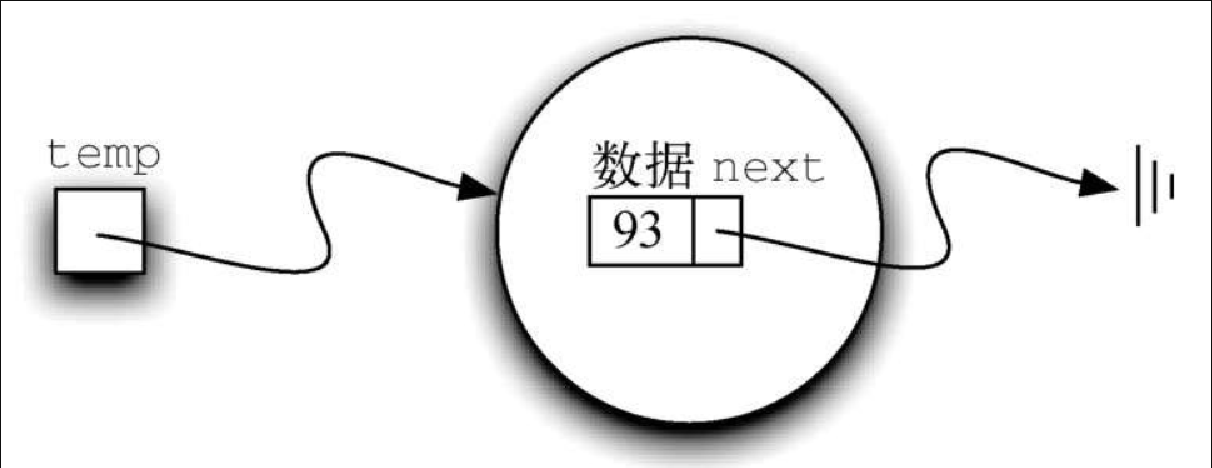 Figure 3. 图3-20 节点对象包含元素及指向下一个节点的引用
Figure 3. 图3-20 节点对象包含元素及指向下一个节点的引用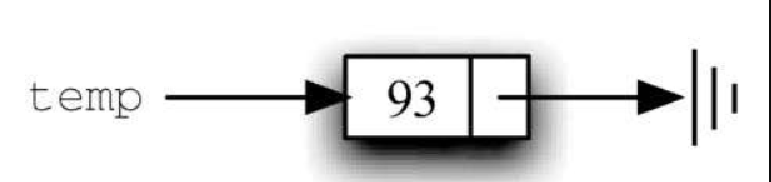 Figure 4. 图3-21 节点的常见表示法
Figure 4. 图3-21 节点的常见表示法>>> temp = Node(93) >>> temp.getData() 93特殊的 Python 引用值 None 在 Node 类以及之后的链表中起到了重要的作用。指向 None 的引用代表着后面没有元素。注意,Node 的构造方法将 next 的初始值设为 None。由于这有时被称为 “将节点接地”,因此我们使用接地符号来代表指向 None 的引用。将 None 作为 next 的初始值是不错的做法。
代码清单3-16 Node类class Node: def __init__(self,initdata): self.data = initdata self.next = None def getData(self): return self.data def getNext(self): return self.next def setData(self,newdata): self.data = newdata def setNext(self,newnext): self.next = newnext -
UnorderedList类
如前所述,无序列表(unordered list)是基于节点集合来构建的,每一个节点都通过显式的引用指向下一个节点。只要知道第一个节点的位置(第一个节点包含第一个元素),其后的每一个元素都能通过下一个引用找到。因此,UnorderedList 类必须包含指向第一个节点的引用。代码清单3-17 展示了 UnorderedList 类的构造方法。注意,每一个列表对象都保存了指向列表头部的引用。
代码清单3-17 UnorderedList类的构造方法class UnorderedList: def __init__(self): self.head = None最开始构建列表时,其中没有元素。赋值语句 mylist = UnorderedList() 将创建如图3-22 所示的链表。与在 Node 类中一样,特殊引用值 None 用于表明列表的头部没有指向任何节点。最终,前面给出的样例列表将由如图3-23 所示的链表来表示。列表的头部指向包含列表第一个元素的节点。这个节点包含指向下一个节点(元素)的引用,依此类推。非常重要的一点是,列表类本身并不包含任何节点对象,而只有指向整个链表结构中第一个节点的引用。
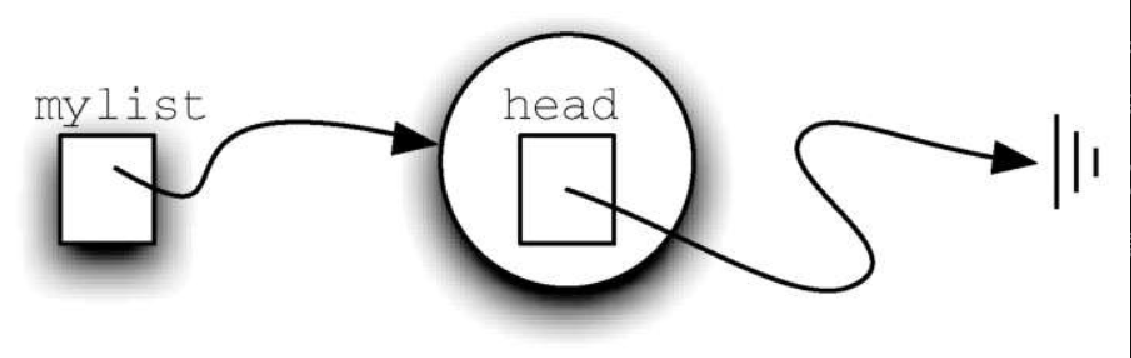 Figure 5. 图3-22 空列表
Figure 5. 图3-22 空列表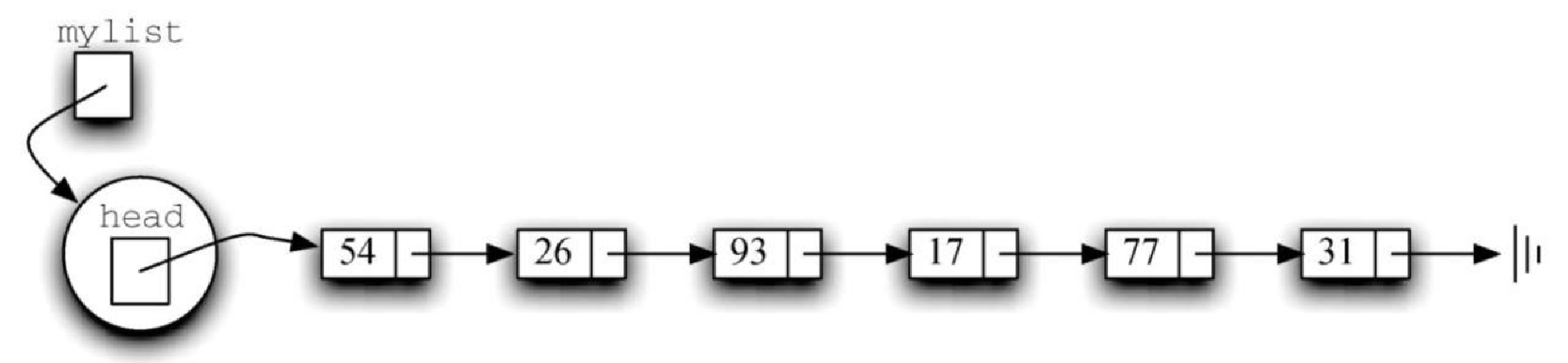 Figure 6. 图3-23 由整数组成的链表
Figure 6. 图3-23 由整数组成的链表在代码清单3-18 中,isEmpty 方法检查列表的头部是否为指向 None 的引用。布尔表达式 self.head == None 当且仅当链表中没有节点时才为真。由于新的链表是空的,因此构造方法必须和检查是否为空的方法保持一致。这体现了使用 None 表示链表末尾的好处。在 Python 中,None 可以和任何引用进行比较。如果两个引用都指向同一个对象,那么它们就是相等的。我们将在后面的方法中经常使用这一特性。
代码清单3-18 isEmpty方法def isEmpty(self): return self.head == None为了将元素添加到列表中,需要实现 add 方法。但在实现之前,需要解决一个重要问题:新元素要被放在链表的哪个位置?由于本例中的列表是无序的,因此新元素相对于已有元素的位置并不重要。新的元素可以在任意位置。因此,将新元素放在最简便的位置是最合理的选择。
由于链表只提供一个入口(头部),因此其他所有节点都只能通过第一个节点以及 next 链接来访问。这意味着添加新节点最简便的位置就是头部,或者说链表的起点。我们把新元素作为列表的第一个元素,并且把已有的元素链接到该元素的后面。
通过多次调用 add 方法,可以构建出如图3-23 所示的链表。
>>> mylist.add(31) >>> mylist.add(77) >>> mylist.add(17) >>> mylist.add(93) >>> mylist.add(26) >>> mylist.add(54)注意,由于 31 是第一个被加入列表的元素,因此随着后续元素不断被加入列表,它最终成了最后一个元素。同理,由于 54 是最后一个被添加的元素,因此它成为链表中第一个节点的数据值。
代码清单3-19 展示了 add 方法的实现。列表中的每一个元素都必须被存放在一个节点对象中。第 2 行创建一个新节点,并且将元素作为其数据。现在需要将新节点与已有的链表结构链接起来。这一过程需要两步,如图 3-24 所示。第 1 步(第 3 行),将新节点的 next 引用指向当前列表中的第一个节点。这样一来,原来的列表就和新节点正确地链接在了一起。第 2 步,修改列表的头节点,使其指向新创建的节点。第 4 行的赋值语句完成了这一操作。
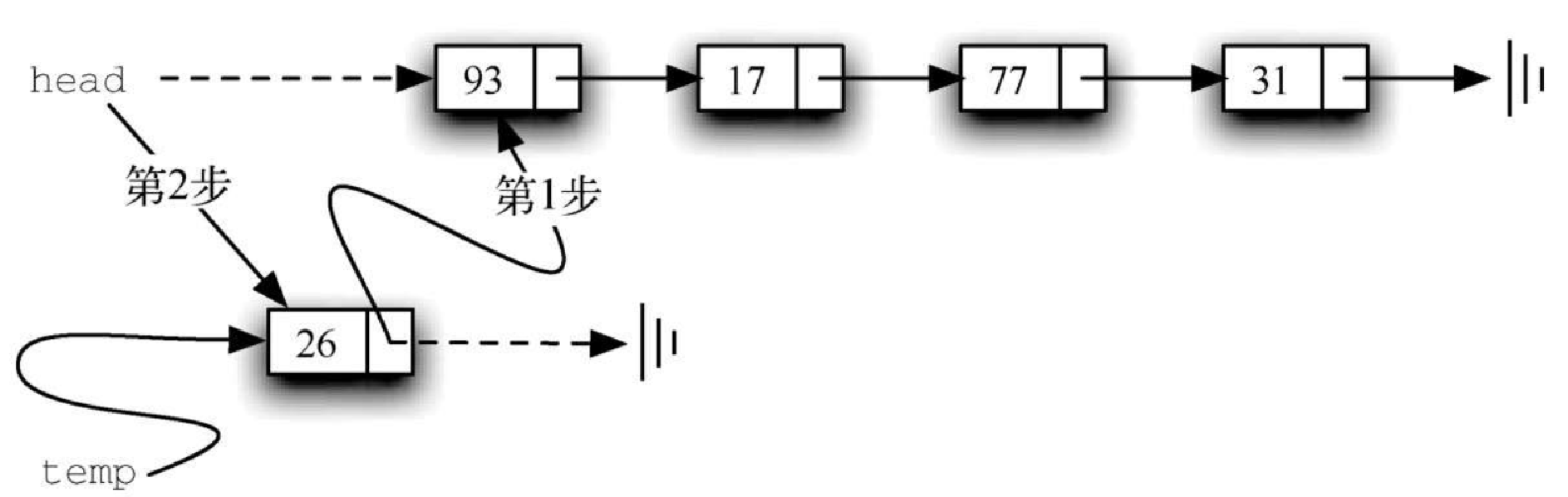 Figure 7. 图3-24 通过两个步骤添加新节点代码清单3-19 add方法
Figure 7. 图3-24 通过两个步骤添加新节点代码清单3-19 add方法def add(self,item): temp = Node(item) temp.setNext(self.head) self.head = temp上述两步的顺序非常重要。如果颠倒第 3 行和第 4 行的顺序,会发生什么呢?如果先修改列表的头节点,将得到如图3-25 所示的结果。由于头节点是唯一指向列表节点的外部引用,因此所有的已有节点都将丢失并且无法访问。
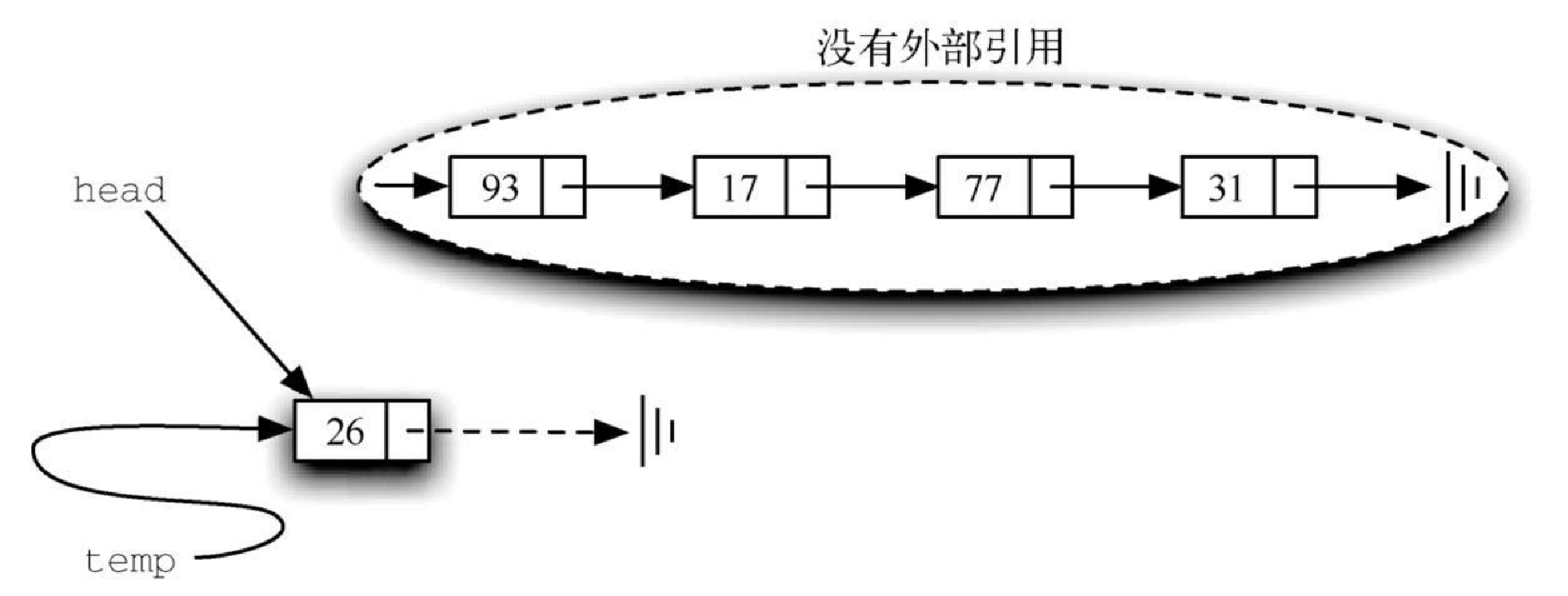 Figure 8. 图3-25 先修改列表的头节点将导致已有节点丢失
Figure 8. 图3-25 先修改列表的头节点将导致已有节点丢失接下来要实现的方法——length、search 以及 remove——都基于链表遍历这个技术。遍历是指系统地访问每一个节点,具体做法是用一个外部引用从列表的头节点开始访问。随着访问每一个节点,我们将这个外部引用通过 “遍历” 下一个引用来指向下一个节点。
为了实现 length 方法,需要遍历链表并且记录访问过多少个节点。代码清单3-20 展示了计算列表中节点个数的 Python 代码。current 就是外部引用,它在第 2 行中被初始化为列表的头节点。在计算开始时,由于没有访问到任何节点,因此 count 被初始化为 0。第 4~6 行实现遍历过程。只要 current 引用没有指向列表的结尾(None),就将它指向下一个节点(第 6 行)。引用能与 None 进行比较,这一特性非常重要。每当 current 指向一个新节点时,将 count 加 1。最终,循环完成后返回 count。图3-26 展示了整个处理过程。
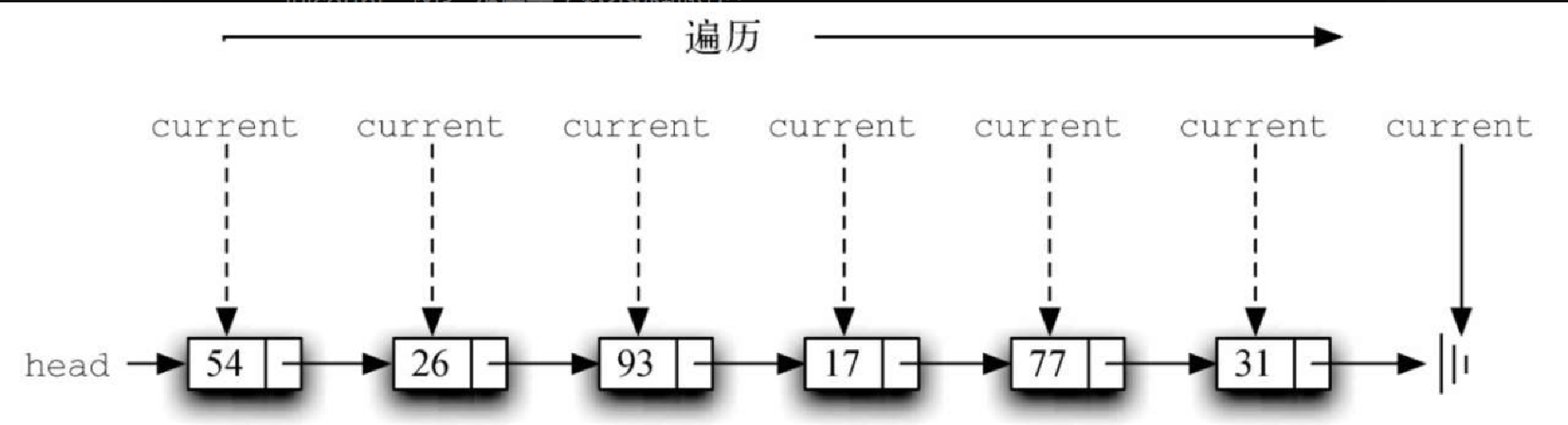 Figure 9. 图3-26 从头到尾遍历链表代码清单3-20 length方法
Figure 9. 图3-26 从头到尾遍历链表代码清单3-20 length方法def length(self): current = self.head count = 0 while current != None: count = count + 1 current = current.getNext() return count在无序列表中搜索一个值同样也会用到遍历技术。每当访问一个节点时,检查该节点中的元素是否与要搜索的元素相同。在搜索时,可能并不需要完整遍历列表就能找到该元素。事实上,如果遍历到列表的末尾,就意味着要找的元素不在列表中。如果在遍历过程中找到所需的元素,就没有必要继续遍历了。
代码清单3-21 展示了 search 方法的实现。与在 length 方法中相似,遍历从列表的头部开始(第 2 行)。我们使用布尔型变量 found 来标记是否找到所需的元素。由于一开始时并未找到该元素,因此第 3 行将 found 初始化为 False。第 4 行的循环既考虑了是否到达列表末尾,也考虑了是否已经找到目标元素。只要还有未访问的节点并且还没有找到目标元素,就继续检查下一个节点。第 5 行检查当前节点中的元素是否为目标元素。如果是,就将 found 设为 True。
代码清单3-21 search方法def search(self,item): current = self.head found = False while current != None and not found: if current.getData() == item: found = True else: current = current.getNext() return found以下调用 search 方法来寻找元素 17。
>>> mylist.search(17) True由于 17 在列表中,因此遍历过程只需进行到含有 17 的节点即可。此时,found 变量被设为 True,从而使 while 循环退出,最终得到上面的输出结果。图3-27 展示了这一过程。
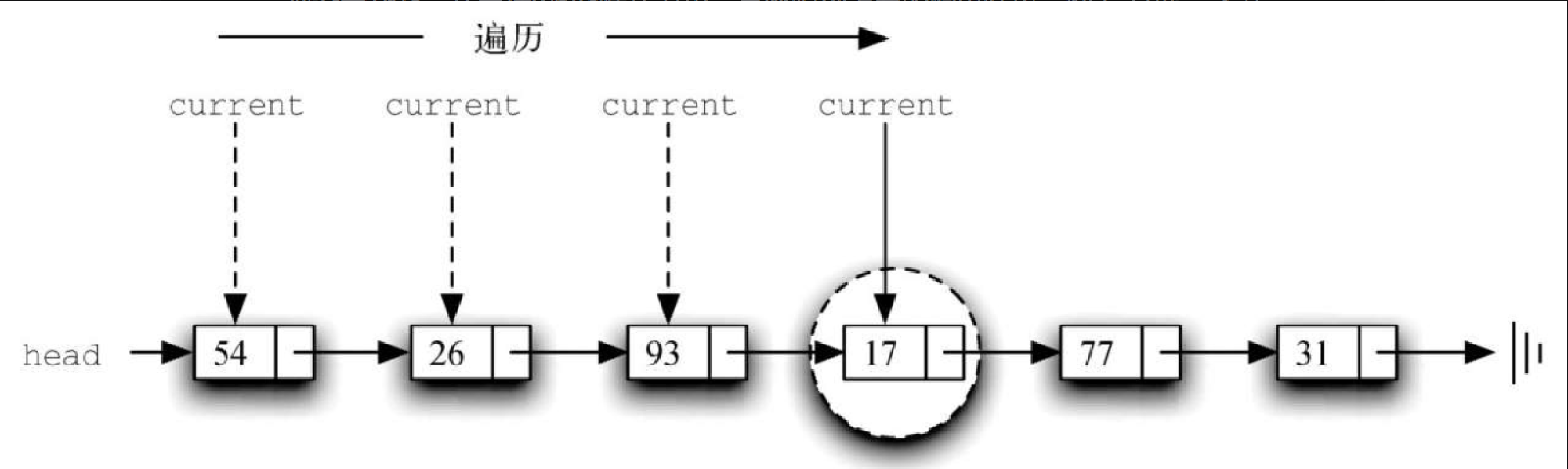 Figure 10. 图3-27 成功搜索到元素17
Figure 10. 图3-27 成功搜索到元素17remove 方法在逻辑上需要分两步。第 1 步,遍历列表并查找要移除的元素。一旦找到该元素(假设元素在列表中),就必须将其移除。第 1 步与 search 非常相似。从一个指向列表头节点的外部引用开始,遍历整个列表,直到遇到需要移除的元素。由于假设目标元素已经在列表中,因此我们知道循环会在 current 抵达 None 之前结束。这意味着可以在判断条件中使用布尔型变量 found。
当 found 被设为 True 时,current 将指向需要移除的节点。该如何移除它呢?一种做法是将节点包含的值替换成表示其已被移除的值。这种做法的问题是,节点的数量和元素的数量不再匹配。更好的做法是移除整个节点。
为了将包含元素的节点移除,需要将其前面的节点中的 next 引用指向 current 之后的节点。然而,并没有反向遍历链表的方法。由于 current 已经指向了需要修改的节点之后的节点,此时做修改为时已晚。
这一困境的解决方法就是在遍历链表时使用两个外部引用。current 与之前一样,标记在链表中的当前位置。新的引用 previous 总是指向 current 上一次访问的节点。这样一来,当 current 指向需要被移除的节点时,previous 就刚好指向真正需要修改的节点。
代码清单3-22 展示了完整的 remove 方法。第2~3行对两个引用进行初始赋值。注意,current 与其他遍历例子一样,从列表的头节点开始。由于头节点之前没有别的节点,因此 previous 的初始值是 None,如图3-28 所示。布尔型变量 found 再一次被用来控制循环。
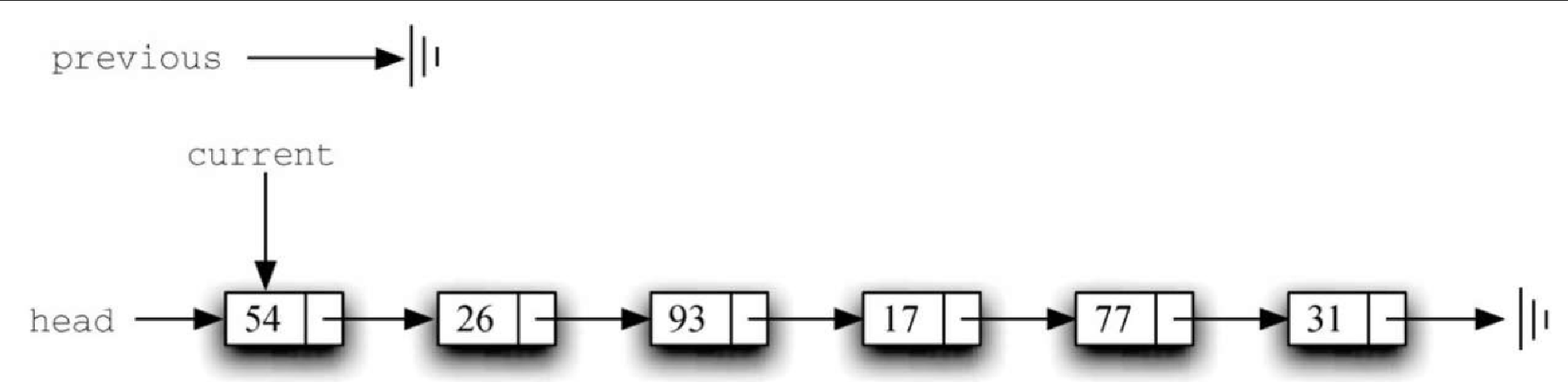 Figure 11. 图3-28 previous和current的初始值代码清单3-22 remove方法
Figure 11. 图3-28 previous和current的初始值代码清单3-22 remove方法def remove(self,item): current = self.head previous = None found = False while not found: if current.getData() == item: found = True else: previous = current current = current.getNext() if previous == None: self.head = current.getNext() else: previous.setNext(current.getNext())第6~7行检查当前节点中的元素是否为要移除的元素。如果是,就设 found 为 True。如果否,则将 previous 和 current 往前移动一次。这两条语句的顺序十分重要。必须先将 previous 移动到 current 的位置,然后再移动 current。这一过程经常被称为 “蠕动”,因为 previous 必须在 current 向前移动之前指向其当前位置。图3-29 展示了在遍历列表寻找包含 17 的节点的过程中,previous 和 current 的移动过程。
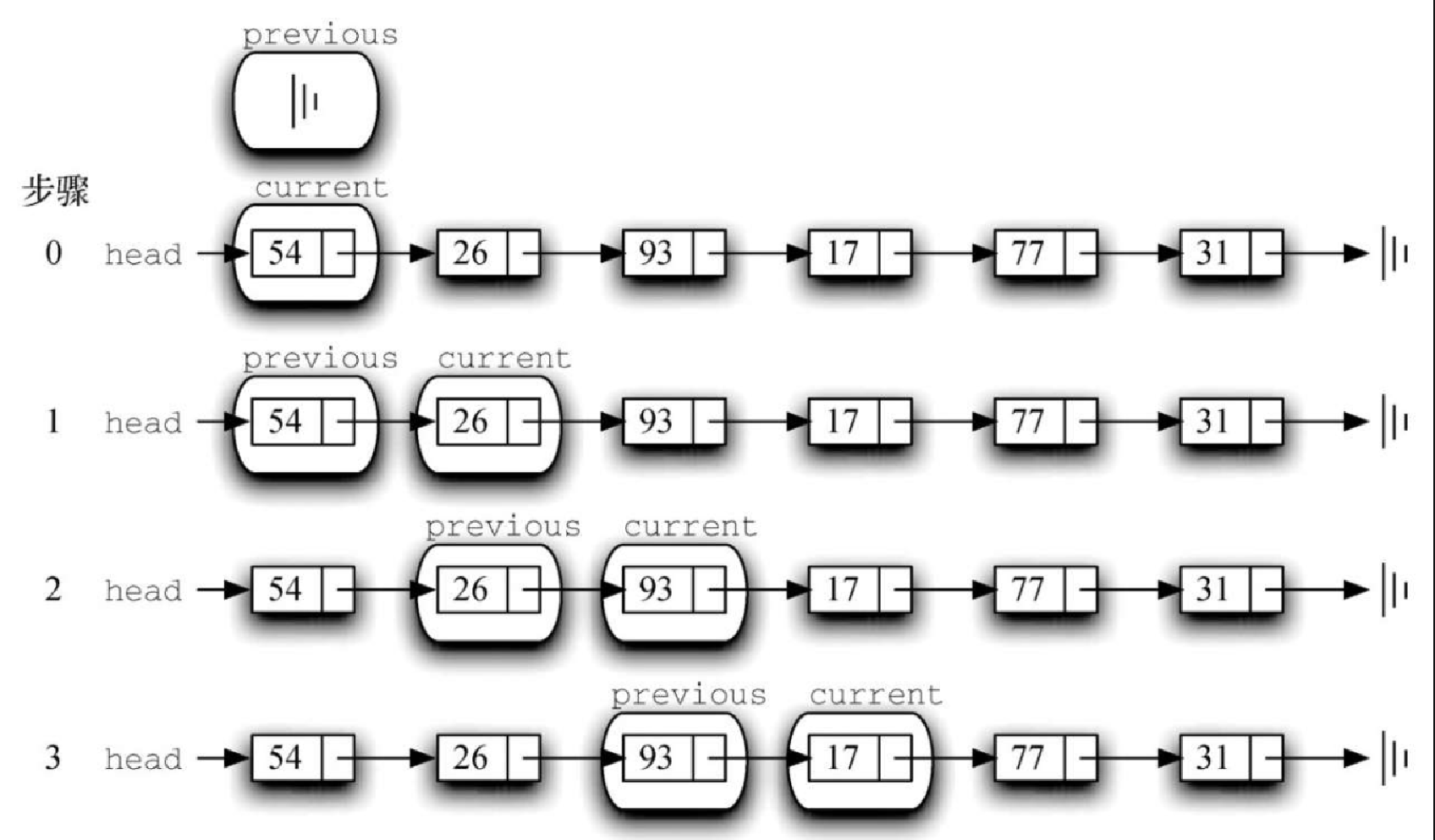 Figure 12. 图3-29 previous 和 current 的移动过程
Figure 12. 图3-29 previous 和 current 的移动过程一旦搜索过程结束,就需要执行移除操作。图3-30 展示了修改过程。有一种特殊情况需要注意:如果被移除的元素正好是链表的第一个元素,那么 current 会指向链表中的第一个节点,previous 的值则是 None。在这种情况下,需要修改链表的头节点,而不是 previous 指向的节点,如图3-31 所示。
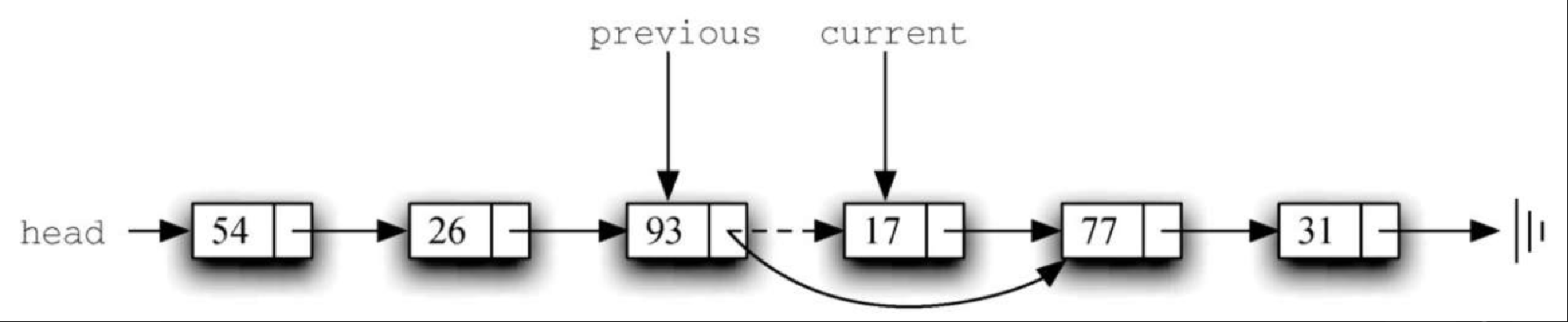 Figure 13. 图3-30 移除位于链表中段的节点
Figure 13. 图3-30 移除位于链表中段的节点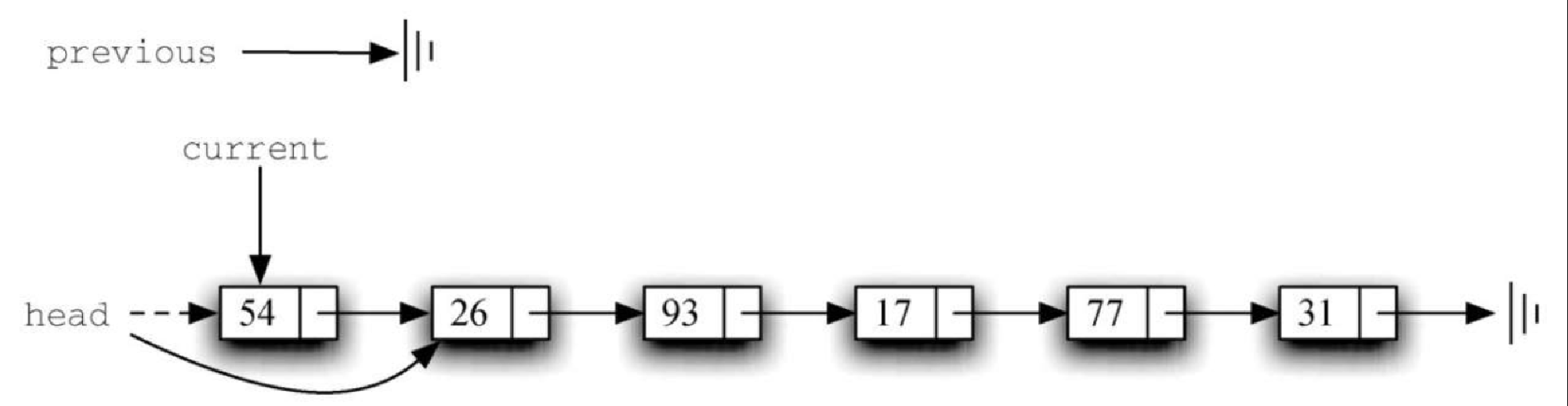 Figure 14. 图3-31 移除链表中的第一个节点
Figure 14. 图3-31 移除链表中的第一个节点第 12 行检查是否遇到上述特殊情况。如果 previous 没有移动,当 found 被设为 True 时,它的值仍然是 None。在这种情况下(第 13 行),链表的头节点被修改成指向当前头节点的下一个节点,从而达到移除头节点的效果。但是,如果 previous 的值不是 None,则说明需要移除的节点在链表结构中的某个位置。在这种情况下,previous 指向了 next 引用需要被修改的节点。第 15 行使用 previous 的 setNext 方法来完成移除操作。注意,在两种情况中,修改后的引用都指向 current.getNext()。一个常被提及的问题是,已有的逻辑能否处理移除最后一个节点的情况。这个问题留给你来思考。
剩下的方法 append、insert、index 和 pop 都留作练习。注意,每一个方法都需要考虑操作是发生在链表的头节点还是别的位置。此外,insert、index 和 pop 需要提供元素在链表中的位置。请假设位置是从 0 开始的整数。
有序列表抽象数据类型
接下来学习有序列表。如果前文中的整数列表是以升序排列的有序列表,那么它会被写作 17, 26, 31, 54, 77, 93。由于 17 是最小的元素,因此它就成了列表的第一个元素。同理,由于 93 是最大的元素,因此它在列表的最后一个位置。
在有序列表中,元素的相对位置取决于它们的基本特征。它们通常以升序或者降序排列,并且我们假设元素之间能进行有意义的比较。有序列表的众多操作与无序列表的相同。
-
OrderedList() 创建一个空有序列表。它不需要参数,且会返回一个空列表。
-
add(item) 假设 item 之前不在列表中,并向其中添加 item,同时保持整个列表的顺序。它接受一个元素作为参数,无返回值。
-
remove(item) 假设 item 已经在列表中,并从其中移除 item。它接受一个元素作为参数,并且修改列表。
-
search(item) 在列表中搜索 item。它接受一个元素作为参数,并且返回布尔值。
-
isEmpty() 检查列表是否为空。它不需要参数,并且返回布尔值。
-
length() 返回列表中元素的个数。它不需要参数,并且返回一个整数。
-
index(item) 假设 item 已经在列表中,并返回该元素在列表中的位置。它接受一个元素作为参数,并且返回该元素的下标。
-
pop() 假设列表不为空,并移除列表中的最后一个元素。它不需要参数,且会返回一个元素。
-
pop(pos) 假设在指定位置 pos 存在元素,并移除该位置上的元素。它接受位置参数,且会返回一个元素。
实现有序列表
在实现有序列表时必须记住,元素的相对位置取决于它们的基本特征。整数有序列表 17, 26, 31, 54, 77, 93 可以用如图 3-32 所示的链式结构来表示。

OrderedList 类的构造方法与 UnorderedList 类的相同。head 引用指向 None,代表这是一个空列表,如代码清单3-23 所示。
class OrderedList:
def __init__(self):
self.head = None因为 isEmpty 和 length 仅与列表中的节点数目有关,而与实际的元素值无关,所以这两个方法在有序列表中的实现与在无序列表中一样。同理,由于仍然需要找到目标元素并且通过更改链接来移除节点,因此 remove 方法的实现也一样。剩下的两个方法,search 和 add,需要做一些修改。
在无序列表中搜索时,需要逐个遍历节点,直到找到目标节点或者没有节点可以访问。这个方法同样适用于有序列表,但前提是列表包含目标元素。如果目标元素不在列表中,可以利用元素有序排列这一特性尽早终止搜索。
举一个例子。图3-33 展示了在有序列表中搜索45的情况。从列表的头节点开始遍历,首先比较 45 和 17。由于 17 不是要查找的元素,因此移向下一个节点,即 26。它也不是要找的元素,所以继续向前比较 31 和之后的 54。由于 54 不是要查找的元素,因此在无序列表中,我们会继续搜索。但是,在有序列表中不必这么做。一旦节点中的值比正在查找的值更大,搜索就立刻结束并返回 False。这是因为,要查找的元素不可能存在于链表后序的节点中。
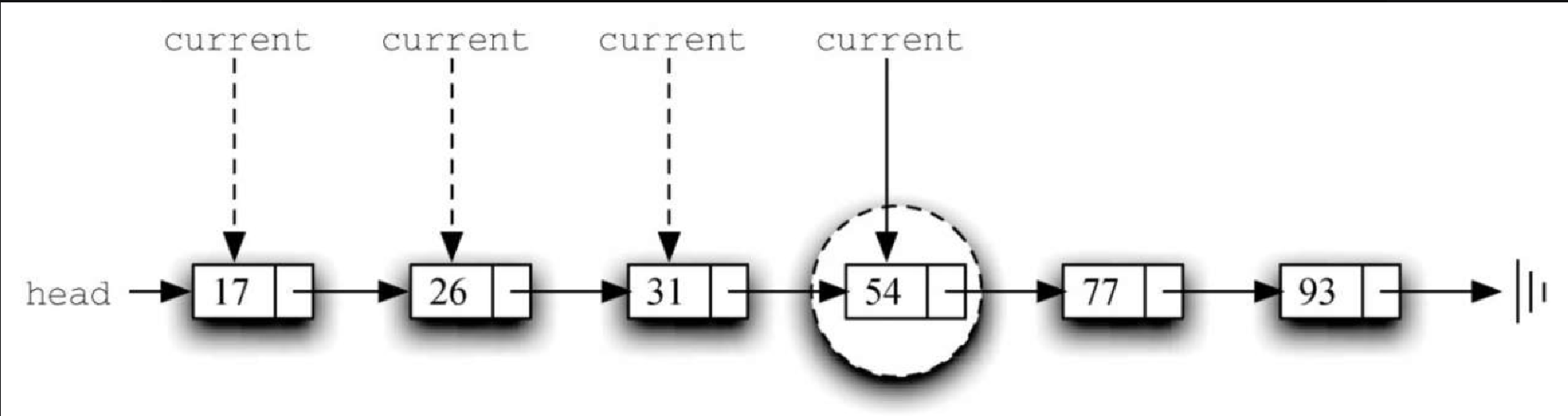
代码清单3-24 展示了完整的 search 方法。通过增加新的布尔型变量 stop,并将其初始化为 False(第4行),可以将上述条件轻松整合到代码中。当 stop 是 False 时,我们可以继续搜索链表(第 5 行)。如果遇到其值大于目标元素的节点,则将 stop 设为 True(第9~10行)。之后的代码与无序列表中的一样。
def search(self,item):
current = self.head
found = False
stop = False
while current != None and not found and not stop:
if current.getData() == item:
found = True
else:
if current.getData() > item:
stop = True
else:
current = current.getNext()
return found需要修改最多的是 add 方法。对于无序列表,add 方法可以简单地将一个节点放在列表的头部,这是最简便的访问点。不巧,这种做法不适合有序列表。我们需要在已有链表中为新节点找到正确的插入位置。
假设要向有序列表 17, 26, 54, 77, 93 中添加 31。add 方法必须确定新元素的位置在 26 和 54 之间。图3-34 展示了我们期望的结果。像之前解释的一样,需要遍历链表来查找新元素的插入位置。当访问完所有节点(current 是 None)或者当前值大于要添加的元素时,就找到了插入位置。在本例中,遇到 54 使得遍历过程终止。
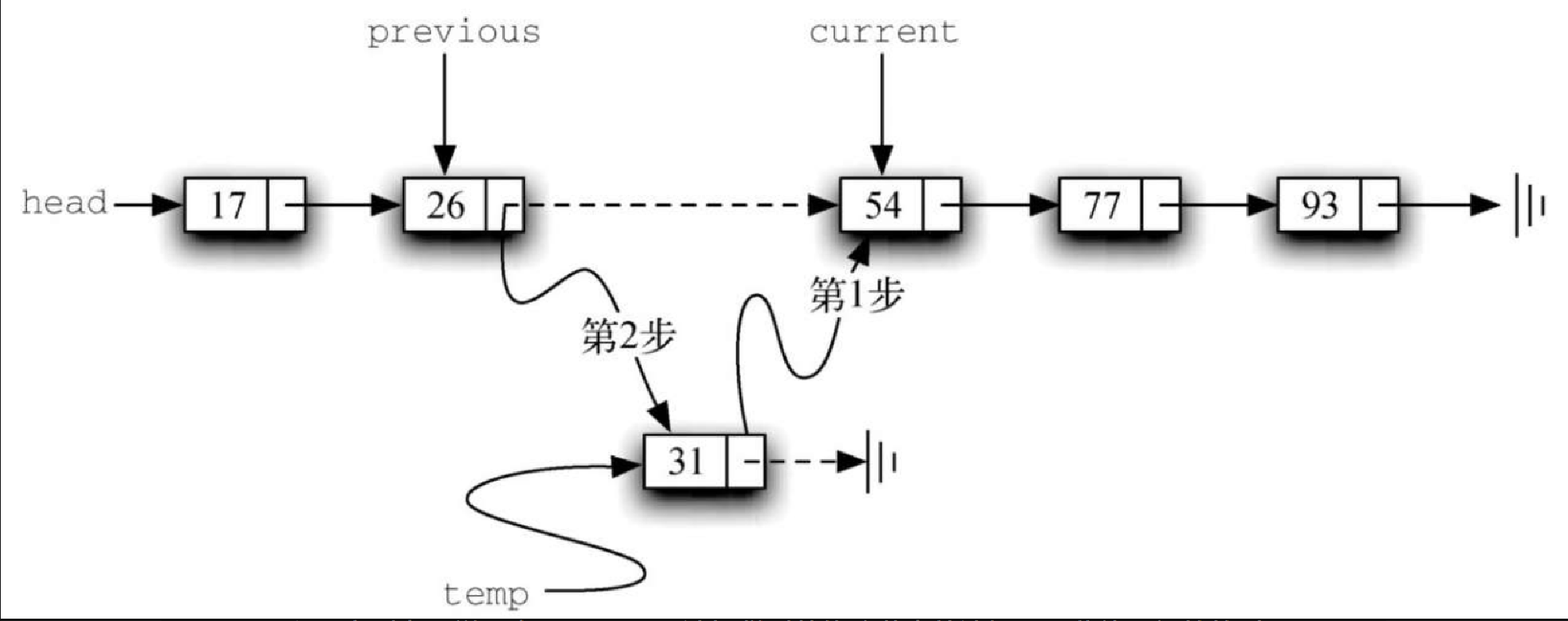
和无序列表一样,由于 current 无法提供对待修改节点的访问,因此使用额外的引用 previous 是十分必要的。代码清单3-25 展示了完整的 add 方法。第2~3行初始化两个外部引用,第9~10行保证 previous 一直跟在 current 后面。只要还有节点可以访问,并且当前节点的值不大于要插入的元素,判断条件就会允许循环继续执行。在循环停止时,就找到了新节点的插入位置。
def add(self,item):
current = self.head
previous = None
stop = False
while current != None and not stop:
if current.getData() > item:
stop = True
else:
previous = current
current = current.getNext()
temp = Node(item)
if previous == None:
temp.setNext(self.head)
self.head = temp
else:
temp.setNext(current)
previous.setNext(temp)一旦创建了新节点,唯一的问题就是它会被添加到链表的开头还是中间某个位置。previous== None(第 13 行)可以提供答案。
剩下的方法留作练习。需要认真思考,在无序列表中的实现是否可用于有序列表。
链表分析
在分析链表操作的时间复杂度时,考虑其是否需要遍历列表。以有 n 个节点的链表为例,isEmpty 方法的时间复杂度是 \$O(1)\$,这是因为它只需要执行一步操作,即检查 head 引用是否为 None。length 方法则总是需要执行 n 步操作,这是因为只有完全遍历整个列表才能知道究竟有多少个元素。因此,length 方法的时间复杂度是 \$O(n)\$。向无序列表中添加元素是 \$O(1)\$,这是因为只是简单地将新节点放在链表的第一个位置。但是,有序列表的 search、remove 以及 add 都需要进行遍历操作。尽管它们平均都只需要遍历一半的节点,但是这些方法的时间复杂度都是 \$O(n)\$。这是因为在最坏情况下,它们都需要遍历所有节点。
我们注意到,本节实现的链表在性能上和 Python 列表有差异。这意味着 Python 列表并不是通过链表实现的。实际上,Python 列表是基于数组实现的。第 8 章将深入讨论。